Introduction
Modern software teams are expected to ship features faster, keep systems stable, recover quickly from failures, and still meet security and compliance needs. That is exactly where the AWS DevOps Engineer – Professional certification helps. It validates real skills in CI/CD, automation, monitoring, governance, incident response, and resilient AWS architecture. If your work involves running production systems on AWS, this certification is designed to prove you can do it in a structured, repeatable way.
Who this master guide is for
Working engineers
If you already build, deploy, or operate systems on AWS, this guide will help you connect daily work to certification-ready skills. You will learn what to focus on, what to ignore, and how to prepare with hands-on practice. The goal is to make your learning time efficient and realistic. This guide also helps you convert your experience into a clean study plan.
Managers and team leads
If you manage engineers, you will benefit because the certification scope works like a checklist for modern delivery and operations maturity. It helps you standardize pipelines, define governance, and improve incident handling. You can use it to find team skill gaps and build training plans. It also improves communication between engineering and leadership.
Software engineers moving into DevOps
If you are coming from development and want DevOps responsibilities, this guide gives a clear transition path. It explains the operational mindset needed for reliability, observability, automation, and safe releases. It also provides step-by-step preparation plans so you can build confidence. Over time, you will start thinking like a production owner, not only a feature builder.
What is AWS DevOps Engineer – Professional?
AWS DevOps Engineer – Professional validates your ability to provision, operate, and manage distributed application systems on AWS. It focuses on building reliable delivery pipelines, automating operational processes, and implementing strong monitoring and governance. Instead of testing only theory, it checks whether you can make sound decisions for real production environments. This certification is best for people who are responsible for shipping and running software in production.
Why this certification matters in real teams
It matches what you do in production
Most teams struggle not because of tools, but because releases are risky, operations are manual, and incidents are handled in panic mode. This certification pushes you toward repeatable automation and safe delivery patterns. It improves how you design pipelines, rollouts, and recovery paths so production becomes predictable. Over time, this reduces downtime and improves release confidence.
It improves collaboration between teams
In many companies, developers, ops, security, and management operate with different priorities and language. This certification creates a shared understanding of CI/CD workflows, monitoring expectations, governance standards, and incident processes. As a result, teams align faster and reduce confusion during high-pressure situations. It also helps leaders understand what “good DevOps” looks like in practice.
It builds long-term technical maturity
Passing the exam is one outcome, but the bigger benefit is improved engineering discipline. You learn how to structure automation, avoid operational drift, and enforce standards at scale. Over time, this reduces outages, speeds up delivery, and creates a culture of clean, auditable systems. This maturity becomes a competitive advantage for teams operating critical services.
Certification table (track, level, audience, prerequisites, skills, order)
| Track | Level | Certification | Who it’s for | Prerequisites | Skills covered | Recommended order |
|---|---|---|---|---|---|---|
| AWS DevOps | Professional | AWS DevOps Engineer – Professional | DevOps, platform, and cloud engineers running AWS workloads in production | AWS operations experience, CI/CD exposure, automation mindset, scripting basics | CI/CD, infrastructure automation, monitoring and logging, governance automation, incident response, HA and DR | 1 |
| DevOps | Professional | DevOps track (provider-led) | Engineers building delivery pipelines and release practices | Git and CI basics, scripting, delivery workflow exposure | CI/CD foundations, automation habits, release strategies, operational readiness | 2 |
| DevSecOps | Professional | DevSecOps track (provider-led) | DevOps and security engineers | DevOps fundamentals and basic security concepts | Secure CI/CD, policy thinking, compliance automation, security controls in pipelines | 3 |
| SRE | Professional | SRE track (provider-led) | Reliability and platform engineers | Monitoring basics, operations mindset | SLIs and SLOs, incident response, reliability patterns, operational excellence | 4 |
| AIOps/MLOps | Professional | AIOps/MLOps track (provider-led) | Ops and ML platform teams | Monitoring and data basics | Automation at scale, anomaly handling patterns, ML lifecycle operations, smarter operations | 5 |
| DataOps | Professional | DataOps track (provider-led) | Data engineers and data platform teams | Pipelines and Git basics | CI/CD for data, quality automation, governance and monitoring for pipelines | 6 |
| FinOps | Professional | FinOps track (provider-led) | Cloud cost owners and engineering leaders | Cloud billing awareness | Cost allocation, optimization workflow, governance, accountability practices | 7 |
What the certification covers
SDLC automation (CI/CD)
This area checks whether you can design and operate end-to-end delivery pipelines on AWS. It is not only about “deploying code,” but also about safe promotions, approvals, and rollback strategies. You should understand how to reduce release risk while increasing deployment speed. Strong CI/CD is measured by reliability and repeatability, not by how many tools you use.
