1. Introduction & Overview
In the realm of DevSecOps, the need for scalable, secure, and cost-effective data storage that can accommodate varied data types from multiple pipelines is critical. This is where the concept of a Data Lake becomes highly relevant.
Why Focus on Data Lakes in DevSecOps?
- Growing adoption of cloud-native infrastructure
- Explosion of telemetry, logs, metrics, and audit data
- Integration of security data into DevOps pipelines
2. What is a Data Lake?
Definition:
A Data Lake is a centralized repository that allows you to store structured, semi-structured, and unstructured data at any scale. You can store data as-is, without having to structure it first, and run different types of analytics to derive insights.
History & Background:
- Coined by James Dixon (former CTO of Pentaho)
- Evolved from traditional data warehouses which required data normalization
- Embraced by modern platforms like AWS (S3 + Lake Formation), Azure Data Lake, Google Cloud Storage + BigLake
Relevance in DevSecOps:
- Stores security logs, threat intel, CI/CD pipeline data, and compliance metrics
- Enables real-time monitoring, incident forensics, and risk scoring
- Provides a foundation for automated security analytics
3. Core Concepts & Terminology
Key Terms:
| Term | Definition |
|---|---|
| Raw Zone | Stores unprocessed data |
| Cleansed Zone | Stores transformed/validated data |
| Curated Zone | Finalized datasets ready for analysis |
| Metadata Catalog | Indexes data assets for discoverability |
| Schema-on-Read | Data is parsed only when read |
| Object Storage | Storage layer for data (e.g., S3, GCS) |
Fit in DevSecOps Lifecycle:
| DevSecOps Phase | Data Lake Use |
|---|---|
| Plan | Historical analysis of defects or CVEs |
| Develop | Store and scan code and commit metadata |
| Build/Test | Capture build logs, test results |
| Release | Log security gate decisions |
| Deploy | Collect deployment artifacts |
| Operate | Monitor logs, alerts, anomaly data |
| Secure | Centralize security data, incident evidence |
4. Architecture & How It Works
Key Components:
- Ingestion Layer: Collects data from pipelines, apps, APIs
- Storage Layer: Cloud object storage like S3, GCS, Azure Blob
- Catalog & Metadata Layer: Tools like AWS Glue, Apache Hive
- Processing Engine: Spark, Presto, AWS Athena, BigQuery
- Access Layer: Dashboards (e.g., Grafana), Notebooks (Jupyter), API access
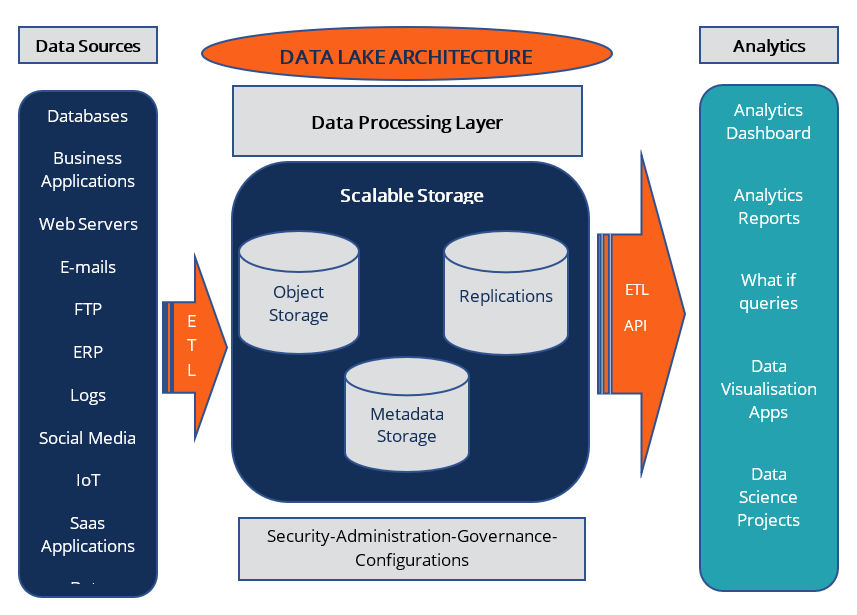
Internal Workflow:
- Ingest: Raw CI/CD logs, secrets, audit trails from tools (e.g., Jenkins, GitHub Actions)
- Store: Save as-is in object storage
- Process: Cleanse, tag, transform with Spark/Airflow
- Query/Visualize: Analyze using SQL engines, Grafana, or ML models
Architecture Diagram (Description):
[CI/CD Pipeline] ---> [Ingestion (Kafka / AWS Kinesis)] ---> [Raw Data Zone in S3]
|
[Metadata Catalog (AWS Glue / Hive)]
|
[Data Processing Layer (Spark / Athena / BigQuery)]
|
[Curated Data Zone] --> [Security Dashboard / Alerts Engine / Reports]
CI/CD & Cloud Tool Integration:
- AWS Lake Formation + CodePipeline for policy-based ingestion
- Azure Data Lake + GitHub Actions for automated threat data pipeline
- Google BigLake + Cloud Build for structured log analysis
5. Installation & Getting Started
Prerequisites:
- Cloud account (AWS, Azure, or GCP)
- CLI access and permissions to provision storage and compute
- Basic familiarity with Python, SQL, and your CI/CD platform
Step-by-Step Setup (AWS Example):
# Step 1: Create an S3 Bucket
aws s3 mb s3://devsecops-data-lake
# Step 2: Enable versioning
aws s3api put-bucket-versioning --bucket devsecops-data-lake \
--versioning-configuration Status=Enabled
# Step 3: Set up AWS Lake Formation (via console or CLI)
# Step 4: Grant permissions
aws lakeformation grant-permissions --principal DataEngineer \
--permissions SELECT --resource ...
# Step 5: Ingest CI/CD logs (Python Example)
import boto3
s3 = boto3.client('s3')
s3.upload_file('build-logs.json', 'devsecops-data-lake', 'raw/build-logs.json')
6. Real-World Use Cases
1. Security Incident Response
- Ingest logs from intrusion detection systems (e.g., Falco, OSSEC)
- Store evidence for forensics
- Enable post-mortem analysis
2. CI/CD Pipeline Auditing
- Collect data from Jenkins, GitLab CI, ArgoCD
- Identify security gate failures or skipped validations
3. Vulnerability Trend Analysis
- Aggregate SAST/DAST results over time
- Identify repeated weak points across microservices
4. Compliance Reporting
- Store GDPR or HIPAA audit trail data
- Feed into automated compliance dashboards
7. Benefits & Limitations
Key Benefits:
- ✅ Cost-efficient at scale using object storage
- ✅ Highly scalable and schema-flexible
- ✅ Enables ML/AI-driven security automation
- ✅ Centralized data governance and security controls
Common Limitations:
- ❌ Complex data lifecycle management
- ❌ Risk of data swamp (if governance is weak)
- ❌ Requires skilled personnel for setup and analysis
- ❌ Latency issues for real-time needs (vs. stream analytics)
8. Best Practices & Recommendations
Security:
- Encrypt at rest and in transit (KMS, SSL)
- Enable access logging and auditing
- Integrate with IAM (least-privilege)
Performance:
- Partition large datasets
- Use columnar formats (e.g., Parquet)
- Set lifecycle rules to delete/archive stale data
Compliance:
- Tag data with compliance metadata (e.g., PII, PCI)
- Automate redaction/anonymization workflows
- Schedule regular data integrity checks
Automation Ideas:
- Auto-ingest logs via GitHub Actions workflows
- Trigger alerts from Athena SQL queries
- Schedule clean-up with Apache Airflow or Step Functions
9. Comparison with Alternatives
| Feature | Data Lake | Data Warehouse | SIEM |
|---|---|---|---|
| Data Type Support | Structured, Semi, Unstructured | Structured only | Logs/Events |
| Cost | Low (object storage) | High | Medium to High |
| Schema | On Read | On Write | On Write |
| Use in DevSecOps | High | Moderate | High |
When to Choose a Data Lake:
- You need to store heterogeneous data formats
- You want to integrate security, ops, and dev data centrally
- You want flexibility over rigid schemas
10. Conclusion
Data Lakes are rapidly becoming a backbone in DevSecOps, providing a secure, scalable, and analytics-ready platform for all operational and security data. When implemented properly, a data lake not only unlocks observability and compliance automation but also acts as a critical enabler of predictive and proactive DevSecOps practices.
Future Trends:
- Unified Data Lakehouse (e.g., Databricks, Snowflake)
- Federated security analytics
- AI-native threat detection from lake data
🔗 Official Resources:
- AWS Lake Formation Documentation
- Azure Data Lake Docs
- Google BigLake Overview
- Open Metadata for Data Lakes