1. Introduction & Overview
❓ What is a Data Catalog?
A Data Catalog is an organized inventory of data assets across your systems. It uses metadata to help data professionals discover, understand, trust, and govern data.

Think of it like a library catalog: you don’t read all books, but you need to know where to find the right one, who wrote it, and whether it’s relevant.
🕰️ History or Background
- Originated in data governance and business intelligence environments.
- Evolved with Big Data, AI, and cloud-native architectures.
- Modern catalogs integrate automated metadata discovery, lineage tracking, and security controls.
🚀 Why is it Relevant in DevSecOps?
In DevSecOps, security, development, and operations collaborate across data workflows. A data catalog helps by:
- Improving data discoverability and access control
- Supporting secure automation pipelines
- Enabling auditing, lineage, and governance
- Aligning with privacy and compliance (e.g., GDPR, HIPAA)
2. Core Concepts & Terminology
📖 Key Terms and Definitions
| Term | Definition |
|---|---|
| Metadata | Data that describes other data (e.g., schema, owner, tags) |
| Data Lineage | Visualization of data flow from source to consumption |
| Data Stewardship | Managing the quality, usage, and security of data |
| Data Governance | Policies and processes ensuring data integrity & compliance |
| Tagging | Classifying data with meaningful labels |
| Role-based Access Control (RBAC) | Restricting access based on user roles |
🔄 How it Fits into the DevSecOps Lifecycle
| DevSecOps Phase | Role of Data Catalog |
|---|---|
| Plan | Know existing data assets and definitions |
| Develop | Embed secure data access in code |
| Build/Test | Enforce validation, masking policies in CI/CD |
| Release | Publish versioned, well-documented datasets |
| Operate | Monitor usage, data quality, and access logs |
| Monitor | Trigger alerts on drift, unauthorized access, or compliance issues |
3. Architecture & How It Works
🧱 Key Components
- Metadata Extractor: Connects to data sources and pulls schema, tags, owners.
- Data Lineage Engine: Tracks data flows between pipelines.
- Search & Discovery Interface: UI/CLI/API to query datasets.
- Governance Layer: Applies policies, classification, RBAC.
- Integration Connectors: Syncs with CI/CD, GitOps, or cloud storage.
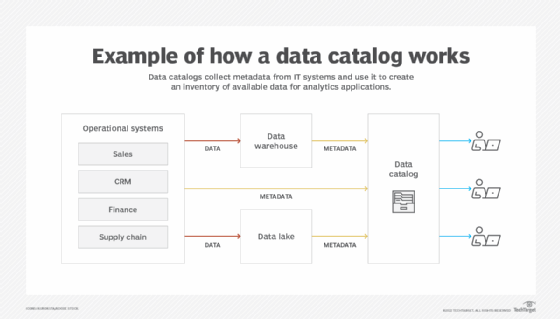
⚙️ Internal Workflow
- Ingest metadata from source systems (DBs, data lakes, warehouses)
- Classify and tag sensitive data
- Define policies for access, masking, retention
- Expose APIs/UI for teams to discover and govern
- Track changes & lineage over time
- Audit usage and access logs
🧭 Architecture Diagram (Described)
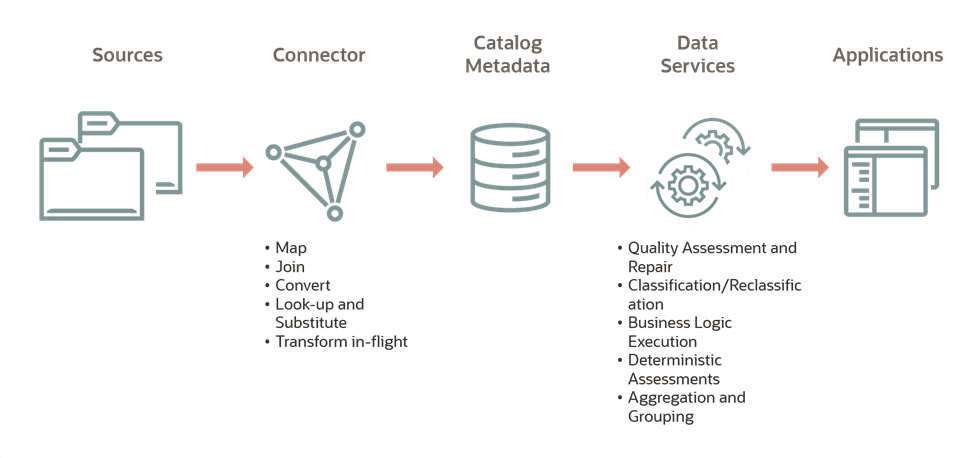
Text-Based Representation:
+------------------+ +--------------------+ +------------------+
| Data Sources | ---> | Metadata Extractor | ---> | Metadata Store |
| (DB, S3, etc.) | +--------------------+ +--------+---------+
|
+----v-----+
| Lineage |
| Engine |
+----+-----+
|
+----v-----+
| Governance|
| Policies |
+----+-----+
|
+----v-----+
| UI/API |
+----------+
🔌 Integration Points
| Tool/Platform | Integration Use |
|---|---|
| CI/CD (Jenkins, GitLab CI) | Validate data schema changes automatically |
| Terraform/Ansible | Provision catalog components as code |
| Cloud Providers (AWS Glue, Azure Purview, GCP Dataplex) | Native catalog services |
| Security Scanners (e.g., Snyk, SonarQube) | Scan metadata or data flows for risks |
4. Installation & Getting Started
⚙️ Prerequisites
- Docker or Kubernetes cluster
- Python 3.x / Java (depends on the tool)
- Access to your data source (e.g., PostgreSQL, Snowflake)
🛠️ Hands-on: OpenMetadata (Example)
# Step 1: Clone the repo
git clone https://github.com/open-metadata/OpenMetadata.git
cd OpenMetadata
# Step 2: Start services
docker-compose -f docker-compose.yml up -d
# Step 3: Access UI
# Visit http://localhost:8585
# Step 4: Connect a Data Source
# Use UI to integrate PostgreSQL, S3, or others
5. Real-World Use Cases
✅ Example 1: Secure Data Access in CI/CD
- Use Data Catalog API in Jenkins to check data compliance before deployment
- Automatically block pipeline if sensitive columns (e.g., PII) are missing tags
✅ Example 2: Financial Auditing
- Track lineage of financial reports from raw ingestion to dashboards
- Store access logs for each user touching sensitive datasets
✅ Example 3: Health Data Governance
- In hospitals, automatically classify patient data
- Use RBAC to allow access only to doctors, block interns or data scientists
✅ Example 4: Cloud Migration Inventory
- Before migrating to AWS, catalog all assets from on-prem
- Tag redundant/unclassified data to decide what to move or archive
6. Benefits & Limitations
✅ Benefits
- ✅ Central visibility of data assets
- ✅ Enforces security policies (e.g., RBAC, classification)
- ✅ Promotes reuse of trusted datasets
- ✅ Aids in compliance (GDPR, HIPAA)
- ✅ Supports automation in DevSecOps
⚠️ Limitations
- ❌ Initial setup and integration may be complex
- ❌ Requires strong data culture and stewardship
- ❌ Metadata extraction may fail with proprietary sources
- ❌ Real-time tracking may be limited in some tools
7. Best Practices & Recommendations
🔒 Security & Compliance
- Use encryption and IAM for metadata storage
- Set up RBAC with fine-grained controls
- Enable audit logging and anomaly detection
⚙️ Performance & Automation
- Automate metadata ingestion on each pipeline commit
- Use Terraform or GitOps to define catalog policies as code
📋 Maintenance
- Schedule metadata refresh jobs
- Assign data owners/stewards
- Periodically review stale or redundant assets
8. Comparison with Alternatives
| Feature | OpenMetadata | AWS Glue | Apache Atlas | Collibra |
|---|---|---|---|---|
| Open Source | ✅ | ❌ | ✅ | ❌ |
| Cloud-Native | ✅ | ✅ | ❌ | ✅ |
| Lineage Tracking | ✅ | Limited | ✅ | ✅ |
| Integration Ease | High | Medium | Medium | Low |
| Pricing | Free | Pay-as-you-go | Free | Enterprise |
📌 When to Choose Data Catalog?
- Choose OpenMetadata or Apache Atlas for open-source, DevSecOps-friendly use.
- Choose AWS Glue if you’re tightly coupled with AWS.
- Choose Collibra for enterprise-grade governance with rich business rules.
9. Conclusion
🧠 Final Thoughts
A Data Catalog is no longer just a “nice to have” — it’s essential for secure, compliant, and productive DevSecOps workflows. It ensures everyone speaks the same data language while respecting governance and privacy.
🔮 Future Trends
- AI-powered metadata classification
- Real-time lineage across microservices
- Integration with LLMs and observability tools
🔗 Useful Links
- 🌐 OpenMetadata: https://open-metadata.org
- 📘 Apache Atlas: https://atlas.apache.org
- 🧠 AWS Glue Catalog: https://aws.amazon.com/glue/
- 🧑🤝🧑 Data Catalog Community: https://datahubproject.io/community
Category: