1. Introduction & Overview
What is Data Orchestration?
Data orchestration is the automated process of organizing, coordinating, and managing data workflows across disparate systems and environments. In essence, it enables the seamless movement and transformation of data from one point to another while maintaining security, scalability, and compliance. Within a DevSecOps framework, it ensures that data used in the CI/CD lifecycle is handled securely, efficiently, and automatically.
History or Background
- Emerged from the need to unify siloed data systems across cloud, on-premises, and hybrid environments.
- Gained traction with the rise of data lakes, distributed computing (e.g., Apache Spark), and multi-cloud architectures.
- Tools like Apache Airflow, Prefect, and Dagster became popular orchestration engines.
- Evolved into a security-sensitive practice with DevSecOps, emphasizing automation, auditability, and compliance.
Why is it Relevant in DevSecOps?
- Security Integration: Sensitive data is automatically encrypted, masked, or redacted during movement or transformation.
- Compliance Automation: Enables enforcement of GDPR, HIPAA, SOC2 policies throughout the pipeline.
- Operational Efficiency: Automates data provisioning for testing, monitoring, and analytics tools used in DevSecOps.
- Audit Trails: Maintains traceability and versioning for regulatory compliance and debugging.
2. Core Concepts & Terminology
Key Terms and Definitions
| Term | Definition |
|---|---|
| Data Pipeline | A sequence of data processing steps from source to destination. |
| Orchestrator | The engine or tool that schedules and coordinates data workflows. |
| Task DAG (Directed Acyclic Graph) | A graph where each node is a task and edges define dependencies. |
