Introduction & Overview
What is MLflow?
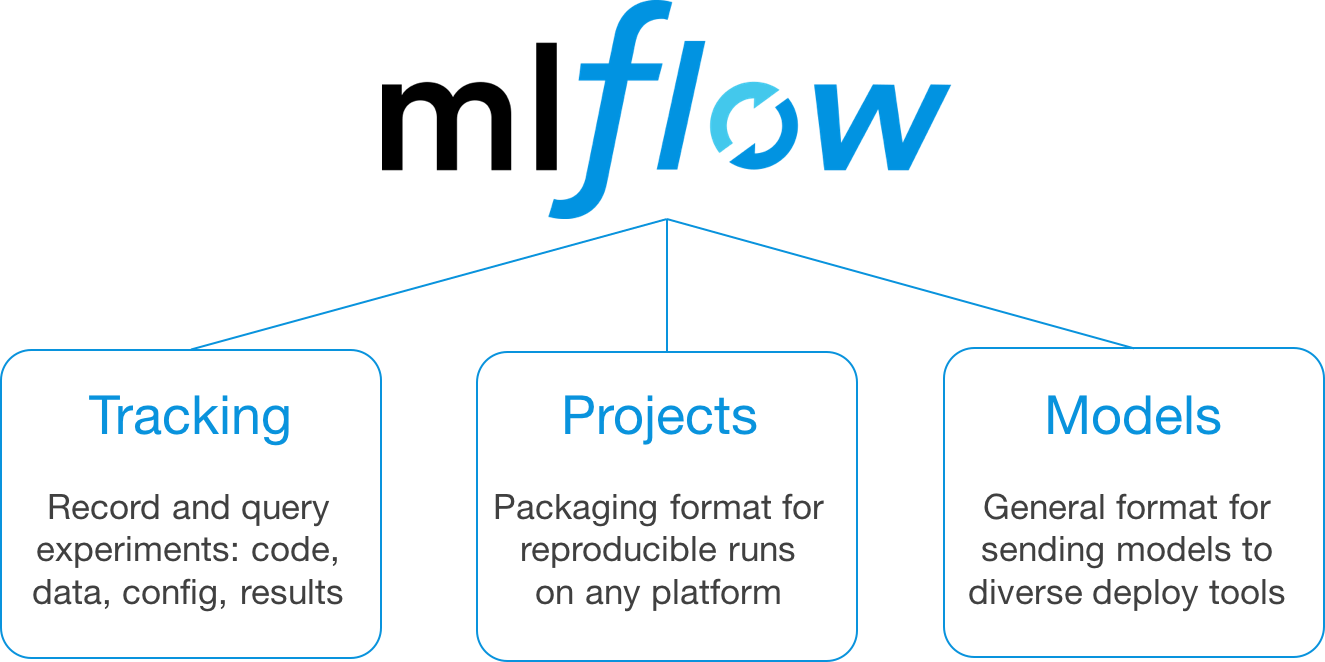
MLflow is an open-source platform designed to streamline the machine learning (ML) lifecycle, including experimentation, reproducibility, deployment, and model management. It provides a unified interface to track experiments, package code, manage models, and deploy them across diverse environments. MLflow is language-agnostic, supporting Python, R, Java, and more, making it versatile for DataOps workflows.
History or Background
MLflow was introduced by Databricks in 2018 to address the complexities of managing ML projects. As ML adoption grew, teams faced challenges in tracking experiments, reproducing results, and deploying models consistently. MLflow emerged as a solution to standardize these processes, gaining traction in the DataOps community for its ability to integrate with CI/CD pipelines and cloud platforms. Its open-source nature and active community have driven continuous improvements, with contributions from industry leaders and researchers.
- 2018 – MLflow was introduced by Databricks as a response to the growing complexity in managing ML workflows.
- Built to be framework-agnostic: works with TensorFlow, PyTorch, Scikit-learn, XGBoost, etc.
- Quickly became one of the most popular tools for ML lifecycle management.
Why is it Relevant in DataOps?
DataOps emphasizes collaboration, automation, and continuous delivery in data and ML workflows. MLflow aligns with these principles by:
- Automating Experiment Tracking: Centralizes metrics, parameters, and artifacts, reducing manual overhead.
- Enabling Reproducibility: Ensures consistent model training and evaluation across teams.
- Streamlining Deployment: Simplifies model deployment to production environments, aligning with CI/CD practices.
- Facilitating Collaboration: Provides a shared platform for data scientists, engineers, and DevOps teams to manage ML pipelines.
MLflow’s ability to integrate with tools like Kubernetes, AWS SageMaker, and Azure ML makes it a cornerstone for operationalizing ML in DataOps.
Core Concepts & Terminology
Key Terms and Definitions
- Experiment: A collection of runs, each representing a single execution of an ML model training process.
- Run: An instance of model training or evaluation, logging parameters, metrics, and artifacts.
- Model Registry: A centralized repository for versioning and managing ML models.
- Artifacts: Outputs of a run, such as trained models, datasets, or plots.
- Tracking Server: A server for storing and querying experiment data.
- Projects: Reproducible ML code packages with defined dependencies and entry points.
| Term | Definition |
|---|---|
| Experiment Tracking | Logging and querying experiments (parameters, metrics, artifacts). |
| MLflow Project | A reproducible ML package with defined environment and entry points. |
| MLflow Model | A standardized format for packaging ML models for deployment. |
| MLflow Registry | A centralized repository to manage model versions, lifecycle stages, and approvals. |
| Artifacts | Any files generated by ML runs (datasets, plots, models). |
How It Fits into the DataOps Lifecycle
The DataOps lifecycle includes data ingestion, preparation, modeling, deployment, and monitoring. MLflow contributes as follows:
- Data Preparation: Tracks data preprocessing steps as part of experiments.
- Modeling: Logs model parameters, metrics, and artifacts for reproducibility.
- Deployment: Packages models for deployment to cloud or on-premises environments.
- Monitoring: Integrates with monitoring tools to track model performance in production.
Architecture & How It Works
Components
MLflow consists of four main components:
- MLflow Tracking: Logs parameters, metrics, and artifacts during experiments. It supports local, file-based, or remote tracking servers.
- MLflow Projects: Packages ML code with dependencies for reproducibility across environments.
- MLflow Models: Standardizes model formats for deployment in various platforms (e.g., Docker, SageMaker).
- MLflow Registry: Manages model versions, staging, and production transitions.
Internal Workflow
- Experiment Creation: Users create an experiment to group related runs.
- Run Logging: During training, parameters (e.g., learning rate), metrics (e.g., accuracy), and artifacts (e.g., model files) are logged.
- Model Packaging: Trained models are saved in a standardized format with metadata.
- Deployment: Models are deployed via MLflow’s CLI or APIs to platforms like Kubernetes or cloud services.
- Monitoring: The tracking server provides insights into model performance and experiment history.
Architecture Diagram Description
The MLflow architecture can be visualized as:
- Client Layer: Users interact via Python APIs, CLI, or UI.
- Tracking Server: Stores experiment data in a backend (e.g., SQLite, PostgreSQL).
- Artifact Store: Stores large files like models (e.g., S3, Azure Blob Storage).
- Model Registry: Manages model versions and metadata.
- Deployment Targets: Integrates with cloud platforms, Kubernetes, or local servers.
+-------------------------------+
| Source Code & Data |
+-------------------------------+
|
+--------------------+
| MLflow Project | <-- Code Packaging
+--------------------+
|
+------------------------+
| MLflow Tracking Server | <-- Experiment Submission
+---+-----------+--------+
| |
+--------------+ +------------------+
| Parameters | | Metrics/Artifacts|
+--------------+ +------------------+
| |
+------------------+ +----------------------+
| MLflow Models | | Model Registry |
+------------------+ +----------------------+
| |
+----------------+ +-------------------+
| CI/CD Pipeline | | Cloud Deployments |
+----------------+ +-------------------+
Integration Points with CI/CD or Cloud Tools
- CI/CD: MLflow integrates with Jenkins, GitHub Actions, or GitLab CI to automate model training and deployment.
- Cloud Tools: Supports AWS SageMaker, Azure ML, and Google Cloud AI Platform for scalable deployment.
- Containerization: Models can be packaged as Docker containers for Kubernetes deployment.
Installation & Getting Started
Basic Setup or Prerequisites
- System Requirements: Python 3.7+, pip, and optionally a database (e.g., PostgreSQL) for tracking.
- Dependencies: Install MLflow via pip. For advanced setups, install a backend store (e.g., SQLite) and artifact storage (e.g., S3).
- Environment: A virtual environment (e.g., venv, conda) is recommended.
Hands-on: Step-by-Step Beginner-Friendly Setup Guide
- Install MLflow:
pip install mlflow2. Verify Installation:
mlflow --version3. Start the MLflow Tracking Server:
mlflow uiAccess the UI at http://localhost:5000.
4. Create a Simple Experiment:
import mlflow
import mlflow.sklearn
from sklearn.linear_model import LogisticRegression
from sklearn.datasets import load_iris
from sklearn.metrics import accuracy_score
# Set experiment
mlflow.set_experiment("Iris_Classification")
# Start a run
with mlflow.start_run():
# Load data
iris = load_iris()
X, y = iris.data, iris.target
# Train model
model = LogisticRegression(max_iter=100)
model.fit(X, y)
# Log parameters and metrics
mlflow.log_param("max_iter", 100)
mlflow.log_metric("accuracy", accuracy_score(y, model.predict(X)))
# Log model
mlflow.sklearn.log_model(model, "iris_model")5. View Results: Open the MLflow UI to see the experiment, parameters, and metrics.
6. Deploy Model (optional):
mlflow models serve -m runs:/<run_id>/iris_model -p 1234Replace <run_id> with the run ID from the UI.
Real-World Use Cases
1. Experiment Tracking in a Retail DataOps Pipeline
A retail company uses MLflow to track experiments for a demand forecasting model. Data scientists log parameters (e.g., time window, features) and metrics (e.g., RMSE) for multiple models. The MLflow UI enables the team to compare results and select the best model for deployment.
2. Model Deployment in Financial Services
A bank deploys a fraud detection model using MLflow’s model registry. The model is versioned, staged, and deployed to AWS SageMaker via MLflow’s CLI. CI/CD pipelines automate retraining and redeployment when new data arrives.
3. Collaborative ML in Healthcare
A healthcare research team uses MLflow to manage a disease prediction model. Data scientists log preprocessing steps and model artifacts, while engineers use the model registry to deploy the model to a Kubernetes cluster for real-time predictions.
4. A/B Testing in E-Commerce
An e-commerce platform uses MLflow to track A/B tests for recommendation models. Each model variant is logged as a separate run, with metrics like click-through rate and revenue tracked. The model registry facilitates switching between production models.
Benefits & Limitations
Key Advantages
- Reproducibility: Ensures experiments can be replicated with logged parameters and artifacts.
- Scalability: Supports large-scale deployments with cloud and container integration.
- Flexibility: Works with any ML framework (e.g., TensorFlow, PyTorch) and language.
- Collaboration: Centralizes experiment data for team access.
Common Challenges or Limitations
- Learning Curve: Setting up advanced features (e.g., remote tracking servers) requires expertise.
- Storage Overhead: Large artifact stores can increase costs in cloud environments.
- Limited Monitoring: MLflow focuses on experimentation and deployment, not real-time model monitoring.
- Community Dependency: Some features rely on community contributions, which may lag.
Best Practices & Recommendations
Security Tips
- Access Control: Use authentication for the MLflow tracking server (e.g., OAuth with cloud providers).
- Sensitive Data: Avoid logging sensitive data as parameters or metrics.
- Encryption: Store artifacts in encrypted storage (e.g., S3 with server-side encryption).
Performance
- Optimize Logging: Log only essential metrics to reduce overhead.
- Scalable Backend: Use a robust database (e.g., PostgreSQL) for tracking large experiments.
- Artifact Management: Clean up old artifacts to manage storage costs.
Maintenance
- Version Control: Use the model registry to track and archive model versions.
- Regular Updates: Keep MLflow and dependencies updated to leverage new features.
Compliance Alignment
- Audit Trails: Use MLflow’s logging to maintain audit trails for regulatory compliance (e.g., GDPR, HIPAA).
- Data Governance: Integrate with tools like Apache Atlas for metadata management.
Automation Ideas
- CI/CD Integration: Automate model training and deployment with GitHub Actions or Jenkins.
- Scheduled Retraining: Use cron jobs to trigger MLflow runs for model updates.
Comparison with Alternatives
| Feature | MLflow | Weights & Biases | Comet.ml |
|---|---|---|---|
| Tracking | Parameters, metrics, artifacts | Advanced visualization, real-time tracking | Comprehensive experiment tracking |
| Model Registry | Built-in, versioned models | Limited model management | Strong versioning and collaboration |
| Deployment | Cloud, Kubernetes, Docker | Limited deployment support | Cloud and on-premises deployment |
| Open Source | Yes | No (freemium model) | No (freemium model) |
| Ease of Use | Moderate learning curve | User-friendly UI | Intuitive for beginners |
| Cost | Free (self-hosted) | Paid for teams | Paid for advanced features |
When to Choose MLflow
- Open-Source Preference: Ideal for teams wanting a free, customizable solution.
- Deployment Flexibility: Best for projects requiring deployment to diverse platforms.
- Cross-Framework Needs: Suitable for teams using multiple ML frameworks.
Choose Weights & Biases for advanced visualization or Comet.ml for beginner-friendly interfaces and collaboration features.
Conclusion
MLflow is a powerful tool for operationalizing ML in DataOps, offering robust experiment tracking, model management, and deployment capabilities. Its integration with CI/CD and cloud platforms makes it a go-to choice for teams aiming to automate and scale ML workflows. As DataOps evolves, MLflow is likely to incorporate more real-time monitoring and AI-driven automation features.
Next Steps
- Explore the MLflow documentation for advanced features.
- Join the MLflow community for updates and contributions.
- Experiment with MLflow in a sandbox environment to test its integration with your DataOps pipeline.