Introduction & Overview
In the rapidly evolving landscape of data management, organizations strive to make data actionable across their operational systems. Reverse Extract, Transform, Load (Reverse ETL) has emerged as a pivotal process within the DataOps framework, enabling businesses to bridge the gap between data warehouses and operational tools. This tutorial provides an in-depth exploration of Reverse ETL, its integration into DataOps, and practical guidance for implementation. Designed for technical readers, including data engineers, analysts, and DataOps professionals, this guide covers core concepts, setup, use cases, benefits, limitations, and best practices.
What is Reverse ETL?
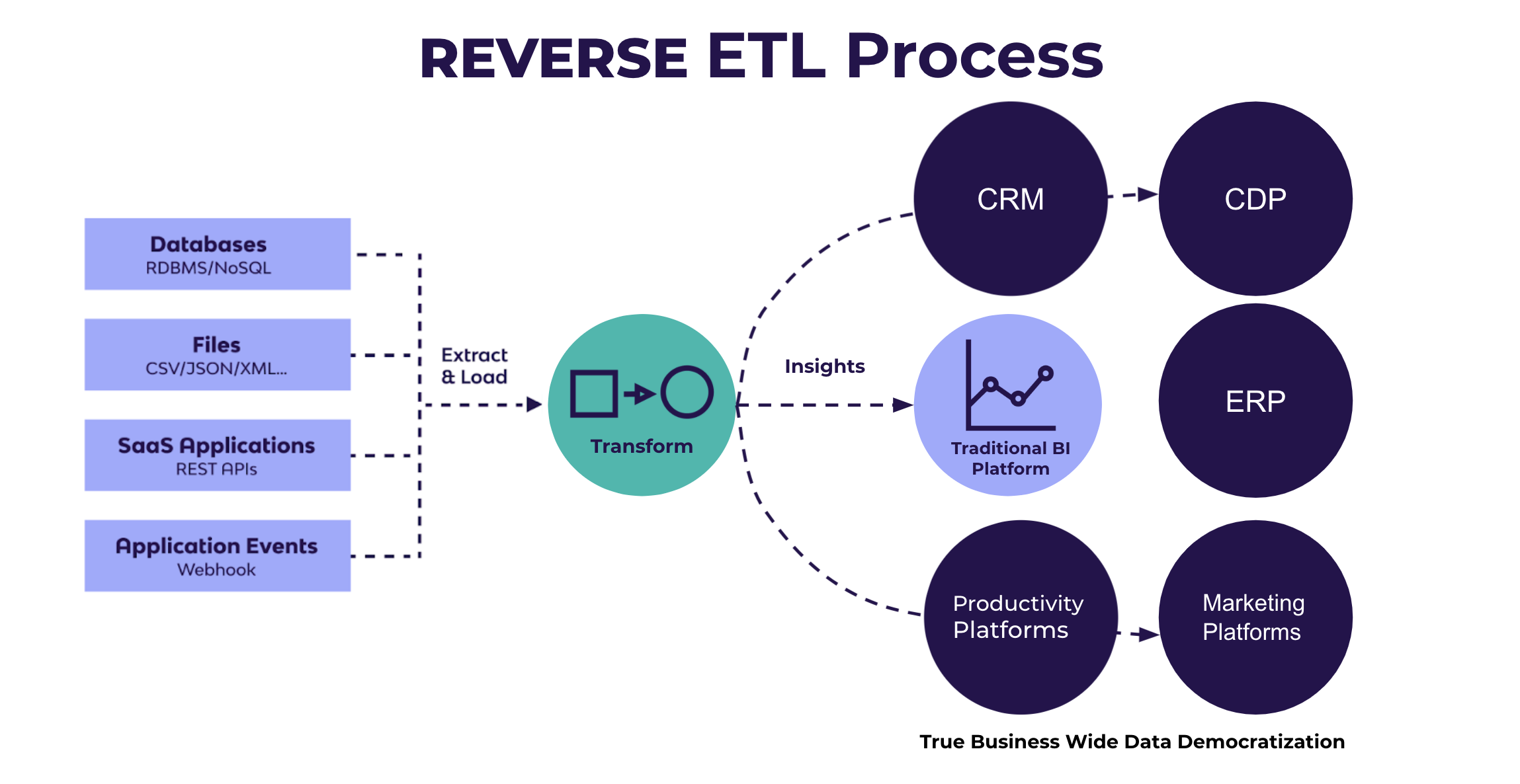
Reverse ETL is a data integration process that extracts transformed data from a centralized data warehouse or data lake and loads it into operational systems such as Customer Relationship Management (CRM) platforms, marketing tools, or other Software-as-a-Service (SaaS) applications. Unlike traditional ETL, which moves data from source systems to a warehouse for analysis, Reverse ETL reverses this flow, operationalizing insights by syncing enriched data back to business tools for real-time use.
History or Background
The concept of Reverse ETL emerged in the late 2010s as cloud data warehouses like Snowflake, Google BigQuery, and Databricks gained prominence. Traditional ETL processes centralized data for analytics but left a gap in delivering insights to operational teams. Around 2018, tools like Census and Hightouch introduced Reverse ETL to address this, enabling non-technical teams to leverage warehouse data in daily workflows. By 2021, Reverse ETL became a cornerstone of the modern data stack, driven by the need for real-time, data-driven decision-making.
Why is it Relevant in DataOps?
DataOps, a methodology that applies agile practices to data management, emphasizes collaboration, automation, and continuous delivery of data insights. Reverse ETL aligns with DataOps by:
- Enabling Collaboration: It democratizes data access, allowing business teams to use warehouse insights without relying on data engineers.
- Supporting Automation: Automated syncs streamline data delivery to operational tools, reducing manual effort.
- Enhancing Agility: Real-time data integration supports rapid decision-making, a core DataOps principle.
- Closing the Analytics-Operations Gap: Reverse ETL ensures analytics inform operational actions, completing the data lifecycle.
Core Concepts & Terminology
Key Terms and Definitions
- Data Warehouse: A centralized repository (e.g., Snowflake, BigQuery) storing transformed data for analytics.
- Operational Systems: Business tools like Salesforce, HubSpot, or Slack where data is used for daily operations.
- Connectors: Pre-built integrations that facilitate data transfer between warehouses and operational tools.
- SQL Models: Queries or scripts that define and structure data for extraction from the warehouse.
- Data Mapping: The process of aligning warehouse data fields with the schema of destination systems.
- Sync Mechanisms:
- Mirror Sync: Replicates warehouse data exactly in the destination, including updates and deletions.
- Upsert Sync: Inserts new records and updates existing ones without deleting data.
- Operational Analytics: Using warehouse insights in operational systems for real-time actions.
| Term | Definition | Example |
|---|---|---|
| Source of Truth | Central data warehouse storing cleansed, modeled data. | Snowflake, BigQuery |
| Operational System | Business tool where end users take action. | Salesforce, HubSpot |
| Sync | Data pipeline that moves warehouse data into SaaS tools. | Customer attributes into Salesforce |
| Data Activation | Making analytics actionable in downstream apps. | Sending churn prediction scores to CRM |
How it Fits into the DataOps Lifecycle
The DataOps lifecycle includes data ingestion, transformation, analysis, and delivery. Reverse ETL operates at the delivery stage, taking transformed data from the warehouse and syncing it to operational systems. It integrates with:
- Data Ingestion: Leverages ETL/ELT pipelines that populate the warehouse.
- Transformation: Uses SQL models to prepare data for operational use.
- Delivery: Automates data syncs to business tools, ensuring insights are actionable.
- Monitoring: Incorporates observability to track sync success and data quality.
Architecture & How It Works
Components and Internal Workflow
Reverse ETL systems consist of:
- Source: The data warehouse or lake (e.g., Snowflake, Databricks) containing cleaned, transformed data.
- Models: SQL queries or scripts defining data to extract, often using tools like dbt for transformation.
- Connectors: APIs or plugins connecting the warehouse to destinations like CRMs or marketing platforms.
- Sync Mechanisms: Processes (mirror or upsert) that determine how data is transferred.
- Destinations: Operational tools like Salesforce, Marketo, or Slack receiving the data.
- Monitoring Tools: Systems to track sync status, errors, and data quality.
Workflow:
- Extraction: SQL models query the warehouse to extract relevant data (e.g., customer segments, KPIs).
- Transformation: Data is lightly transformed (e.g., reformatted) to match destination schemas.
- Mapping: Fields are mapped to ensure compatibility with destination systems.
- Loading: Data is synced to operational tools via connectors, either in real-time or on a schedule.
- Monitoring: Syncs are logged, and errors (e.g., API failures) are flagged for resolution.
Architecture Diagram Description
Imagine a diagram with:
- A central Data Warehouse (e.g., Snowflake) at the core.
- ETL/ELT Pipelines feeding raw data from sources (databases, apps) into the warehouse.
- SQL Models (via dbt) transforming data within the warehouse.
- Reverse ETL Platform (e.g., Census, Hightouch) connecting the warehouse to destinations.
- Connectors as arrows pointing to destinations like Salesforce, HubSpot, and Slack.
- Monitoring Layer (logs, alerts) overseeing the sync process.
[Data Sources] → [ETL] → [Data Warehouse] → [Reverse ETL] → [CRM / Marketing / Support]
↑
[Monitoring & Orchestration]
Integration Points with CI/CD or Cloud Tools
- CI/CD: Reverse ETL integrates with CI/CD pipelines via tools like dbt for version-controlled SQL models, enabling automated testing and deployment of data transformations.
- Cloud Tools: Platforms like AWS, Google Cloud, or Azure host warehouses and Reverse ETL tools, with connectors leveraging cloud APIs for seamless data transfer.
- Orchestration: Tools like Apache Airflow or Dagster schedule and monitor Reverse ETL syncs, ensuring reliability.
Installation & Getting Started
Basic Setup or Prerequisites
To set up Reverse ETL, you need:
- A Data Warehouse (e.g., Snowflake, BigQuery) with transformed data.
- A Reverse ETL Tool (e.g., Census, Hightouch, Matillion).
- Destination Tools with API access (e.g., Salesforce, HubSpot).
- SQL Knowledge for creating models.
- Access Credentials for warehouse and destination systems.
- A Version Control System (e.g., Git) for managing SQL models (optional but recommended).
Hands-On: Step-by-Step Beginner-Friendly Setup Guide
This guide uses Census with Snowflake and Salesforce as an example.
- Set Up Snowflake Access:
- Ensure you have a Snowflake account with a populated database.Create a user with read access to the target schema.
GRANT USAGE ON DATABASE my_db TO ROLE reverse_etl_role;
GRANT SELECT ON SCHEMA my_db.public TO ROLE reverse_etl_role;2. Sign Up for Census:
- Create an account at
app.getcensus.com. - Connect Census to Snowflake:
- Navigate to “Connections” > “Add Source” > Select “Snowflake.”
- Enter Snowflake credentials (host, username, password, database, schema).
3. Define a SQL Model:
- In Census, create a model to extract customer data.
SELECT
customer_id,
first_name,
last_name,
lifetime_value,
churn_risk_score
FROM my_db.public.customers
WHERE last_updated >= CURRENT_DATE - INTERVAL '1 day';4. Connect to Salesforce:
- In Census, go to “Destinations” > “Add Destination” > Select “Salesforce.”
- Authenticate using Salesforce OAuth or API token.
- Map model fields to Salesforce fields (e.g.,
customer_idtoId,lifetime_valuetoCustomer_LTV__c).
5. Configure Sync:
- Create a sync in Census, selecting the SQL model and Salesforce destination.
- Choose sync type (Mirror or Upsert) and schedule (e.g., hourly).
- Test the sync to ensure data flows correctly.
6. Monitor and Validate:
- Check Census logs for sync status and errors.
- Verify data in Salesforce to confirm accurate transfer.
