Introduction & Overview
DataOps is a methodology that combines DevOps principles with data management to improve the speed, quality, and reliability of data analytics. At its core, ETL (Extract, Transform, Load) is a foundational process in DataOps, enabling organizations to collect, process, and store data efficiently. This tutorial provides a detailed exploration of ETL in the context of DataOps, covering its concepts, architecture, practical setup, use cases, and best practices.
What is ETL (Extract, Transform, Load)?
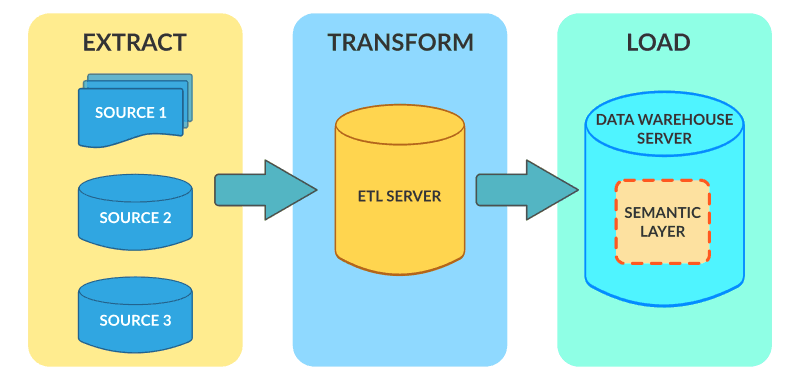
ETL is a data integration process that involves:
- Extract: Retrieving data from various sources, such as databases, APIs, or flat files.
- Transform: Cleaning, aggregating, or reformatting data to meet analytical or operational needs.
- Load: Storing the transformed data into a target system, such as a data warehouse or database.
History or Background
ETL originated in the 1970s with the rise of data warehousing, as businesses needed to consolidate data from disparate systems for reporting and analytics. Over time, ETL evolved with advancements in cloud computing, big data, and automation, becoming a cornerstone of modern DataOps practices.
Why is it Relevant in DataOps?
ETL is critical in DataOps because it:
- Enables data pipeline automation, aligning with DataOps’ focus on continuous integration and delivery.
- Supports data quality and governance, ensuring reliable analytics.
- Facilitates scalability in handling large, diverse datasets across hybrid or cloud environments.
Core Concepts & Terminology
Key Terms and Definitions
- Data Source: The origin of raw data (e.g., SQL databases, CSV files, APIs).
- Transformation Rules: Logic applied to clean, enrich, or reformat data (e.g., filtering, joining, aggregating).
- Data Target: The destination system where transformed data is stored (e.g., Snowflake, Redshift).
- Orchestration: Scheduling and managing ETL workflows using tools like Apache Airflow or dbt.
- Data Pipeline: The end-to-end flow of data through ETL processes.
| Term | Definition | Example |
|---|---|---|
| Extract | Pulling data from source systems | Pulling logs from Kafka, SQL database, APIs |
| Transform | Cleaning, validating, aggregating, enriching data | Converting timestamps, removing duplicates |
| Load | Storing transformed data in a target system | Loading into Snowflake or BigQuery |
| ETL vs. ELT | ELT loads data first and then transforms inside the warehouse | dbt, BigQuery |
| Batch Processing | Data processed in chunks | Nightly ETL jobs |
| Streaming ETL | Real-time continuous processing | Apache Kafka + Spark Streaming |
How ETL Fits into the DataOps Lifecycle
In DataOps, ETL integrates with the lifecycle stages:
- Plan: Designing ETL workflows to align with business requirements.
- Develop: Building and testing ETL pipelines using tools like Python or SQL.
- Integrate: Connecting ETL processes with CI/CD pipelines for version control and deployment.
- Monitor: Tracking ETL performance and data quality in production.
Architecture & How It Works
Components and Internal Workflow
An ETL pipeline consists of three main components:
- Extraction Layer: Connects to data sources via APIs, JDBC, or file readers to retrieve raw data.
- Transformation Layer: Applies business logic using tools like Python (Pandas), SQL, or Spark to clean and format data.
- Loading Layer: Writes transformed data to a target system, often using bulk loading or incremental updates.
Workflow:
- Extract raw data from sources (e.g., a MySQL database and a CSV file).
- Transform data by applying rules (e.g., removing duplicates, normalizing formats).
- Load the processed data into a data warehouse (e.g., Google BigQuery).
Architecture Diagram (Text Description)
Imagine a flowchart:
- Left: Data sources (e.g., CRM database, IoT sensors, REST APIs).
- Center: ETL engine (e.g., Apache NiFi, Talend) with transformation logic.
- Right: Data warehouse (e.g., Snowflake) or analytics platform.
- Arrows: Data flows from sources to the ETL engine, then to the target system.
- Orchestration Layer: Tools like Airflow schedule and monitor the pipeline.
[Data Sources] --> [Extract Layer] --> [Transform Layer] --> [Load Layer] --> [Data Warehouse/Lake]
| |
Monitoring Orchestration (Airflow)
Integration Points with CI/CD or Cloud Tools
- CI/CD: ETL scripts are versioned in Git, tested with tools like Great Expectations, and deployed via Jenkins or GitHub Actions.
- Cloud Tools: ETL integrates with cloud platforms like AWS Glue, Azure Data Factory, or Google Cloud Dataflow for scalable processing.
- Monitoring: Tools like Prometheus or Datadog track pipeline performance and errors.
Installation & Getting Started
Basic Setup or Prerequisites
To set up a basic ETL pipeline, you’ll need:
- Python 3.8+: For scripting ETL processes.
- Pandas: For data transformation.
- SQLAlchemy: For database connections.
- Apache Airflow: For orchestration (optional).
