Introduction & Overview
Data deployment pipelines are critical in modern data engineering, enabling organizations to manage, process, and deploy data efficiently within a DataOps framework. This tutorial provides an in-depth exploration of data deployment pipelines, focusing on their role in DataOps, architecture, setup, use cases, benefits, limitations, and best practices. Designed for technical readers, including data engineers, analysts, and DevOps professionals, this guide aims to equip you with the knowledge to implement and optimize data deployment pipelines effectively.
What is a Data Deployment Pipeline?
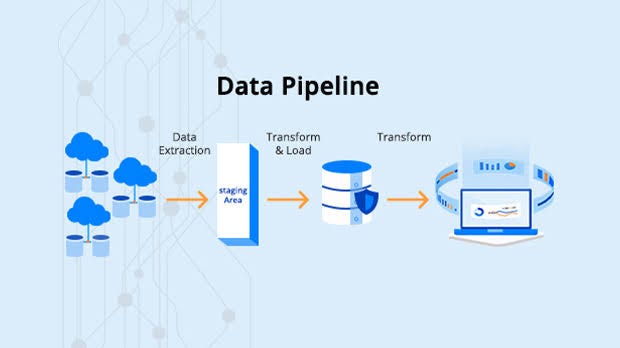
A data deployment pipeline is an automated, end-to-end process that ingests, processes, transforms, and delivers data from various sources to target systems (e.g., data lakes, warehouses, or analytics platforms). It ensures data quality, governance, and timely delivery, aligning with DataOps principles of collaboration, automation, and continuous improvement. Unlike traditional ETL (Extract, Transform, Load) processes, data deployment pipelines emphasize automation, scalability, and integration with modern CI/CD practices.
History or Background
The concept of data pipelines emerged with the rise of big data and cloud computing in the early 2000s. Initially, ETL processes were manual and rigid, often managed by in-house scripts. The advent of DataOps, inspired by DevOps, introduced automation, version control, and collaboration to data workflows. Data deployment pipelines evolved to support real-time processing, cloud-native architectures, and complex data ecosystems, driven by tools like Apache Kafka, Airflow, and cloud platforms (AWS, Azure, Google Cloud). Today, they are integral to enterprise data strategies, supporting analytics, AI/ML, and digital transformation.
- Early 2000s: Data teams manually moved ETL scripts, SQL queries, and reports into production. Errors and delays were common.
- 2010s: Emergence of DevOps practices led to inspiration for automating data processes → DataOps was born.
- Modern tools (Airflow, dbt, Jenkins, GitHub Actions, Azure Data Factory, etc.) now provide built-in support for data deployment pipelines.
Why is it Relevant in DataOps?
DataOps is a methodology that applies agile and DevOps principles to data management, emphasizing automation, collaboration, and continuous delivery. Data deployment pipelines are relevant because they:
- Enable Automation: Automate data ingestion, transformation, and deployment, reducing manual errors and accelerating delivery.
- Support Collaboration: Facilitate cross-team workflows (data engineers, analysts, scientists) with shared processes and tools.
- Ensure Governance: Integrate data quality checks, security, and compliance within the pipeline.
- Align with CI/CD: Incorporate version control and automated testing, aligning data workflows with software development practices.
- Drive Scalability: Handle increasing data volumes and complexity in cloud-native environments.
Core Concepts & Terminology
Key Terms and Definitions
- Data Pipeline: A series of processes to collect, transform, and deliver data from source to destination.
- DataOps: A methodology combining DevOps, agile, and lean principles to streamline data workflows.
- Batch Processing: Processing data in fixed intervals (e.g., daily reports).
- Streaming Processing: Real-time data processing for immediate analytics (e.g., IoT sensor data).
- CI/CD: Continuous Integration/Continuous Delivery, automating testing and deployment of code or data changes.
- Schema Drift: Changes in source data structure (e.g., new columns) that pipelines must handle.
- Data Source Rules: Configurations to manage data source connections across environments (e.g., dev, test, prod).
- Orchestration: Coordinating tasks within a pipeline using tools like Apache Airflow or Azure Data Factory.
| Term | Definition |
|---|---|
| Data Pipeline | Series of steps to move & transform data from source to destination. |
| Deployment Pipeline | Automated process to test, validate, and push code or data artifacts across environments. |
| ETL/ELT | Extract-Transform-Load / Extract-Load-Transform operations. |
| Orchestration | Scheduling & managing workflow execution (e.g., Apache Airflow). |
| DataOps | Methodology combining DevOps, Agile, and Lean principles for managing data workflows. |
| Versioning | Keeping history of datasets, schemas, and transformations for reproducibility. |
How It Fits into the DataOps Lifecycle
The DataOps lifecycle includes stages like data ingestion, transformation, quality assurance, deployment, and monitoring. Data deployment pipelines fit as follows:
- Ingestion: Collect data from sources (databases, APIs, IoT).
- Transformation: Cleanse, enrich, and transform data for analytics.
- Quality Assurance: Apply data quality rules and validation checks.
- Deployment: Deliver data to target systems (e.g., data warehouse, BI tools).
- Monitoring: Track pipeline performance, errors, and data quality.
Pipelines integrate with CI/CD tools to automate these stages, ensuring traceability, repeatability, and collaboration across teams.
Architecture & How It Works
Components and Internal Workflow
A data deployment pipeline typically consists of:
- Data Sources: Databases (SQL/NoSQL), APIs, streaming sources (Kafka, IoT).
- Ingestion Layer: Tools like Apache NiFi, Airbyte, or AWS Glue to extract data.
- Transformation Layer: Processes data using tools like Apache Spark, dbt, or Python scripts.
- Orchestration Layer: Manages tasks and dependencies (e.g., Airflow, Azure Data Factory).
- Storage Layer: Stores processed data in data lakes (e.g., Delta Lake), warehouses (e.g., Snowflake), or databases.
- Delivery Layer: Deploys data to BI tools (e.g., Power BI, Tableau) or ML models.
- Monitoring & Logging: Tracks pipeline health, data quality, and errors (e.g., Prometheus, Grafana).
Workflow:
- Data is ingested from sources using connectors.
- Transformation scripts cleanse and enrich data.
- Orchestration schedules and executes tasks.
- Data is validated for quality and compliance.
- Processed data is deployed to target systems.
- Monitoring tools log performance and alert on issues.
Architecture Diagram (Description)
Imagine a flowchart with the following structure:
- Left: Multiple data sources (e.g., SQL database, Kafka stream, SaaS API) feed into an ingestion layer (e.g., Airbyte).
- Center: The ingestion layer connects to a transformation layer (e.g., Apache Spark on Databricks) via an orchestration tool (e.g., Airflow). Transformation outputs are stored in a data lake (e.g., Delta Lake).
- Right: The data lake feeds a data warehouse (e.g., Snowflake), which connects to BI tools (e.g., Power BI) and ML models. Monitoring tools (e.g., Grafana) oversee the pipeline, with feedback loops to orchestration.
[Source Systems] --> [Ingestion] --> [Transformation/Processing] --> [Testing & Validation] --> [Artifact Repository] --> [Delivery/Publishing]
^
|-----[Orchestration, Monitoring, Logging] (across all layers)
Integration Points with CI/CD or Cloud Tools
- CI/CD Tools: Integrate with Git (e.g., GitHub, Azure DevOps) for version control of pipeline scripts and configurations. Use Jenkins or GitHub Actions for automated testing and deployment.
- Cloud Tools:
- AWS: Use AWS Glue for ETL, Lambda for serverless processing, and Step Functions for orchestration.
- Azure: Leverage Azure Data Factory for orchestration, Synapse Analytics for processing, and Power BI for visualization.
- Google Cloud: Utilize Dataflow for streaming, BigQuery for storage, and Composer for Airflow-based orchestration.
- APIs: REST APIs (e.g., Microsoft Fabric APIs) automate pipeline management and deployment.
Installation & Getting Started
Basic Setup or Prerequisites
- Hardware/Software:
- A cloud account (AWS, Azure, or Google Cloud) or on-premises server.
- Tools: Python 3.8+, Apache Airflow, Docker (for containerized environments).
- Access to a data source (e.g., PostgreSQL, Kafka) and target (e.g., Snowflake).
- Permissions: Admin access to cloud platforms and data sources.
- Skills: Basic knowledge of Python, SQL, and CI/CD concepts.
- Dependencies: Install required libraries (e.g.,
pandas,pyspark,airflow).
Hands-on: Step-by-Step Beginner-Friendly Setup Guide
This guide sets up a simple data deployment pipeline using Apache Airflow and PostgreSQL on a local machine.
- Install Apache Airflow:
pip install apache-airflow
airflow db init
airflow users create --username admin --firstname Admin --lastname User --role Admin --email admin@example.com --password admin2. Set Up PostgreSQL:
- Install PostgreSQL and create a database:
CREATE DATABASE source_db;
CREATE TABLE sales (id INT, product VARCHAR, amount FLOAT);
INSERT INTO sales VALUES (1, 'Laptop', 1000.0), (2, 'Phone', 500.0);3. Create Airflow DAG:
- Create a file
sales_pipeline.pyin the Airflow DAGs folder (~/airflow/dags):
from airflow import DAG
from airflow.operators.python import PythonOperator
from datetime import datetime
import pandas as pd
import psycopg2
def extract_data():
conn = psycopg2.connect("dbname=source_db user=postgres password=your_password")
df = pd.read_sql("SELECT * FROM sales", conn)
df.to_csv("/tmp/sales_data.csv", index=False)
conn.close()
def transform_data():
df = pd.read_csv("/tmp/sales_data.csv")
df['amount'] = df['amount'] * 1.1 # Apply 10% markup
df.to_csv("/tmp/transformed_sales.csv", index=False)
def load_data():
conn = psycopg2.connect("dbname=target_db user=postgres password=your_password")
df = pd.read_csv("/tmp/transformed_sales.csv")
df.to_sql("sales_transformed", conn, if_exists="replace", index=False)
conn.close()
with DAG('sales_pipeline', start_date=datetime(2025, 8, 1), schedule_interval='@daily') as dag:
extract = PythonOperator(task_id='extract', python_callable=extract_data)
transform = PythonOperator(task_id='transform', python_callable=transform_data)
load = PythonOperator(task_id='load', python_callable=load_data)
extract >> transform >> load4. Start Airflow:
airflow webserver --port 8080 &
airflow scheduler &- Access the Airflow UI at
http://localhost:8080and trigger thesales_pipelineDAG.
5. Verify Output:
- Check the
sales_transformedtable in the target database to confirm data deployment.
Real-World Use Cases
- Retail Analytics (Batch Processing):
- Scenario: A retail company processes daily sales data to generate reports in Power BI.
- Pipeline: Ingests sales data from POS systems, transforms it (e.g., aggregates by region), and loads it into a Snowflake warehouse.
- DataOps Role: Automates data quality checks and integrates with Git for version control, ensuring consistent reports.
- IoT Real-Time Monitoring (Streaming):
- Scenario: A manufacturing firm monitors sensor data for predictive maintenance.
- Pipeline: Uses Kafka for real-time ingestion, Spark Streaming for processing, and deploys alerts to a dashboard.
- DataOps Role: Ensures real-time data integrity and scalability with automated monitoring.
- Healthcare Compliance:
- Scenario: A hospital integrates patient data from EMR systems into a data lake for compliance reporting.
- Pipeline: Uses Airbyte for ingestion, dbt for transformation, and Azure Data Factory for orchestration, with HIPAA-compliant security rules.
- DataOps Role: Enforces governance and audit trails for regulatory compliance.
- Financial Fraud Detection:
- Scenario: A bank processes transaction data to detect fraudulent activities in real time.
- Pipeline: Ingests transactions via Kafka, applies ML models in Databricks, and deploys results to a BI tool.
- DataOps Role: Integrates CI/CD for model updates and automates data quality checks.
Benefits & Limitations
Key Advantages
- Automation: Reduces manual intervention, saving time and minimizing errors.
- Scalability: Handles large data volumes and diverse sources in cloud environments.
- Governance: Enforces data quality, security, and compliance through integrated checks.
- Collaboration: Enables cross-team workflows with shared tools and processes.
- Speed: Accelerates data delivery for analytics and AI/ML use cases.
Common Challenges or Limitations
- Complexity: Designing and maintaining pipelines for diverse data sources can be complex.
- Cost: Cloud-based pipelines may incur high costs for large-scale processing.
- Schema Drift: Unhandled changes in source data can break pipelines.
- Learning Curve: Requires expertise in orchestration tools and cloud platforms.
- Monitoring Overhead: Continuous monitoring and error handling demand robust systems.
Best Practices & Recommendations
- Security Tips:
- Use encryption (e.g., TLS, AES) for data in transit and at rest.
- Implement role-based access controls (RBAC) for pipeline access.
- Mask sensitive data during transformation (e.g., PII in healthcare).
- Performance:
- Optimize transformations with parallel processing (e.g., Spark).
- Use incremental data loading to reduce processing time.
- Monitor resource usage to avoid over-provisioning cloud resources.
- Maintenance:
- Regularly update pipeline dependencies and test for compatibility.
- Log errors and performance metrics for proactive issue resolution.
- Compliance Alignment:
- Integrate compliance checks (e.g., GDPR, HIPAA) into pipeline stages.
- Maintain audit trails for all data transformations and deployments.
- Automation Ideas:
- Use CI/CD tools (e.g., GitHub Actions) to automate pipeline testing and deployment.
- Implement auto-scaling for cloud resources based on data volume.
- Automate schema drift detection with tools like Great Expectations.
Comparison with Alternatives
| Feature | Data Deployment Pipeline | ETL Tools (e.g., Informatica) | Custom Scripts |
|---|---|---|---|
| Automation | High (CI/CD integration) | High (GUI-based workflows) | Low (manual coding) |
| Scalability | Excellent (cloud-native) | Good (enterprise-focused) | Poor (hard to scale) |
| Ease of Use | Moderate (requires setup) | High (drag-and-drop interfaces) | Low (coding expertise) |
| Flexibility | High (customizable) | Moderate (vendor-specific) | High (fully customizable) |
| Cost | Variable (cloud-based) | High (licensing fees) | Low (development time) |
| DataOps Alignment | Strong (CI/CD, governance) | Moderate (limited CI/CD) | Weak (manual processes) |
When to Choose Data Deployment Pipelines:
- When integrating with modern CI/CD workflows and cloud platforms.
- For organizations prioritizing automation, scalability, and DataOps principles.
- When handling diverse data sources and real-time processing needs.
- Avoid for simple, one-off ETL tasks better suited for GUI-based tools like Informatica.
Conclusion
Data deployment pipelines are a cornerstone of DataOps, enabling organizations to automate, scale, and govern data workflows effectively. By integrating with CI/CD tools, cloud platforms, and robust monitoring, they support modern analytics and AI/ML use cases. While challenges like complexity and cost exist, best practices in security, performance, and automation can mitigate these issues. As data volumes and complexity grow, pipelines will evolve with advancements in serverless computing, AI-driven automation, and enhanced governance.
Next Steps:
- Experiment with the Airflow setup provided in this tutorial.
- Explore cloud-specific tools (e.g., Azure Data Factory, AWS Glue).
- Join DataOps communities for collaboration and learning.
Resources:
- dbt Documentation
- Apache Airflow
- DataOps Manifesto
- Great Expectations