Introduction & Overview
In the rapidly evolving landscape of data management, DataOps has emerged as a pivotal methodology that applies agile, DevOps, and lean manufacturing principles to streamline data analytics and operations. At its core, CI/CD for Data refers to the adaptation of Continuous Integration (Continuous Delivery/Deployment) practices specifically tailored for data pipelines, models, and workflows. This tutorial provides an in-depth exploration of CI/CD for Data within DataOps, equipping technical readers—such as data engineers, DevOps practitioners, and data scientists—with the knowledge to implement robust, automated data systems.
The tutorial is structured to build progressively from foundational concepts to practical applications and advanced considerations. By the end, you’ll understand how CI/CD for Data enhances reliability, speed, and collaboration in data-centric environments. Expect hands-on examples, best practices, and insights drawn from real-world implementations to make this actionable for your projects.
What is CI/CD for Data?
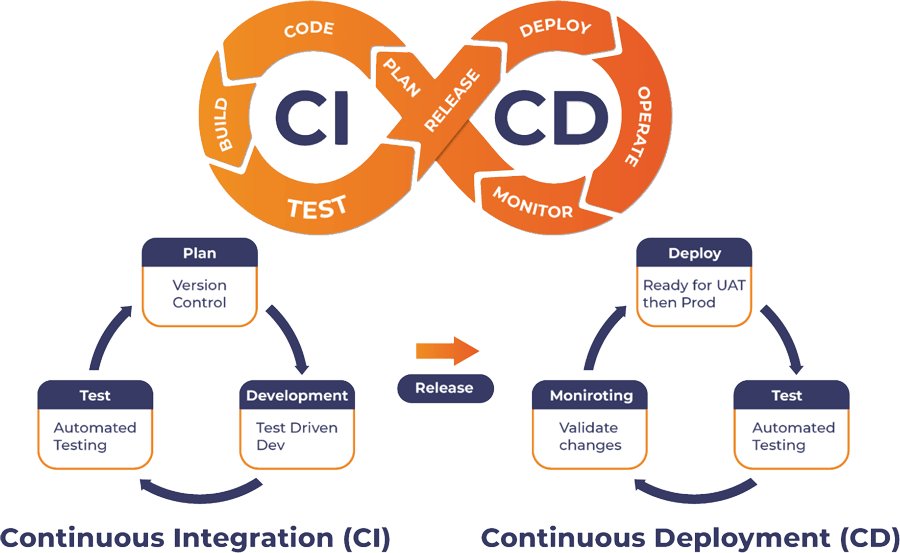
CI/CD for Data extends traditional software CI/CD principles to data engineering and analytics. In essence, it automates the integration, testing, validation, and deployment of data pipelines, ensuring that data transformations, models, and insights are delivered reliably and efficiently. Unlike code-only CI/CD, this variant handles data-specific challenges like schema changes, data quality checks, and large-scale data volumes. It involves continuous integration (merging and testing data code changes frequently) and continuous delivery/deployment (automating the release of validated data artifacts to production).
In simple words:
👉 CI/CD for Data = CI/CD principles + data pipelines + ML/analytics workflows
History or Background
The roots of CI/CD trace back to the 1990s with concepts like continuous integration introduced by Grady Booch in 1994, evolving through Agile methodologies in the early 2000s. DevOps formalized these in the 2010s, but CI/CD for Data gained traction around 2015-2017 as data volumes exploded with big data tools like Hadoop and Spark. DataOps, coined around 2017, adapted DevOps to data, emphasizing automation for data pipelines. Early adopters like Netflix and Airbnb integrated CI/CD into data workflows to handle streaming and real-time analytics, marking a shift from manual ETL processes to automated, version-controlled data ops. By the 2020s, tools like dbt and Snowflake embedded CI/CD natively, driven by cloud adoption and AI/ML demands.
2001–2010: CI/CD emerged in software engineering with Jenkins, TravisCI, and GitLab CI.
2010–2015: Rise of Big Data & Hadoop made data pipeline automation a challenge.
2015–2020: DataOps emerged to integrate DevOps, Agile, and Lean practices into data engineering.
2020 onwards: Cloud-native tools (Airflow, dbt, Azure Data Factory, GitHub Actions, ArgoCD) started enabling CI/CD pipelines for data workflows.
Why is it Relevant in DataOps?
DataOps aims to deliver high-quality data insights faster by fostering collaboration, automation, and observability. CI/CD for Data is central because it automates error-prone manual tasks, reduces deployment risks, and ensures data pipelines are testable and reproducible. In DataOps, where data teams deal with volatile sources and compliance needs, CI/CD enables rapid iterations, minimizes downtime, and aligns data delivery with business agility—critical in eras of AI-driven decisions.
Core Concepts & Terminology
Key Terms and Definitions
- Continuous Integration (CI): Frequent merging of code changes into a shared repository, followed by automated builds and tests for data pipelines (e.g., validating SQL transformations or data schemas).
- Continuous Delivery/Deployment (CD): Automating the release process so that validated changes can be deployed to production reliably, often with gates for approvals.
- Data Pipeline: A sequence of data processing steps (ingest, transform, load) treated as code for versioning and testing.
- DataOps Lifecycle: Encompasses planning, development, testing, deployment, monitoring, and feedback for data assets.
- Schema Evolution: Managing changes in data structures without breaking pipelines, often via automated migrations.
- Data Quality Gates: Automated checks for accuracy, completeness, and freshness in CI/CD workflows.
- Orchestration Tools: Software like Apache Airflow or dbt that integrate with CI/CD for scheduling and executing data workflows.
| Term | Definition | Example in DataOps |
|---|---|---|
| CI (Continuous Integration) | Frequent merging of code/data pipeline changes with automated testing | A new dbt model is validated with test datasets |
| CD (Continuous Delivery/Deployment) | Automated deployment of tested pipelines to staging/production | Deploying Airflow DAG to production after schema validation |
| Data Pipeline | Workflow for moving and transforming data | ETL job from Kafka → S3 → Snowflake |
| Data Validation | Ensuring schema consistency and data quality | Check if “Customer_ID” is unique before deploying |
| Version Control (GitOps) | Git-based workflow for pipeline management | Store ETL scripts in GitHub and trigger builds |
| Infrastructure as Code (IaC) | Defining infra using code for reproducibility | Terraform for provisioning AWS Glue & Redshift |
How it Fits into the DataOps Lifecycle
CI/CD for Data weaves through the entire DataOps lifecycle:
- Planning & Development: Version control data code (e.g., in Git) and collaborate on changes.
- Testing: Integrate unit tests for data transformations and integration tests for end-to-end pipelines.
- Deployment: Automate promotion from dev to prod environments.
- Monitoring & Feedback: Use observability to detect issues post-deployment, feeding back into CI for iterative improvements.
This integration ensures data teams achieve “flow” similar to software DevOps, reducing cycle times from weeks to hours.
Architecture & How It Works
Components, Internal Workflow
A typical CI/CD for Data architecture includes:
- Version Control System (VCS): Git repositories for storing data pipeline code (e.g., SQL scripts, Python ETL jobs).
- CI Server: Tools like Jenkins or GitHub Actions that trigger builds on commits, running tests (e.g., data validation, schema checks).
- CD Orchestrator: Automates deployments, often using tools like Argo CD or native cloud services.
- Testing Frameworks: dbt for data tests, Great Expectations for quality assertions.
- Monitoring Tools: Prometheus or Datadog for pipeline health.
- Data Environments: Isolated dev/test/prod instances (e.g., via Snowflake clones or lakeFS branches).
The workflow: A developer commits changes to a Git branch → CI triggers build/tests → If passed, CD deploys to staging → Approvals promote to production → Monitoring alerts on failures.
Architecture Diagram (Describe if Image Not Possible)
Imagine a linear flowchart:
- Source (Git Repo) → Arrow to
- CI Trigger (on Commit/Pull Request) → Builds code, runs unit/integration tests (e.g., data mocks).
- Artifact Repository (e.g., Docker images of pipelines) → Arrow to
- CD Stages: Deploy to Dev → Test Environment (automated QA) → Staging (manual review) → Production.
Branching arrows for feedback loops (e.g., failed tests revert to developer). Include side components like secrets management (Vault) and orchestration (Airflow).
Developer → Git Commit → CI (Lint + Test + Validate Data) →
Staging Environment (Integration Tests) → CD → Production Data Pipeline →
Monitoring & AlertsIntegration Points with CI/CD or Cloud Tools
- Cloud Providers: Azure DevOps for pipelines, AWS CodePipeline for AWS-native data services.
- Data Tools: dbt Cloud integrates with GitHub Actions for testing models; Snowflake with GitLab CI for schema deployments.
- ML Extensions: Databricks for MLflow in CI/CD, ensuring models are versioned and tested.
Installation & Getting Started
Basic Setup or Prerequisites
- Git installed and a repository (e.g., GitHub).
- A data tool like dbt (for transformations) or Apache Airflow.
- CI/CD platform: GitHub Actions (free for basics).
- Cloud account (e.g., Snowflake or AWS) for data environments.
- Python 3.x and pip for dependencies.
Knowledge of YAML for pipeline configs.
Hands-on: Step-by-Step Beginner-Friendly Setup Guide
We’ll set up a simple CI/CD pipeline for a dbt project using GitHub Actions.
- Initialize dbt Project:
- Install dbt:
pip install dbt-core dbt-snowflake(assuming Snowflake as target). - Create project:
dbt init my_data_project. - Add models (e.g., a SQL file in models/my_model.sql):
SELECT * FROM raw_data WHERE date > '{{ var("start_date") }}'2. Set Up Git Repo:
git init, add files, commit, push to GitHub.
