📌 Introduction & Overview
What is Great Expectations?
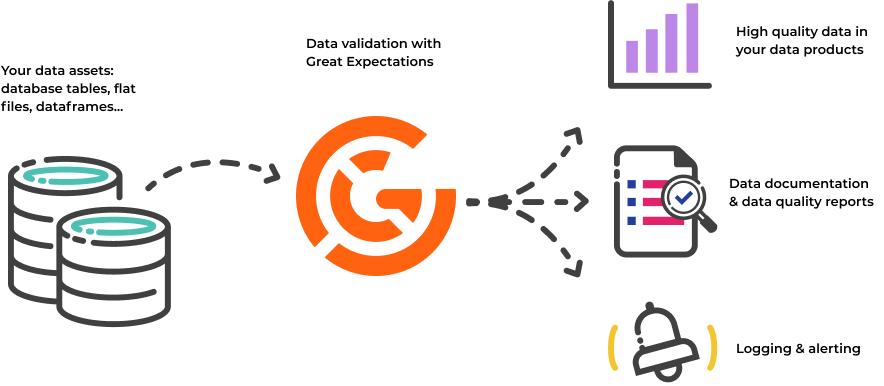
Great Expectations (GE) is an open-source Python-based data validation, documentation, and profiling framework. It helps teams define, test, and document expectations about data as it flows through pipelines, ensuring that data quality issues are detected early and automatically
History or Background
- Developed by Superconductive, GE originated as an internal tool for validating data in machine learning pipelines.
- Became open source in 2018.
- GE has since evolved to support data observability, test-driven development for data, and compliance checks.
Why is it Relevant in DevSecOps?
In DevSecOps, the goal is to embed security and quality at every phase of the software development lifecycle. GE plays a critical role in the “Sec” and “Ops” of DevSecOps by:
- Validating data quality before it’s used in production.
- Supporting data compliance and governance standards like GDPR, HIPAA.
- Enabling automated testing and CI/CD data validation, just like unit tests for code.
🔑 Core Concepts & Terminology
Key Terms and Definitions
| Term | Definition |
|---|---|
| Expectation | A declarative rule that data should follow (e.g., column values not null) |
| Data Context | A configuration environment to run GE workflows |
| Suite | A group of expectations applied to a dataset |
| Checkpoint | A specific configuration to run suites on datasets |
| Validation Result | The outcome of applying an expectation suite to data |
| Data Docs | Auto-generated documentation for validation results |
How It Fits Into the DevSecOps Lifecycle
GE integrates naturally into these phases:
- Development: Define expectation suites during pipeline creation.
- Security: Validate PII, encryption, or data masking.
- CI/CD: Automate data tests in CI workflows using tools like GitHub Actions.
- Operations: Continuously monitor data quality in production pipelines.
🏗️ Architecture & How It Works
Components and Internal Workflow
- Expectation Suites: YAML or JSON files with rules.
- Batch: A unit of data (e.g., a file, database table) on which expectations are applied.
- Checkpoint: YAML configuration to run expectations on a data batch.
- Data Docs: HTML-based validation reports.
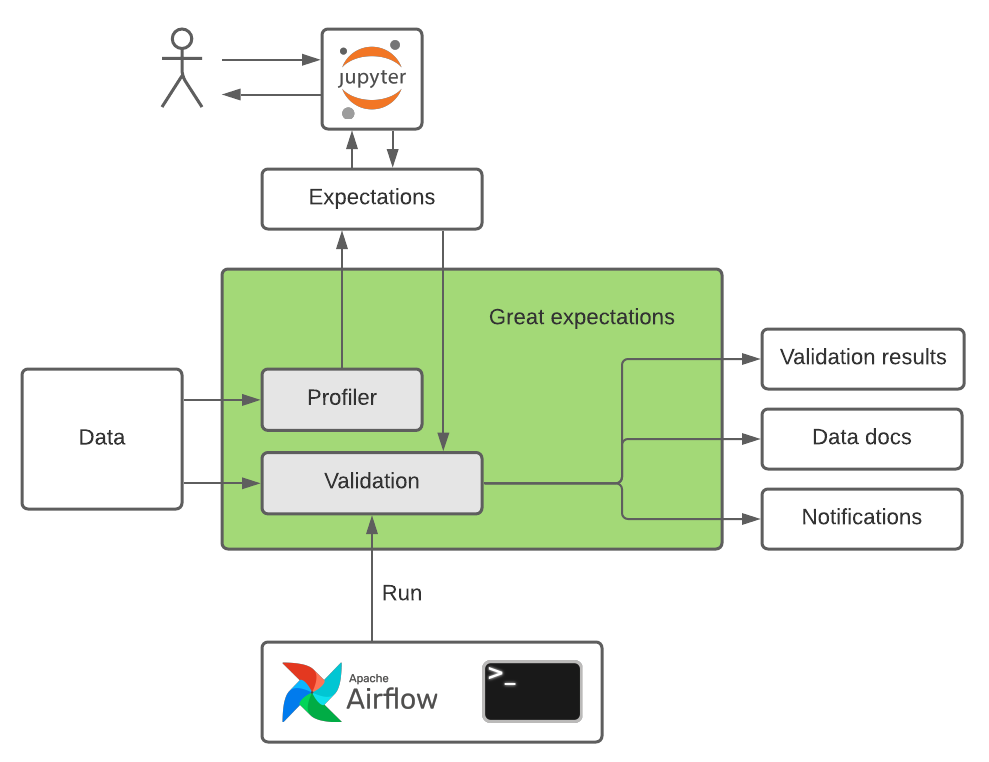
Architecture Diagram (Described)
User/CI Trigger
|
v
[ Data Context ]
|
|---> Reads Expectation Suite
|---> Loads Data Batch (CSV, DB, etc.)
|---> Executes Checkpoint
|
v
[ Validation Results ]
|
v
[ Data Docs HTML Report ]
Integration Points with CI/CD and Cloud
| Tool | Integration Strategy |
|---|---|
| GitHub Actions | Add GE checks as jobs in .github/workflows |
| Jenkins | Script-based integration via shell or Python |
| AWS S3 | Load or store data and docs |
| Azure Data Lake | Source and validate structured data |
| DBs (Postgres, Snowflake, etc.) | Direct expectation checks on SQL tables |
⚙️ Installation & Getting Started
Prerequisites
- Python 3.8+
- pip
- Optional: Docker, Jupyter
Step-by-Step Beginner-Friendly Setup
🔹 1. Install Great Expectations
pip install great_expectations
🔹 2. Initialize GE in Your Project
great_expectations init
Creates the great_expectations/ folder with scaffolding.
🔹 3. Create Your First Expectation Suite
great_expectations suite new
Follow prompts to create expectations using:
- CLI
- Jupyter Notebook
- YAML config
🔹 4. Run a Checkpoint
great_expectations checkpoint new my_checkpoint
great_expectations checkpoint run my_checkpoint
🔹 5. View Data Docs
open great_expectations/uncommitted/data_docs/local_site/index.html
🌍 Real-World Use Cases
1. Data Quality Testing in CI/CD
- Use GE to validate datasets before merging PRs in CI.
- Fail builds if expectations (e.g.,
no null emails) fail.
2. Security & Compliance Validation
- Enforce
expect_column_values_to_match_regexfor email or SSN fields. - Flag unencrypted or out-of-policy data entries.
3. ML Pipeline Validation
- Check distributions, missing values, and outliers in ML training datasets.
- Prevent garbage in, garbage out (GIGO).
4. Healthcare & Finance (Industry-Specific)
- Validate patient data formats (HIPAA compliance).
- Ensure transaction records follow schema (PCI-DSS, GDPR).
✅ Benefits & ⚠️ Limitations
Key Advantages
- ✅ Declarative, readable tests for data
- ✅ Easy integration with Python, Jupyter, and CI tools
- ✅ Generates automated documentation
- ✅ Supports multiple backends (files, DBs, cloud)
Common Limitations
- ❌ Requires Python environment
- ❌ Performance may degrade on very large datasets
- ❌ Learning curve for non-data engineers
🛡️ Best Practices & Recommendations
Security, Performance & Maintenance
- Mask PII in Data Docs using
evaluation_parameters - Limit test scope (e.g., sample datasets) to avoid performance hits
- Version-control expectation suites like code
Compliance & Automation Ideas
- Automate GE runs in CI/CD (daily, on pull requests)
- Align suites with compliance rulesets (e.g., ISO, SOC 2)
🔄 Comparison with Alternatives
| Tool | GE | Deequ (Amazon) | Soda SQL |
|---|---|---|---|
| Language | Python | Scala | SQL / YAML |
| Open Source | ✅ Yes | ✅ Yes | ✅ Yes |
| Data Docs | ✅ Beautiful HTML | ❌ | ✅ |
| CI/CD Friendly | ✅ Strong integration | ⚠️ Medium | ✅ |
| Use Case | General data validation | ML + Big Data pipelines | DataOps + BI |
When to Choose Great Expectations
- ✅ If your stack is Python-based
- ✅ If you want custom validation logic
- ✅ For beautiful data documentation
🧾 Conclusion
Final Thoughts
Great Expectations is a powerful and flexible data validation framework that fits neatly into the DevSecOps mindset. With automation, security, and governance built into data workflows, it ensures you trust your data just as much as your code.
Future Trends
- Growing use of GE in DataOps pipelines
- Native plugins for dbt, Apache Airflow, and Kubernetes
- Enhanced integration with cloud-native and AI/ML workflows
Next Steps
- Explore Great Expectations Official Docs
- Join the Slack community
- Try building a sample CI/CD data validation pipeline