Infrastructure as Code and configuration management
Here, you are evaluated on how you create repeatable environments with automation. The certification expects you to think in templates, versioning, and controlled change. The goal is to reduce drift and ensure systems can be recreated reliably. This is critical when you scale environments across teams and regions.
Monitoring and logging
This part validates whether you can build observability that helps during real incidents. It covers metrics, logs, alerts, event workflows, and audit-friendly practices. Strong monitoring means faster detection, quicker diagnosis, and safer recovery. It also helps teams reduce alert noise and focus on signals that matter.
Policies, governance, and standards automation
This section checks whether you can enforce standards automatically, not manually. It includes governance strategies, compliance validation, and ensuring teams follow required controls. It also includes automation that supports cost optimization and operational efficiency. This is especially important for organizations with audits and regulated environments.
Incident and event response
You’re tested on troubleshooting and restoring systems quickly. More importantly, the focus is on automating responses through events, alerts, and well-defined operational workflows. A mature system should reduce manual firefighting and improve recovery speed. This also helps teams create better on-call experiences and reduce burnout.
High availability and disaster recovery (HA/DR)
This validates your ability to design systems that keep running through failures and recover from major outages. You should understand multi-AZ vs multi-region decisions, recovery objectives, and failure points. Strong HA/DR is about planning and automation, not luck. The best teams treat recovery as a tested capability, not a document.
AWS DevOps Engineer – Professional
What it is
This certification validates that you can run real-world delivery and operations on AWS. It proves you can build CI/CD pipelines, automate operational tasks, implement monitoring and governance, and design reliable systems. It focuses on practical decision-making for production environments. In short, it verifies you can ship and operate software at professional scale.
Who should take it
- DevOps engineers who create pipelines and manage deployments on AWS and want professional-level validation.
- Platform engineers who build standardized templates, self-service platforms, and guardrails for teams.
- Cloud engineers and SREs who handle incidents, reliability, monitoring, and production readiness.
- Engineering managers who want structured understanding of release risk, governance maturity, and operational automation.
Skills you’ll gain
- CI/CD pipeline design on AWS
You’ll learn how to build pipelines that are repeatable, auditable, and safe. You’ll understand how to structure environments, approvals, and promotions across stages. You’ll also learn how to select rollout strategies that reduce downtime and reduce deployment fear. This helps teams release more often with less risk. - Security controls and compliance automation
You’ll learn how to move security checks into your delivery pipeline instead of doing them late. This includes governance thinking, control validation, and consistent enforcement across environments. The result is fewer last-minute surprises and smoother release approvals. It also reduces security gaps caused by manual processes. - Monitoring, logging, and operational visibility
You’ll build skills in creating metrics, logs, dashboards, and alert flows that help during real incidents. You’ll learn how to reduce noise and create alerts that drive action. You’ll understand how to diagnose issues faster and improve recovery speed. Strong observability also supports audit and compliance reporting. - High availability and resilience planning
You’ll learn how to design for failure by default and build recovery into the architecture. This includes availability patterns, scaling strategies, and redundancy planning. You’ll improve your ability to find single points of failure and remove them. This gives you confidence in operating business-critical systems. - Operational automation and event-driven actions
You’ll learn how to reduce manual operations using automation and event-driven patterns. This includes automating common responses like scaling actions, self-healing workflows, and controlled rollback triggers. It helps teams spend less time firefighting and more time improving systems. Over time, operational stability improves and incidents reduce.
Real-world projects you should be able to do after it
- Build a production-style CI/CD pipeline with safe rollouts
You should be able to design a pipeline that supports multiple stages and environment promotions. You should be able to deploy using safe rollout methods and apply rollback or fail-safe behavior. The pipeline should be stable enough for frequent releases without panic. Your pipeline should be auditable and repeatable across teams. - Automate governance checks inside the pipeline
You should be able to implement quality gates that prevent risky changes from moving forward. This includes automated checks for standards and compliance needs. The goal is to make governance consistent instead of depending on manual reviews alone. It also reduces last-minute release delays caused by missing controls. - Implement centralized monitoring and logging for multiple environments
You should be able to collect logs and metrics across dev, staging, and production using a clear strategy. Alerts should be meaningful, not noisy, and should map to actions. You should support audit needs with consistent logging practices and retention thinking. This helps teams respond faster and learn from incidents. - Design HA/DR and validate recovery with automation
You should be able to plan for failures, define recovery objectives, and implement a practical recovery approach. You should also be able to test DR scenarios instead of only writing them down. This creates real confidence during outages and reduces recovery time. Mature teams automate DR testing to avoid surprises. - Create event-driven auto-healing for common failures
You should be able to detect common failure patterns and trigger corrective actions automatically. This might include restarting components, scaling capacity, or rolling back changes. The goal is controlled recovery instead of manual firefighting. Auto-healing reduces downtime and improves customer experience.
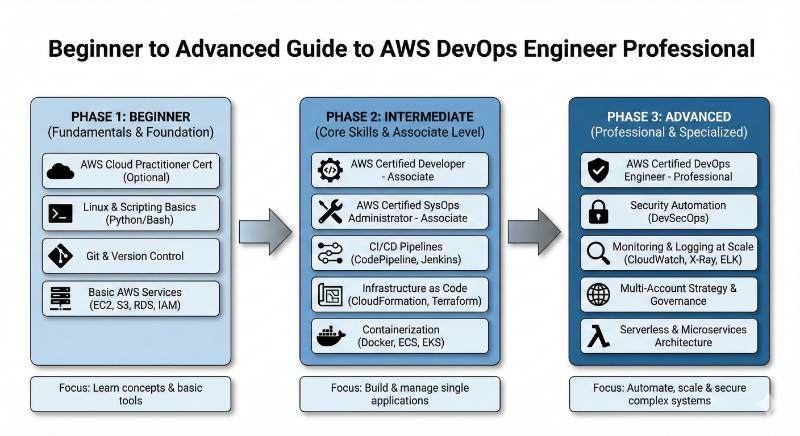
Preparation plan
7–14 days (fast revision path)
This path is for people already working with AWS delivery and operations. The focus is on revising major domains, converting knowledge into checklists, and practicing realistic scenarios. You should complete at least one end-to-end pipeline workflow, one observability setup, and one HA/DR review. Use practice questions mainly to discover weak areas and fix them quickly.
30 days (balanced path)
This path fits most working engineers who have experience but need structured learning. Each week should focus on one domain: CI/CD, infrastructure automation, monitoring and incident response, then governance plus resilience. The goal is to build skills steadily without burnout while doing hands-on practice. By the end, you should have notes, templates, and one portfolio-style project.
60 days (career transition path)
This is best if you are shifting into AWS DevOps or want strong confidence before the exam. Month one should build foundations and hands-on exposure in each domain. Month two should focus on deeper practice, trade-offs, and mock incident drills. By the end, you should be able to explain design decisions clearly instead of guessing.
Common mistakes
- Memorizing services without understanding trade-offs
Many learners can name tools but cannot choose the right approach under constraints like cost, risk, and recovery goals. The certification rewards decision-making, not memory. Train yourself to explain why an option is better, not just what it is. Use scenario practice to build this skill. - Building pipelines without rollback and safety
A pipeline is not mature if failure means downtime or manual rescue. Safe deployments and rollback planning are core to professional DevOps. Always practice failure handling as part of pipeline design, not as an afterthought. A stable release process is a major focus of this certification. - Treating monitoring as dashboards only
Dashboards are not enough if alerts are noisy and incidents take too long to diagnose. Monitoring must support fast detection and faster action. Practice turning signals into clear alert rules and linking them to runbooks. This improves both exam readiness and real operations maturity. - Ignoring governance and compliance until the end
In real teams, governance is part of daily delivery and audits. If you add controls late, you create rework and delays. Make compliance and standards part of the pipeline design from the beginning. This leads to smoother releases and fewer last-minute blockers. - Underestimating HA/DR architecture decisions
Many outages happen due to weak redundancy and untested recovery planning. Multi-AZ and multi-region decisions need clear reasoning, not guesses. Practice mapping architecture decisions to recovery objectives and failure scenarios. Strong HA/DR thinking improves both exam results and production reliability.
Best next certification after this
After passing, your next step should match your role and team needs. If you want deeper delivery maturity, stay focused on DevOps and platform engineering patterns. If you want security leadership, move toward DevSecOps so you can automate governance and compliance end-to-end. If you want to scale processes across teams, grow into leadership and platform strategy so you can standardize how engineering delivers software.
Choose your path (6 learning paths)
1) DevOps path (delivery first)
This path is for engineers who want faster release cycles without breaking production. You focus on CI/CD structure, release strategies, automation quality gates, and repeatable deployments. The goal is to reduce lead time while keeping change risk low. It works well when teams struggle with slow releases or fear deployments.
2) DevSecOps path (secure by default)
This path is for teams where security reviews happen too late and block releases. You focus on automating security controls, governance checks, and compliance validation inside delivery pipelines. The goal is to make security predictable, repeatable, and scalable. It fits organizations with strict compliance needs and audit pressure.
3) SRE path (reliability first)
This path is for engineers who manage outages and on-call responsibilities. You focus on monitoring strategy, alert quality, incident response, and resilience patterns like auto-healing and redundancy. The goal is to reduce downtime and improve recovery speed. It fits teams running critical services with high availability needs.
4) AIOps/MLOps path (automation at scale)
This path is for teams where manual operations does not scale with growth. You focus on event-driven operations, automation workflows, and smarter detection patterns that reduce noise. If ML systems are part of your stack, you add lifecycle stability and monitoring thinking. The goal is fewer repetitive tasks and faster response to incidents.
5) DataOps path (pipeline reliability for data)
This path is for data engineering teams where pipelines break often and data trust is low. You focus on delivery discipline for data workflows: versioning, testing, quality checks, observability, and governance. The goal is stable pipelines and reliable outputs. It fits teams building analytics platforms, reporting, or data products.
6) FinOps path (cost + efficiency)
This path is for organizations where cloud costs rise but accountability is unclear. You focus on cost visibility, optimization workflows, and governance habits that align engineering and finance. The goal is to control spend without slowing delivery. It fits platform leaders and teams managing large AWS usage.
Role → Recommended certifications mapping
| Role | What they care about most | Recommended certifications direction |
|---|---|---|
| DevOps Engineer | CI/CD speed, safe deployments, automation | Start with AWS DevOps Engineer – Professional, then move into DevSecOps for secure delivery maturity |
| SRE | Reliability, monitoring quality, incident response | Start with AWS DevOps Engineer – Professional, then strengthen SRE practices and operational excellence |
| Platform Engineer | Standard templates, guardrails, self-service | Start with AWS DevOps Engineer – Professional, then combine DevOps and SRE thinking for platform maturity |
| Cloud Engineer | AWS operations, governance, scalability | Start with AWS DevOps Engineer – Professional, then add FinOps and governance maturity |
| Security Engineer | Compliance automation, controlled releases | Start with AWS DevOps Engineer – Professional, then deepen DevSecOps security automation |
| Data Engineer | Data pipeline stability and reliability | Start with AWS DevOps Engineer – Professional, then add DataOps for pipeline discipline and quality |
| FinOps Practitioner | Spend visibility, optimization, accountability | Start with AWS DevOps Engineer – Professional, then deepen FinOps governance and optimization |
| Engineering Manager | Predictability, risk reduction, scaling | Use the certification scope as a team maturity checklist, then move toward leadership and platform strategy |
Next certifications to take (3 options)
Same track (go deeper)
Stay focused on AWS DevOps maturity and strengthen advanced automation patterns. Deepen your practice in CI/CD strategies, governance enforcement, observability decision-making, and resilience planning. This path is best when your current role is AWS-heavy and you want to become a go-to person for delivery systems. It also improves your ability to lead complex production improvements.
Cross-track (expand capability)
Choose a cross-track direction based on your team gaps: security for compliance automation, SRE for reliability and incident maturity, or DataOps and FinOps based on platform needs. This path is best when you want broader impact beyond pipelines. It helps you handle security, reliability, and cost together. Over time, it makes you more valuable across multiple teams.
Leadership (scale teams and processes)
If your role involves ownership of outcomes, move toward leadership and platform maturity. Focus on building standards, reusable templates, measurement practices, and incident governance. This path is best when you want to guide multiple teams, reduce risk, and improve delivery predictability at scale. It also prepares you for architecture and management responsibilities.
Training + certification support institutions (top institutions)
DevOpsSchool
DevOpsSchool provides structured training aligned with AWS DevOps Engineer – Professional scope, covering CI/CD automation, monitoring and logging, governance, incident response, and resilient architecture. It is helpful for learners who want a guided plan with hands-on practice and exam-focused revision. It fits working professionals who need a clear weekly roadmap. It also supports structured learning for both engineers and managers.
Cotocus
Cotocus is useful if you prefer practical mentoring and real implementation thinking. It supports learners who want to connect concepts with actual pipelines and operational workflows. It works best when you learn through projects and want clear feedback on design choices. It helps build confidence in production-style decisions.
Scmgalaxy
Scmgalaxy is suitable for systematic learners who want step-by-step coverage and structured preparation. It helps reinforce fundamentals and supports consistent revision, especially when you want discipline in automation and operations. It is a good option for learners who want a guided learning rhythm. It also supports structured practice plans for busy professionals.
BestDevOps
BestDevOps is helpful for building practical DevOps habits like automation-first workflows and production readiness thinking. It supports learners who want scenario-based learning and repeatable checklists. It fits people who want to build confidence through hands-on practice and common-case troubleshooting. It is useful for improving day-to-day operational skills.
devsecopsschool
devsecopsschool supports learners who want to specialize in secure delivery and compliance automation. It helps shift security earlier into CI/CD workflows and build consistent governance controls. This is a strong next step when compliance and audits are important in your organization. It supports building secure pipeline habits that scale.
sreschool
sreschool is designed for reliability-focused learning, especially around monitoring strategy, incident response, and resilience patterns. It supports engineers who want to reduce downtime and improve recovery speed through operational maturity. It complements AWS DevOps by strengthening reliability engineering thinking. It is especially helpful for on-call and production-heavy teams.
aiopsschool
aiopsschool supports teams that want to reduce manual operations and scale response through automation. It is useful when alert noise is high or operations are reactive. It helps you build smarter patterns for detection, correlation, and response. This is valuable in high-scale systems where manual ops cannot keep up.
dataopsschool
dataopsschool is useful if you work with data platforms and want software-grade delivery and stability for pipelines. It supports learning around quality automation, governance, and observability for data workflows. It is valuable when broken pipelines and inconsistent outputs are common problems. It helps teams improve trust in data products.
finopsschool
finopsschool supports cloud cost governance and continuous optimization habits. It helps teams build accountability, visibility, and automation for spend management. It is useful when cloud bills rise and you need repeatable cost control without slowing engineering. It complements AWS DevOps by adding financial discipline to cloud operations.
Testimonials
- Amit (DevOps Engineer)
“I used to treat deployments like a stressful event. After structured preparation, I improved rollout planning and built safer rollback paths. It helped me make releases predictable and reduced panic during production changes. My confidence improved because I could explain my deployment decisions clearly.” - Neha (Platform Engineer)
“The biggest change was how I designed pipelines as reusable templates for teams. I started building guardrails and standards instead of one-off solutions. That made adoption smoother and reduced support load for our platform team. It also improved developer experience across projects.” - Rahul (SRE)
“I learned how to connect monitoring signals to real actions instead of just dashboards. It improved how I handle on-call incidents and reduced time to recover. The focus on automation helped us avoid repeating the same manual fixes. Our incident response became calmer and more structured.” - Priya (Engineering Manager)
“This gave me a structured lens to review delivery risk, governance checks, and reliability posture. I could ask better questions and guide the team toward measurable improvements. It also helped me align stakeholders on priorities. The outcome was smoother releases and fewer operational surprises.”
FAQs
1) Is AWS DevOps Engineer – Professional difficult?
Yes, it is considered challenging because it expects practical judgment, not just definitions. You must understand CI/CD decisions, monitoring strategy, governance controls, and resilience trade-offs. If you prepare with hands-on scenarios, the difficulty becomes manageable. The key is to practice decision-making, not memorization.
2) How long does preparation usually take?
If you already work in AWS DevOps daily, 7–14 days of focused revision can work. For most professionals, 30 days is a balanced plan with steady practice. If you’re transitioning into DevOps, 60 days gives time to build confidence and projects. Your timeline should match your current exposure to AWS operations.
3) Do I need coding skills?
You don’t need advanced programming, but you do need automation comfort. You should be able to read and write scripts, understand pipeline definitions, and work with configuration templates. The certification expects an automation mindset, not manual operations. If you can automate repetitive tasks, you’re on the right track.
4) Do I need prior AWS experience?
Yes, hands-on AWS experience is strongly expected. The scope assumes you have worked with AWS systems and operational processes. Without AWS exposure, scenario questions feel abstract and hard to answer confidently. Real experience helps you understand trade-offs and operational impact.
5) Is this useful for managers?
Yes, because the domains align with modern delivery maturity: release safety, governance, monitoring, and incident readiness. Even managers who don’t take the exam can use the scope to review team gaps. It also helps align engineering and business expectations. Managers gain a stronger framework for evaluating risk.
6) What topics matter most?
