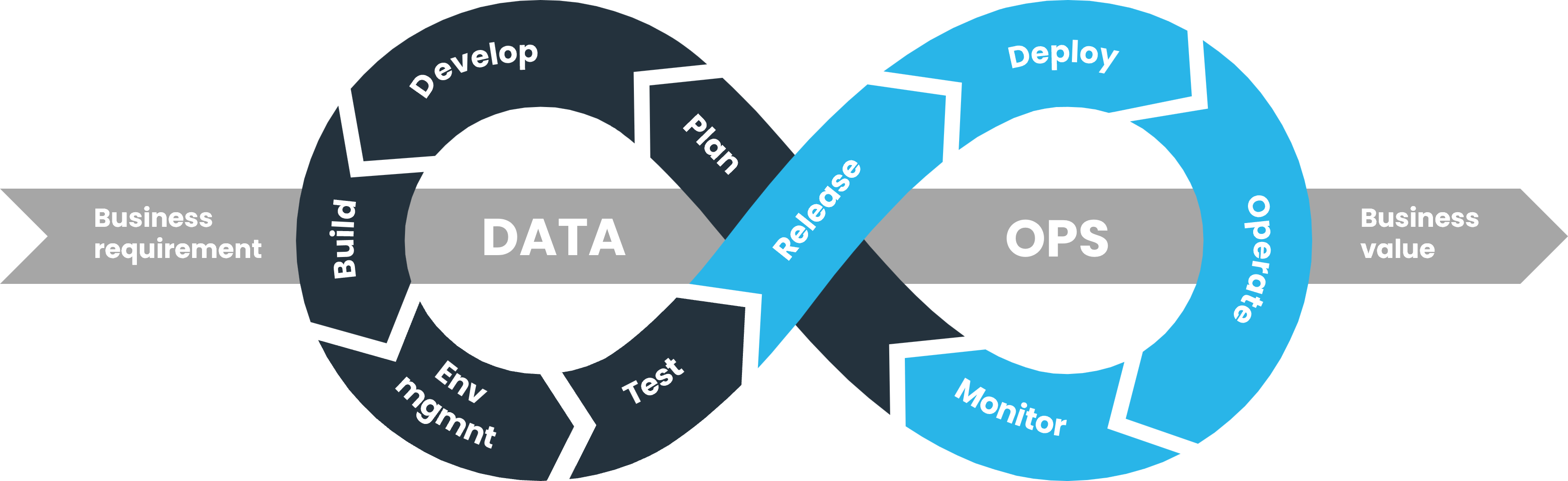
DataOps is a collaborative data management practice that applies Agile, DevOps, and lean manufacturing principles to the end-to-end data lifecycle. Its goal is to improve the speed, quality, and security of data analytics by fostering better communication, automation, and governance between data engineers, scientists, analysts, and operations teams.
History or Background
2014: Term “DataOps” introduced by Lenny Liebmann at IBM Big Data Hub.
2017: Andy Palmer (Tamr) helped popularize it further.
2020+: Tools like Apache NiFi, Airflow, Dagster, and KubeFlow started integrating DataOps concepts.
2023–2025: Widespread enterprise adoption across Finance, Healthcare, Retail, and Security.
Why is it Relevant in DevSecOps?
Relevance in DevSecOps
Description
🔄 Continuous Data Integration
Syncs secure data with CI/CD pipelines and analytics workflows
🔍 Real-Time Security Analysis
Feeds logs, events, and telemetry data to security analytics systems
✅ Compliance & Auditing
Ensures PII/GDPR/HIPAA compliance in pipelines using policy-as-code
⚙️ Automation of Data Checks
Integrates automated testing for data quality, schema drift, and lineage
2. Core Concepts & Terminology
Key Terms and Definitions
Term
Definition
Data Pipeline
An automated sequence of steps to move, clean, and transform data.
Orchestration
Coordination of tasks (e.g., Apache Airflow for DAG-based orchestration).
Data Observability
Monitoring data for quality, lineage, freshness, and anomalies.
Data Lineage
Track how data moves and transforms across systems.
DataOps Toolchain
Tools used for ingestion, transformation, observability, versioning, etc.
Policy-as-Code
Security/compliance rules embedded in the pipeline via code.
How It Fits into the DevSecOps Lifecycle
DevSecOps Stage
DataOps Integration
Plan
Define data models, privacy policies, and risk assessments.
Develop
Use version control for data pipelines and transformations.
Build
Integrate tests for data quality and schema validation.
Test
Automate security, compliance, and unit testing of data flows.
Release
Use CI/CD to deploy pipelines with audit trails.
Operate
Monitor data SLAs, errors, and lineage.
Monitor
Trigger alerts on anomalies, unauthorized access, or breaches.
DataOps complements DevSecOps by continuously managing secure data flows and analytics pipelines through automation, security checks, and observability.
3. Architecture & How It Works
Components of a DataOps Architecture
Data Sources: Databases, APIs, IoT, logs, etc.
Ingestion Layer: Tools like Apache NiFi, Kafka, or Fivetran.
Storage & Lakehouse: AWS S3, Google BigQuery, Snowflake, Delta Lake.
Transformation Layer: dbt, Apache Spark, Airflow.
Testing & Validation: Great Expectations, Soda Core.
DataOps stack tools (e.g., dbt, Airflow, Great Expectations)
Step-by-Step: DataOps with Airflow + dbt + Great Expectations
Step 1: Clone Repo
bash
Copy
Edit
git clone https://github.com/example/dataops-demo.git
cd dataops-demo
Step 2: Start Airflow with Docker
bash
Copy
Edit
docker-compose up -d
Step 3: Initialize Airflow Database
bash
Copy
Edit
docker-compose exec airflow-webserver airflow db init
Step 4: Access UI
Go to http://localhost:8080
Login: admin / admin
Step 5: Set Up Your dbt Project
bash
Copy
Edit
pip install dbt-core
dbt init my_project
Now you have a functional pipeline: Airflow orchestrates your dbt models!
5. Real-World Use Cases
✅ Use Case 1: Continuous Security Data Ingestion
Ingest threat logs from multiple tools (e.g., Falco, CrowdStrike)
Transform & analyze with Spark
Alert via Airflow DAG on anomaly detection
✅ Use Case 2: GDPR Compliance Pipeline
Scan data using Great Expectations for PII
Route violations to Splunk or Jira for compliance officers
Record lineage using Apache Atlas
✅ Use Case 3: Automated Model Monitoring in FinTech
Data flows from real-time trading system
Validated daily by Monte Carlo
Alerts if model drift or schema changes are detected
✅ Use Case 4: Retail Inventory Forecasting
Data from 50 stores ingested nightly
dbt transforms it into sales + inventory dashboards
Slack alerts sent for threshold breaches
6. Benefits & Limitations
Key Advantages
⏱️ Faster delivery of data products
🔐 Embedded security & compliance
🔍 Observability and quality checks
🔄 Integration with DevOps toolchains
Common Challenges
Challenge
Notes
🔍 Tool Sprawl
Too many tools can complicate management
🧠 Skill Gap
Requires knowledge in both DevOps and Data Engineering
🔒 Data Security Complexity
Securing pipelines across cloud platforms can be difficult
🔄 Testing Complexity
Difficult to version/test data transformations like software
7. Best Practices & Recommendations
🔐 Security, Maintenance, and Compliance
Use encryption in transit and at rest
Integrate with policy-as-code frameworks (e.g., OPA)
Automate data quality checks via Great Expectations
Rotate secrets using Vault or cloud-native managers
Store lineage in Apache Atlas or Marquez
⚙️ Performance & Automation Tips
Run batch jobs on auto-scaling clusters
Use GitOps to version-control pipeline configs
Monitor with Grafana dashboards
Use CI/CD to auto-deploy dbt or Airflow DAG changes
8. Comparison with Alternatives
Feature
DataOps (Airflow + dbt)
Traditional ETL Tools
ML Ops
Automation
✅ High
❌ Low
✅ Medium
Version Control
✅ Git-Based
❌ Manual
✅ Git
Security & Compliance
✅ Integrated
❌ Minimal
✅ Integrated
CI/CD Integration
✅ Strong
❌ Weak
✅ Medium
Data Lineage
✅ Native Support
❌ Rare
✅ Medium
When to Choose DataOps
Choose DataOps if:
You need real-time secure data flows
You’re working in a DevSecOps or regulated environment
You want CI/CD-style delivery for data pipelines
Your teams include DevOps + Data + Security engineers
9. Conclusion
Final Thoughts
DataOps is no longer optional — it’s foundational in DevSecOps pipelines where secure, fast, and auditable data handling is critical. It merges automation, observability, and compliance with modern data engineering.
The future of DevSecOps is data-aware and AI-augmented, and DataOps is the enabler.
Future Trends
Rise of Data Contracts for API-level data governance
Introduction Data is now one of the most important assets for modern organizations. Companies depend on data pipelines, analytics dashboards, reporting systems, cloud platforms, and automated workflows…
Introduction Stepping into the financial world can feel overwhelming, but securing high-quality stock market education is the ultimate way to build long-term wealth. For individuals starting their…
To win in the modern digital landscape, visibility is everything. Growing brands and busy agencies frequently struggle to balance keyword tracking, technical audits, content creation, creator outreach,…
Introduction Digital‑first businesses are under intense pressure to ship faster, stay secure, and scale reliably across complex multi‑cloud environments. Traditional ways of building and operating software cannot…
Introduction Modern enterprises face the monumental challenge of delivering software at breakneck speeds without sacrificing infrastructure stability. Relying on isolated development and operations teams is no longer…
Introduction In modern data engineering, building a data pipeline is only half the battle. The real challenge lies in ensuring that the data flowing through these pipelines…