3. Configure GitHub Actions:
- In repo, create
.github/workflows/ci-cd.yml:
name: dbt CI/CD
on: [push, pull_request]
jobs:
build:
runs-on: ubuntu-latest
steps:
- uses: actions/checkout@v2
- name: Set up Python
uses: actions/setup-python@v2
with: { python-version: '3.9' }
- name: Install dependencies
run: pip install dbt-core dbt-snowflake
- name: Run dbt tests
run: dbt test
env: { DBT_PROFILES_DIR: . } # Add Snowflake creds as secrets
deploy:
if: github.ref == 'refs/heads/main'
needs: build
runs-on: ubuntu-latest
steps:
- uses: actions/checkout@v2
- name: Deploy dbt
run: dbt run- Add secrets in GitHub Settings (e.g., SNOWFLAKE_USER, PASSWORD).
4. Test the Pipeline:
- Commit a change and push: GitHub Actions will run tests automatically.
- On merge to main, it deploys (runs models).
5. Monitor and Iterate:
- View logs in GitHub Actions UI. Add notifications via Slack integration.
Real-World Use Cases
3 to 4 Real DataOps Scenarios or Examples Where It Is Applied
- Streaming Analytics at Netflix: Netflix uses CI/CD for data pipelines to handle real-time user data. Changes to recommendation models are tested via automated CI, deployed continuously to ensure seamless streaming insights without downtime.
- Financial Data Processing at Capital One: In banking, CI/CD automates fraud detection pipelines. Data schema changes are integrated and tested, ensuring compliance and quick updates to risk models.
- E-Commerce Personalization at Airbnb: Airbnb applies DataOps CI/CD to user booking data. Pipelines for A/B testing listings are versioned, tested for data quality, and deployed rapidly to improve search algorithms.
- Retail Inventory Management at HomeGoods: Using Snowflake, they implement CI/CD for supply chain data, automating ETL deployments to predict stock levels and reduce overstocking.
Industry-Specific Examples If Applicable
- Healthcare: CI/CD for patient data pipelines ensures HIPAA compliance through automated audits in deployments.
- Finance: Integrates with regulatory tools for audit trails in data flows.
Benefits & Limitations
Key Advantages
- Faster Delivery: Reduces data pipeline deployment from days to minutes, enabling agile responses.
- Improved Quality: Automated tests catch data issues early, boosting reliability.
- Collaboration: Unifies data and dev teams via shared workflows.
- Scalability: Handles large datasets with cloud integrations.
Common Challenges or Limitations
- Complexity in Setup: Initial configuration for data-specific tests can be resource-intensive.
- Data Volume Issues: Testing with real data risks costs or privacy breaches; mocks are imperfect.
- Dependency Management: External data sources can break pipelines unpredictably.
- Security Risks: Automating deployments may expose sensitive data if not gated properly.
Best Practices & Recommendations
Security Tips, Performance, Maintenance
- Security: Use secrets management (e.g., HashiCorp Vault), implement role-based access, and scan for vulnerabilities in pipelines.
- Performance: Optimize tests with parallel execution; use caching for dependencies.
- Maintenance: Regularly refactor pipelines, monitor metrics, and automate rollbacks.
Compliance Alignment, Automation Ideas
- Align with GDPR/HIPAA by embedding compliance checks in CI stages.
- Automate data lineage tracking and anomaly detection in CD.
- Idea: Integrate AI for predictive testing of pipeline failures.
Comparison with Alternatives (If Applicable)
How It Compares with Similar Tools or Approaches
CI/CD for Data contrasts with manual data management (e.g., scripted ETL without automation), which is slower and error-prone. Compared to tools:
| Tool/Approach | Pros | Cons | Best For |
|---|---|---|---|
| Jenkins | Highly customizable, open-source | Steep learning curve | Complex, on-prem setups |
| GitHub Actions | Easy integration with Git, serverless | Limited for massive scales | Cloud-native, small teams |
| GitLab CI | Built-in VCS, robust for data | Higher cost for enterprise | End-to-end DataOps |
| Azure DevOps | Strong Microsoft ecosystem integration | Vendor lock-in | Azure-based data pipelines |
| Manual Deployment | Simple for small projects | High risk of errors, slow | Prototyping only |
When to Choose CI/CD for Data Over Others
Opt for CI/CD when data velocity is high and teams need automation; choose manual for one-off analyses. Prefer over alternatives if scalability and collaboration are priorities.
Conclusion
CI/CD for Data revolutionizes DataOps by automating workflows, ensuring quality, and accelerating insights in data-driven organizations. As we’ve explored, from core concepts to real-world applications, it bridges the gap between data engineering and operational excellence.
Final Thoughts, Future Trends, Next Steps
Looking ahead, trends include AI-powered pipelines for smart testing, serverless deployments, and deeper integration with event-driven architectures. Start by assessing your current pipelines and piloting a simple setup.