CI/CD automation, monitoring and logging strategy, governance and compliance automation, incident response workflows, and HA/DR decisions are the core areas. You should be able to justify design choices under constraints. The exam rewards “why this solution” thinking. Build your prep around scenarios and production patterns.
7) What is the best sequence before this certification?
Start with CI/CD fundamentals, then infrastructure automation, then observability and incident response, and finally governance and HA/DR. This sequence matches how real systems are built and stabilized. It also prevents learning gaps that cause confusion later. When fundamentals are strong, professional-level topics become easier.
8) Will this help career growth?
It often helps because it signals production-ready capability on AWS. It supports roles like DevOps Engineer, Platform Engineer, Cloud Engineer, and SRE. The real benefit is the operational discipline you build, which shows up in work outcomes. Teams trust engineers who can automate, monitor, and recover systems.
9) What kind of projects should I build?
Build one complete pipeline project with safe deployments, one observability project with alerts and runbooks, and one HA/DR planning project with testable recovery steps. These projects make concepts real and strengthen confidence. They also become portfolio assets. Practical projects make your learning faster and deeper.
10) Do I need deep networking knowledge?
You should understand basic cloud networking concepts and how they impact reliability and security. You don’t need to be a specialist, but you must avoid wrong design assumptions. Focus on operational impact rather than only theory. Networking knowledge becomes important when designing production architectures.
11) How do I avoid wasting time during prep?
Don’t chase every AWS service or random topic. Stay aligned with the certification domains and practice realistic scenarios. Build checklists and revise them, because the exam tests structured thinking. Use practice questions to expose weak areas, not as your only study method. The best prep is hands-on plus revision.
12) What is the biggest reason people fail?
The most common reason is lack of hands-on practice. Many learners know terms but cannot choose the best option in a real situation. Practice building, breaking, and recovering systems so your answers become confident and fast. The exam rewards people who understand operational trade-offs.
FAQs on AWS DevOps Engineer – Professional
Q1) What does the certification validate in one line?
It validates that you can deliver and operate AWS systems using automation-first DevOps practices. This includes safe pipelines, monitoring discipline, governance thinking, and resilience planning. It reflects production readiness rather than theory. If you can run systems calmly in production, this certification matches that mindset.
Q2) What should I master first: CI/CD or monitoring?
Start with CI/CD because it defines your delivery flow and release strategy. Then add monitoring and logging so you can measure release impact and handle incidents quickly. When both are strong, production becomes predictable and easier to operate. Good teams treat monitoring as part of delivery, not separate.
Q3) Do deployment strategies really matter?
Yes, because safe rollouts reduce downtime and change risk. Understanding controlled release patterns and rollback readiness is essential for professional DevOps. It shows you can ship changes without breaking user experience. Many real outages happen due to weak rollout planning.
Q4) How important is governance and compliance?
It is very important because modern organizations need auditability and consistent controls. The certification scope includes automating security controls and compliance validation. If you ignore governance, your pipelines may work but won’t be acceptable in regulated environments. Governance also reduces operational drift over time.
Q5) What’s the best way to practice incident response?
Practice failures intentionally: trigger a bad release, observe signals, rollback, and document the runbook. Then automate at least one recovery action so you reduce future manual work. Incident practice builds speed, calmness, and confidence. Strong incident response comes from repetition, not luck.
Q6) Should I focus on HA and DR separately?
Yes, because HA is about staying available during component failure, while DR is about recovery after a bigger event. The certification expects you to make architecture decisions based on recovery needs. You should be able to explain why an option fits a scenario. Mature teams treat recovery as a tested capability.
Q7) How do I know I’m ready?
You are ready when you can explain pipeline design choices clearly, implement monitoring and alert strategies, enforce basic governance controls, and describe HA/DR planning confidently. If you can solve scenario questions without guessing, you’re close. Your projects should look production-style, not demo-style.
Q8) What should I do right after passing?
Pick a direction based on your role: DevSecOps for secure delivery, SRE for reliability leadership, or FinOps for cost governance. Build a small roadmap and apply improvements in your current team. Passing is a starting point—real value comes from applying what you learned. The best engineers turn certification learning into team outcomes.
Conclusion
AWS DevOps Engineer – Professional is a strong certification for engineers who build pipelines, manage deployments, and operate production systems on AWS. It rewards practical thinking: safe releases, measurable systems, automated governance, and resilient architecture. If you prepare with real projects and structured revision, you will gain skills that improve daily work, not just exam scores. Use the learning paths to pick a direction and keep building maturity step by step.