Introduction & Overview
Data Build Tool (dbt) is a transformative tool in the DataOps ecosystem, enabling data teams to manage and transform data efficiently within data warehouses. This tutorial provides an in-depth exploration of dbt, its role in DataOps, and practical guidance for implementation. Designed for technical readers, it covers core concepts, architecture, setup, use cases, benefits, limitations, best practices, and comparisons with alternatives.
What is dbt (Data Build Tool)?
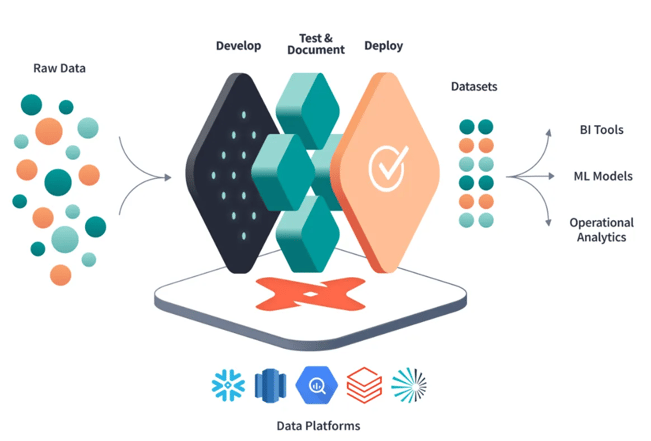
dbt is an open-source command-line tool that enables data analysts and engineers to transform data in their warehouses by writing SQL-based transformations. It provides a framework for defining, testing, and documenting data transformations, treating SQL queries as modular, reusable code.
- Purpose: Simplifies data transformation workflows by combining SQL with software engineering principles like modularity and version control.
- Core Functionality: Compiles SQL queries into executable code, manages dependencies, and automates testing and documentation.
- Deployment: Runs on cloud data warehouses like Snowflake, BigQuery, Redshift, or Databricks.
History or Background
dbt was created by Fishtown Analytics (now dbt Labs) in 2016 to address inefficiencies in data transformation workflows. Traditional ETL (Extract, Transform, Load) processes often involved complex scripts and manual processes. dbt introduced a modern ELT (Extract, Load, Transform) approach, leveraging the power of cloud data warehouses to perform transformations post-loading.
- Key Milestones:
- 2016: Initial release as an open-source tool.
- 2018: Introduction of dbt Cloud, a hosted solution with a web-based IDE.
- 2021: dbt Labs raised significant funding, expanding adoption.
- 2025: dbt continues to evolve with enhanced integrations for DataOps pipelines.
Why is it Relevant in DataOps?
DataOps emphasizes collaboration, automation, and agility in data pipelines. dbt aligns with these principles by:
- Enabling Collaboration: Allows data analysts, engineers, and scientists to work together using SQL, a common language.
- Automating Workflows: Integrates with CI/CD pipelines for automated testing and deployment.
- Improving Quality: Built-in testing and documentation ensure reliable, reproducible data outputs.
- Supporting Scalability: Leverages cloud data warehouses for handling large-scale data transformations.
Recent posts on X highlight the shift from ETL to ELT, underscoring dbt’s role in modern data stacks by enabling raw data extraction and transformation within warehouses.
Core Concepts & Terminology
Key Terms and Definitions
- Models: SQL queries defining transformations, stored as
.sqlfiles. Models represent tables or views in the data warehouse. - Sources: Raw data tables or datasets ingested into the warehouse, defined in YAML files for reference.
- Tests: Assertions to validate data quality, such as uniqueness or non-null checks.
- Seeds: Static CSV files loaded into the warehouse for reference data.
- Snapshots: Mechanisms to capture historical data changes, enabling point-in-time analysis.
- Packages: Reusable dbt code modules shared across projects.