Real-World Use Cases
- Marketing Campaign Personalization:
- Scenario: A retail company uses Reverse ETL to sync customer segmentation data from Snowflake to Braze for personalized email campaigns.
- Implementation: SQL models calculate customer lifetime value and recent purchases, syncing these to Braze to target high-value customers with tailored offers.
- Industry: E-commerce.
- Impact: Increased campaign ROI by 25% through precise targeting.
- Sales Lead Prioritization:
- Scenario: A SaaS company syncs lead scores from BigQuery to Salesforce, enabling sales reps to prioritize high-potential leads.
- Implementation: A SQL model ranks leads based on engagement data, and Reverse ETL pushes these scores to Salesforce custom fields.
- Industry: Technology.
- Impact: Improved conversion rates by 20% due to focused outreach.
- Customer Support Enhancement:
- Scenario: A telecom company syncs customer interaction data from Databricks to Zendesk, providing support agents with real-time usage insights.
- Implementation: Reverse ETL extracts usage patterns and syncs them to Zendesk, enabling agents to address issues proactively.
- Industry: Telecommunications.
- Impact: Reduced resolution time by 15%.
- Inventory Management:
Benefits & Limitations
Key Advantages
- Real-Time Actionability: Enables immediate use of insights in operational tools, enhancing decision-making.
- Reduced Manual Effort: Automates data delivery, eliminating manual exports and reducing errors.
- Data Democratization: Makes warehouse data accessible to non-technical teams, fostering collaboration.
- Improved ROI: Maximizes the value of data infrastructure by operationalizing insights.
Common Challenges or Limitations
- Complexity in Mapping: Aligning warehouse schemas with destination systems can be time-consuming.
- API Limitations: Destination tools may have rate limits, affecting sync frequency.
- Cost: Mirror syncs can be resource-intensive, increasing operational costs.
- Data Governance: Ensuring compliance across multiple systems requires robust security measures.
Best Practices & Recommendations
- Security Tips:
- Performance:
- Optimize SQL models to reduce query latency, using indexing and partitioning in the warehouse.
- Schedule syncs during low-traffic periods to avoid API rate limits.
- Maintenance:
- Compliance Alignment:
- Ensure Reverse ETL tools adhere to regulatory standards (e.g., SOC 2, PCI DSS).
- Use audit logs to track data flows and demonstrate compliance.
- Automation Ideas:
- Integrate with CI/CD pipelines using dbt and Git for version-controlled models.
- Use orchestration tools like Airflow to automate sync schedules.
Comparison with Alternatives
| Feature | Reverse ETL | iPaaS (e.g., Zapier) | CDP (e.g., Segment) |
|---|---|---|---|
| Data Flow | Warehouse to operational tools | Bidirectional between apps | Sources to warehouse/marketing |
| Primary Use | Operationalizing insights | Point-to-point integrations | Customer data unification |
| Transformation | SQL-based, flexible | Limited, trigger-based | Limited, customer-focused |
| Scalability | High, warehouse-centric | Limited by pipeline complexity | Moderate, customer data focus |
| Use Case | Syncing KPIs, segments to tools | App-to-app automation | Marketing campaign data |
| Complexity | Moderate, requires SQL | Low, no-code | High, setup-intensive |
When to Choose Reverse ETL:
- Use Reverse ETL when you need to operationalize warehouse data across multiple business tools.
- Choose iPaaS for simple, trigger-based app integrations.
- Opt for CDPs when focusing on customer data for marketing purposes.
Conclusion
Reverse ETL is a transformative component of DataOps, enabling organizations to operationalize data warehouse insights in real-time. By bridging analytics and operations, it empowers teams to make data-driven decisions, streamline workflows, and enhance customer experiences. As data volumes grow and real-time demands intensify, Reverse ETL will continue to evolve, with trends like AI-driven transformations and enhanced observability shaping its future.
Next Steps:
- Explore tools like Census, Hightouch, or Matillion for implementation.
- Experiment with the setup guide provided above.
- Join communities like the DataOps Slack or dbt Community for insights.