- Access to a data source: E.g., a MySQL database.
- Target system: E.g., PostgreSQL or a cloud data warehouse.
Install dependencies:
pip install pandas sqlalchemy mysql-connector-python apache-airflow
Hands-on: Step-by-Step Beginner-Friendly Setup Guide
This guide demonstrates a simple ETL pipeline using Python to extract data from a MySQL database, transform it, and load it into PostgreSQL.
- Set Up Databases:
- Ensure MySQL and PostgreSQL are running locally or in the cloud.
- Create a source table in MySQL:
CREATE TABLE sales (
id INT PRIMARY KEY,
product VARCHAR(50),
amount DECIMAL(10,2),
sale_date DATE
);
INSERT INTO sales VALUES (1, 'Laptop', 1000.00, '2025-08-01');Create a target table in PostgreSQL:
CREATE TABLE sales_summary (
product VARCHAR(50),
total_amount DECIMAL(10,2),
sale_month VARCHAR(7)
);2. Write the ETL Script:
import pandas as pd
from sqlalchemy import create_engine
# Step 1: Extract
source_engine = create_engine('mysql+mysqlconnector://user:password@localhost/source_db')
df = pd.read_sql('SELECT * FROM sales', source_engine)
# Step 2: Transform
df['sale_month'] = df['sale_date'].dt.strftime('%Y-%m')
df_summary = df.groupby(['product', 'sale_month'])['amount'].sum().reset_index()
df_summary.rename(columns={'amount': 'total_amount'}, inplace=True)
# Step 3: Load
target_engine = create_engine('postgresql://user:password@localhost/target_db')
df_summary.to_sql('sales_summary', target_engine, if_exists='append', index=False)3. Run the Script:
python etl_script.py4. Verify the Output:
Check the sales_summary table in PostgreSQL for the transformed data.
Real-World Use Cases
1. E-commerce Analytics
- Scenario: An online retailer extracts order data from a MySQL database, transforms it to calculate monthly revenue by product category, and loads it into Snowflake for reporting.
- Tools: AWS Glue for ETL, Snowflake as the target, Airflow for orchestration.
2. Healthcare Data Integration
- Scenario: A hospital extracts patient records from multiple systems (e.g., EHR, billing), transforms them to standardize formats, and loads them into a data lake for compliance reporting.
- Tools: Talend for ETL, Azure Data Lake as the target.
3. IoT Data Processing
- Scenario: A smart city project extracts sensor data from IoT devices, transforms it to detect anomalies, and loads it into BigQuery for real-time analytics.
- Tools: Google Cloud Dataflow for ETL, BigQuery as the target.
4. Financial Reporting
- Scenario: A bank extracts transaction data from APIs, transforms it to comply with regulatory formats, and loads it into Redshift for audit purposes.
- Tools: Informatica for ETL, Amazon Redshift as the target.
Benefits & Limitations
Key Advantages
- Scalability: Handles large datasets with cloud-based ETL tools.
- Automation: Integrates with orchestration tools for scheduled pipelines.
- Data Quality: Ensures clean, consistent data for analytics.
Common Challenges or Limitations
- Complexity: Designing transformations for diverse data sources can be time-consuming.
- Performance: Large-scale ETL jobs may face latency issues without optimization.
- Cost: Cloud ETL tools can incur high costs for big data workloads.
| Aspect | Advantage | Limitation |
|---|---|---|
| Scalability | Handles petabytes of data | Requires optimization for performance |
| Cost | Free tools like Python available | Cloud tools can be expensive |
| Flexibility | Supports diverse sources | Complex transformations need expertise |
Best Practices & Recommendations
Security Tips
- Use encrypted connections (e.g., SSL/TLS) for data extraction and loading.
- Implement role-based access control (RBAC) for data sources and targets.
- Mask sensitive data (e.g., PII) during transformation.
Performance
- Use incremental loading to process only new or changed data.
- Parallelize transformations with tools like Apache Spark.
- Optimize SQL queries with indexing and partitioning.
Maintenance
- Monitor pipelines with logging and alerting (e.g., Airflow’s UI or Datadog).
- Version ETL scripts in Git for traceability.
- Document transformation logic for team collaboration.
Compliance Alignment
- Ensure GDPR/HIPAA compliance by anonymizing sensitive data.
- Audit ETL pipelines regularly for data lineage and traceability.
Automation Ideas
- Use CI/CD pipelines (e.g., Jenkins) to deploy ETL scripts.
- Automate testing with tools like Great Expectations for data validation.
Comparison with Alternatives
ETL vs. ELT (Extract, Load, Transform)
- ETL: Transforms data before loading; suitable for structured data and on-premises systems.
- ELT: Loads raw data first, then transforms in the target system; ideal for cloud data warehouses with high compute power.
| Feature | ETL | ELT |
|---|---|---|
| Transformation | Before loading | After loading |
| Speed | Slower for large datasets | Faster with cloud compute |
| Use Case | Legacy systems, structured data | Big data, cloud-native |
When to Choose ETL
- Use ETL for structured data with well-defined transformation rules.
- Choose ETL when data security requires transformations before loading.
- Opt for ETL in hybrid environments with on-premises and cloud systems.
Conclusion
ETL remains a cornerstone of DataOps, enabling organizations to build robust, automated, and scalable data pipelines. As DataOps evolves, ETL is adapting with cloud-native tools, real-time processing, and AI-driven transformations. To get started, explore tools like Apache Airflow, AWS Glue, or Talend, and experiment with the hands-on example provided.
Next Steps:
- Experiment with cloud ETL tools for scalability.
- Explore orchestration tools to automate pipelines.
- Stay updated on emerging trends like real-time ETL and AI-driven data transformations.