- Materializations: Define how models are stored (e.g., table, view, incremental, ephemeral).
| Term | Description | Example |
|---|---|---|
| Model | A SQL file that defines a transformation (compiled into a table or view). | models/orders.sql |
| Seed | CSV files that can be version-controlled and loaded into the warehouse. | Reference data |
| Snapshot | Captures and tracks slowly changing dimensions. | Tracking user subscription changes |
| Test | Ensures data quality (e.g., unique, not null, relationships). | tests/unique_orders.sql |
| Macro | Reusable SQL snippets written in Jinja templating. | Date conversion macro |
| Documentation | Auto-generated from models, sources, and descriptions. | dbt docs generate |
How dbt Fits into the DataOps Lifecycle
DataOps involves stages like data ingestion, transformation, testing, deployment, and monitoring. dbt primarily operates in the transformation and testing phases:
- Ingestion: Data is loaded into the warehouse (e.g., via tools like Fivetran or Airbyte).
- Transformation: dbt models transform raw data into analytics-ready tables.
- Testing: dbt runs tests to ensure data integrity.
- Deployment: dbt integrates with CI/CD tools (e.g., GitHub Actions) for automated deployment.
- Monitoring: dbt’s documentation and lineage graphs aid in monitoring data pipelines.
Architecture & How It Works
Components and Internal Workflow
dbt operates as a transformation layer on top of a data warehouse:
- dbt Core: Open-source CLI tool for running dbt locally or on servers.
- dbt Cloud: Hosted platform with a web IDE, scheduler, and integrations.
- Jinja Templating: Embeds logic (loops, conditionals) in SQL for dynamic queries.
- Dependency Management: dbt resolves model dependencies to execute transformations in the correct order.
- Lineage Graph: Visual representation of model dependencies and data flow.
Workflow:
- Users write SQL models and YAML configurations.
- dbt compiles models into executable SQL, incorporating Jinja logic.
- dbt executes SQL against the data warehouse.
- Tests validate outputs, and documentation is generated.
Architecture Diagram (Description)
Imagine a layered architecture:
- Bottom Layer: Cloud data warehouse (e.g., Snowflake, BigQuery) storing raw and transformed data.
- Middle Layer: dbt Core or Cloud, processing SQL models, tests, and configurations.
- Top Layer: CI/CD pipelines (e.g., GitHub Actions), orchestration tools (e.g., Airflow), and visualization tools (e.g., Looker) interacting with dbt outputs.
- Data Flow: Raw data → dbt models → transformed tables/views → downstream analytics.
┌──────────────┐
│ Source Data │ (Loaded by EL tools: Fivetran, Airbyte)
└──────┬───────┘
│
┌──────▼───────┐
│ Data │
│ Warehouse │ (Snowflake, BigQuery, Redshift, Databricks)
└──────┬───────┘
│
┌──────▼───────┐
│ dbt │
│ Models/Tests │
└──────┬───────┘
│
┌──────▼───────┐
│ Cleaned Data │
│ + Docs │
└──────────────┘
Integration Points with CI/CD or Cloud Tools
- CI/CD: dbt integrates with GitHub, GitLab, or Azure DevOps for automated testing and deployment. Example: GitHub Actions runs
dbt testanddbt runon pull requests. - Cloud Warehouses: Supports Snowflake, BigQuery, Redshift, Databricks, and PostgreSQL.
- Orchestration: Tools like Airflow or Dagster schedule dbt jobs.
- Monitoring: Integrates with observability tools like Monte Carlo for data quality checks.
Installation & Getting Started
Basic Setup or Prerequisites
- System Requirements: Python 3.8+, pip, and a supported data warehouse.
- Dependencies: Git for version control, a code editor (e.g., VS Code).
- Access: Credentials for the target data warehouse.
- Optional: dbt Cloud account for web-based setup.
Hands-On: Step-by-Step Beginner-Friendly Setup Guide
- Install dbt Core:
pip install dbt-core dbt-<adapter>2. Verify Installation:
dbt --version3. Initialize a dbt Project:
dbt init my_dbt_project
cd my_dbt_project4. Configure Database Connection:
Edit ~/.dbt/profiles.yml:
my_dbt_project:
target: dev
outputs:
dev:
type: snowflake
account: <your_account>
user: <your_user>
password: <your_password>
role: <your_role>
database: <your_database>
warehouse: <your_warehouse>
schema: public5. Create a Sample Model:
In models/example.sql:
{{ config(materialized='table') }}
SELECT * FROM {{ source('raw', 'orders') }}6. Run the Model:
dbt run7. Test the Model:
Add a test in models/schema.yml:
version: 2
models:
- name: example
columns:
- name: order_id
tests:
- unique
- not_nullRun tests:
dbt test8. Generate Documentation:
dbt docs generate
dbt docs serveReal-World Use Cases
1. E-Commerce: Sales Analytics
Scenario: An e-commerce company needs to aggregate sales data for reporting.
- Implementation: dbt models transform raw order data into aggregated tables (e.g., daily sales by product). Tests ensure order IDs are unique and prices are positive.
- Outcome: Automated dashboards in Looker, refreshed daily via dbt Cloud.
2. Finance: Fraud Detection
Scenario: A fintech firm detects fraudulent transactions using historical patterns.
- Implementation: dbt snapshots capture transaction changes, and models calculate risk scores. CI/CD pipelines deploy updates automatically.
- Outcome: Real-time fraud alerts with high data quality.
3. Healthcare: Patient Data Aggregation
Scenario: A hospital consolidates patient data from multiple sources.
- Implementation: dbt sources define raw datasets, and models create unified patient profiles. Tests validate data completeness.
- Outcome: Compliant, analytics-ready data for research.
4. Marketing: Campaign Performance
Scenario: A marketing agency tracks campaign ROI across platforms.
- Implementation: dbt models join campaign data with conversions. Incremental materializations optimize performance.
- Outcome: Cost-effective, scalable analytics pipeline.
Benefits & Limitations
Key Advantages
- SQL-Based: Accessible to analysts familiar with SQL.
- Modularity: Reusable models and packages reduce redundancy.
- Testing: Built-in data quality checks improve reliability.
- Documentation: Auto-generated lineage and docs enhance transparency.
- Scalability: Leverages cloud warehouse performance.
Common Challenges or Limitations
- SQL Dependency: Limited to SQL-based transformations, less flexible for complex logic.
- Learning Curve: Jinja templating and YAML configurations require training.
- Warehouse Costs: Heavy transformations can increase compute costs.
- No Real-Time: Best suited for batch processing, not streaming.
Best Practices & Recommendations
Security Tips
- Restrict Access: Use role-based access control in the data warehouse.
- Secure Credentials: Store sensitive data in environment variables or secrets managers.
- Audit Logs: Enable logging in dbt Cloud for traceability.
Performance
- Incremental Models: Use incremental materializations for large datasets.
- Partitioning: Leverage warehouse partitioning for efficient queries.
- Optimize Jinja: Minimize complex logic in SQL templates.
Maintenance
- Version Control: Use Git for model versioning and collaboration.
- Modular Design: Break models into smaller, reusable components.
- Regular Testing: Schedule
dbt testin CI/CD pipelines.
Compliance Alignment
- Data Governance: Tag sensitive data in models for compliance (e.g., GDPR, HIPAA).
- Documentation: Maintain detailed docs for audit trails.
Automation Ideas
- CI/CD Integration: Automate
dbt runanddbt testvia GitHub Actions. - Scheduling: Use dbt Cloud or Airflow for job orchestration.
- Monitoring: Integrate with observability tools for alerts on test failures.
Comparison with Alternatives
| Feature/Tool | dbt | Airflow | Spark | Dataform |
|---|---|---|---|---|
| Primary Use | SQL-based transformations | Workflow orchestration | Large-scale processing | Web-based ELT |
| Ease of Use | High (SQL-focused) | Moderate (Python-based) | Complex (Scala/Python) | High (Web IDE) |
| Testing | Built-in | Custom scripts | Limited | Built-in |
| Scalability | Warehouse-dependent | High | Very high | Warehouse-dependent |
| Cost | Free (Core), paid (Cloud) | Free | Infrastructure costs | Paid |
When to Choose dbt
- Use dbt: For SQL-centric teams, cloud warehouse environments, and modular ELT pipelines.
- Choose Alternatives:
- Airflow: For complex orchestration across multiple tools.
- Spark: For big data or non-SQL transformations.
- Dataform: For web-based ELT with less CLI focus.
Conclusion
dbt is a cornerstone of modern DataOps, enabling scalable, reliable, and collaborative data transformation. Its SQL-based approach, combined with testing and documentation, aligns with DataOps principles of automation and quality. As data volumes grow and ELT adoption increases, dbt’s role will expand, especially with advancements in cloud integrations and AI-driven analytics.