| ETL/ELT | Extract, Transform, Load (or Load first, then transform). |
| Metadata Management | Capturing info about data lineage, quality, and compliance. |
| Airflow Operator/Task | Units of execution within orchestration tools like Apache Airflow. |
How It Fits into the DevSecOps Lifecycle
| DevSecOps Phase | Orchestration Role |
|---|---|
| Plan | Manage metadata and source data lineage. |
| Develop | Automatically provision dev/test data securely. |
| Build | Run data validation scripts, trigger data quality checks. |
| Test | Feed masked datasets to automated testing pipelines. |
| Release | Coordinate analytics reports on release quality. |
| Deploy | Trigger data monitoring alerts based on logs/metrics. |
| Operate | Continuous ingestion of metrics and compliance data. |
| Monitor | Feed anomaly detection tools with log and usage data. |
3. Architecture & How It Works
Components
- Scheduler: Controls the frequency of workflow executions (e.g., cron-based).
- Executor: Executes tasks in parallel or sequentially using worker nodes.
- Metadata Database: Tracks the status of tasks, logs, and versioning.
- Worker Nodes: Machines or containers that process the data.
- APIs/Connectors: Interface to connect to databases, cloud services, file systems.
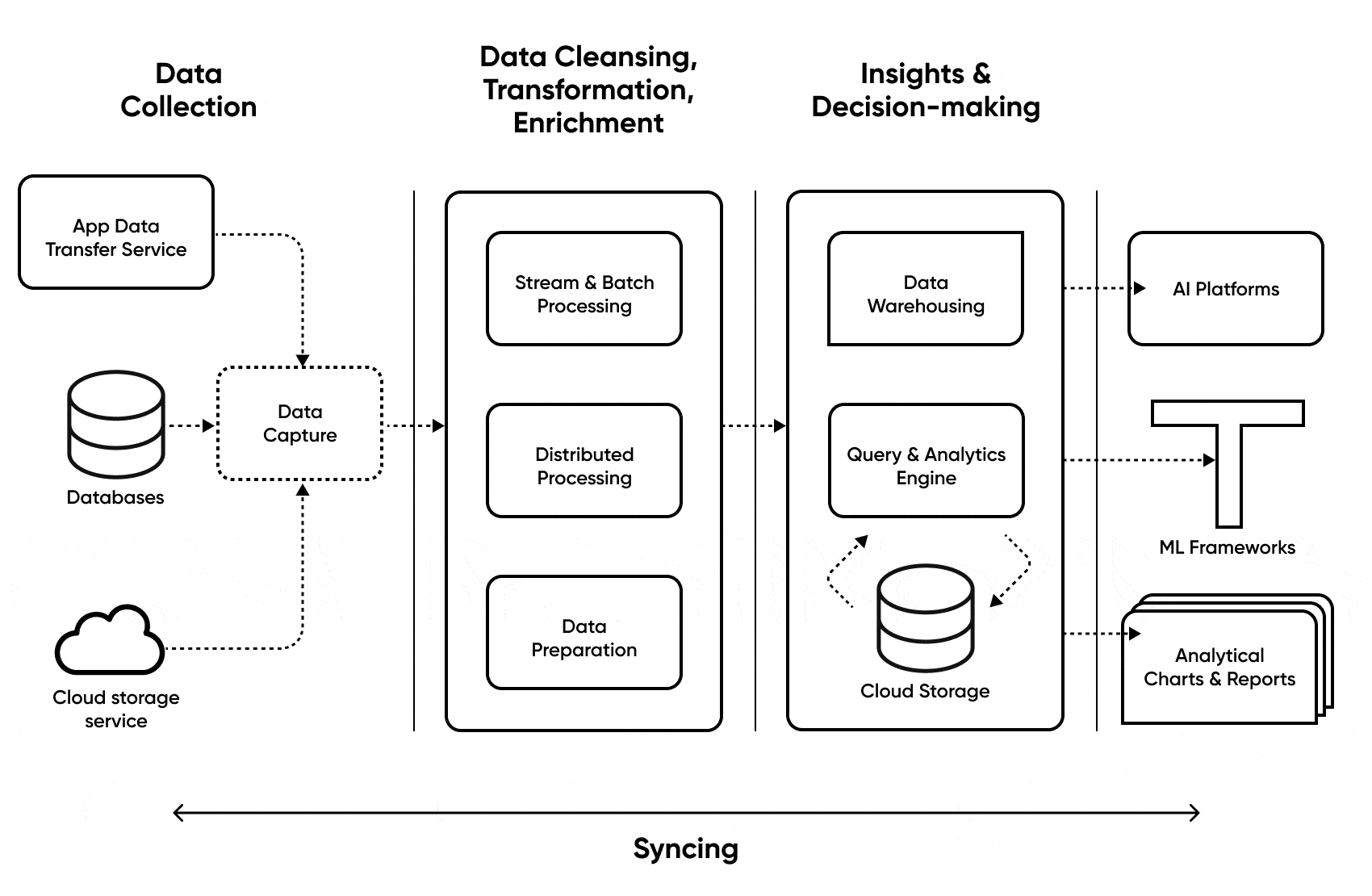
Internal Workflow
- Workflow Definition: A YAML/Python/DAG file defines tasks and dependencies.
- Scheduling: The orchestrator checks schedules and dependency satisfaction.
- Task Execution: Tasks are executed in defined order; logs are captured.
- Error Handling: On failure, retries, notifications, or compensations are triggered.
- Logging & Monitoring: Each step’s status is logged and monitored.
Architecture Diagram (Textual Description)
[Source Data] --> [Ingestion Task] --> [Transformation Task] --> [Validation Task] --> [Destination Storage]
| ↑
| [Metadata Logging & Alerting] <--------|
↓
[Scheduler] ---> [Executor] ---> [Worker Nodes] ---> [APIs/Connectors]
Integration Points with CI/CD or Cloud Tools
| Tool/Service | Integration Purpose |
|---|---|
| GitHub Actions | Trigger DAGs from commits or pull requests. |
| Jenkins | Schedule and monitor data pipelines. |
| Kubernetes (K8s) | Run orchestrator in a scalable, containerized setup. |
| AWS S3 / GCP Storage | Store raw/intermediate/final data. |
| Terraform | Provision orchestration infra as code. |
| Vault / AWS KMS | Secure credentials and secrets used in pipelines. |
4. Installation & Getting Started
Basic Setup or Prerequisites
- Python 3.8+
- Docker & Docker Compose
- Git
- PostgreSQL (for Airflow metadata DB)
- Cloud provider credentials (optional)
Hands-On: Step-by-Step Guide (Using Apache Airflow)
# Step 1: Clone Airflow docker example
git clone https://github.com/apache/airflow.git
cd airflow
cp .env.example .env
# Step 2: Initialize environment
docker-compose up airflow-init
# Step 3: Start services
docker-compose up -d
# Step 4: Access Airflow UI
# Visit http://localhost:8080
# Login: admin / admin
# Step 5: Create a simple DAG
vim dags/simple_pipeline.py
Example DAG (simple_pipeline.py)
from airflow import DAG
from airflow.operators.bash import BashOperator
from datetime import datetime
with DAG(dag_id="simple_pipeline", start_date=datetime(2023,1,1), schedule_interval='@daily') as dag:
task1 = BashOperator(task_id="extract", bash_command="echo 'Extracting data'")
task2 = BashOperator(task_id="transform", bash_command="echo 'Transforming data'")
task3 = BashOperator(task_id="load", bash_command="echo 'Loading data'")
task1 >> task2 >> task3
5. Real-World Use Cases
1. Secure Data Provisioning for Testing
- Use masked production data for CI test environments.
- Redact PII using orchestration tasks before loading to staging.
2. Automated Compliance Reporting
- Daily jobs extract logs and generate GDPR/SOC2 reports.
- Alert security teams via Slack if anomalies found.
3. Anomaly Detection in Application Logs
- Collect app logs, enrich with context (e.g., user agent), and feed into ML detection models.
4. Cloud Cost Optimization
- Periodic aggregation of cloud billing data.
- Run transformations and trigger reports to FinOps dashboard.
6. Benefits & Limitations
Key Advantages
- ✅ Automation: Reduces human error and operational overhead.
- ✅ Security: Enables encryption, tokenization, and controlled access.
- ✅ Auditability: Logs every step for traceability.
- ✅ Scalability: Runs complex workflows in cloud-native environments.
- ✅ Flexibility: Integrates easily with CI/CD and cloud systems.
Common Challenges
- ❌ Complex Setup: Initial deployment and configuration can be non-trivial.
- ❌ Debugging DAGs: Troubleshooting failures in multi-step pipelines can be hard.
- ❌ Latency: For real-time systems, batch orchestration may not suffice.
- ❌ Security Misconfigurations: Improper IAM or secret management can lead to data leaks.
7. Best Practices & Recommendations
Security Tips
- Use secrets managers (e.g., HashiCorp Vault, AWS Secrets Manager).
- Apply principle of least privilege on connectors and storage buckets.
- Encrypt data in-transit and at-rest.
Performance Tips
- Use task parallelism where possible.
- Monitor DAG runtimes and optimize slow tasks.
Maintenance
- Regularly update orchestrator versions and plugins.
- Clean up failed tasks and metadata to avoid bloat.
Compliance Alignment
- Tag tasks/data with classifications (e.g., PII, PCI).
- Automate compliance checklists using orchestration outputs.
8. Comparison with Alternatives
| Tool | Pros | Cons | Best For |
|---|---|---|---|
| Airflow | Mature, extensible, wide community | Steep learning curve | General-purpose workflows |
| Prefect | Pythonic, modern UI, good error handling | Less community adoption | Developer-friendly flows |
| Dagster | Strong data typing and observability | Still maturing | Data-focused teams |
| AWS Step Functions | Serverless, deep AWS integration | Vendor lock-in | AWS-native workflows |
When to Choose Data Orchestration
- If your DevSecOps workflows depend on timely, secure, and consistent data movement.
- When compliance and audit trails for data are mandatory.
- If CI/CD pipelines require real-world data for testing or monitoring purposes.
9. Conclusion
Data orchestration plays a vital role in modern DevSecOps by enabling secure, automated, and observable data workflows. As organizations move towards data-driven DevSecOps models, integrating orchestration ensures compliance, boosts performance, and reduces manual toil.
Next Steps:
- Try setting up Airflow or Prefect in your DevSecOps pipeline.
- Audit your current data flows for orchestration opportunities.
Resources
Category: