DataOps is a methodology that blends Agile practices, DevOps principles, and lean data management to streamline the end-to-end data lifecycle. It emphasizes collaboration between data engineers, analysts, scientists, and operations teams to deliver high-quality, secure, and timely data analytics. By automating workflows, enforcing governance, and enabling continuous delivery, DataOps ensures data pipelines are fast, reliable, and compliant.
History or Background
2014: The term “DataOps” was introduced by Lenny Liebmann, highlighting the need for agile data management.
2017–2020: Adoption surged with the rise of cloud-native data platforms (e.g., Snowflake, Databricks) and stricter regulations like GDPR and CCPA.
2021–2025: DataOps matured with AI-driven automation, serverless architectures, and tighter integration with DevSecOps, driven by the demand for real-time analytics and generative AI pipelines.
Why is it Relevant in DevSecOps?
DataOps aligns with DevSecOps by:
Embedding security and compliance into data pipelines via automated audits and encryption.
Enabling continuous testing and deployment of data workflows with CI/CD integration.
Providing observability for data health, lineage, and access, ensuring traceability in regulated environments.
Bridging data governance with software development, reducing silos in secure data delivery.
2. Core Concepts & Terminology
Key Terms and Definitions
Term
Definition
Data Pipeline
Automated processes to ingest, transform, and deliver data from source to target.
DataOps
A methodology combining DevOps, Agile, and data management for analytics agility.
Orchestration
Automated scheduling and management of data pipeline tasks.
Data Drift
Unintended changes in data structure, schema, or distribution over time.
Data Observability
Monitoring data pipeline health, quality, and lineage for proactive issue detection.
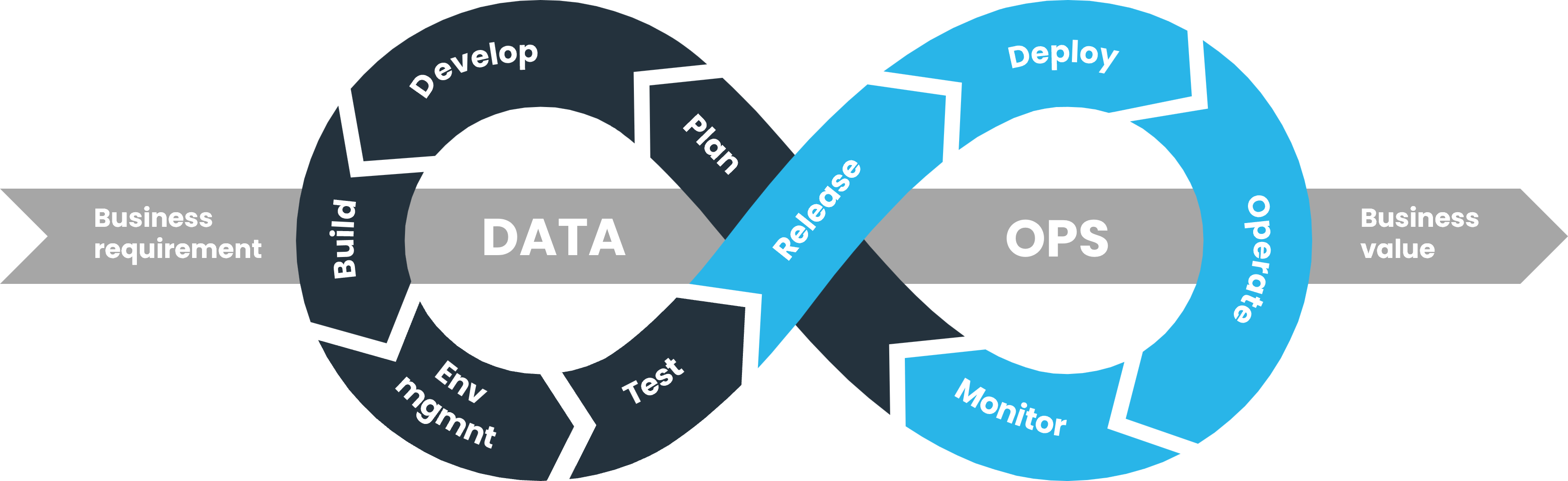
How It Fits into the DevSecOps Lifecycle
DevSecOps Stage
DataOps Integration
Plan
Define data schemas, compliance requirements, and security policies.
Develop
Version control for data pipelines, transformations, and metadata using GitOps.
Build
Automate data quality checks and schema validation in CI pipelines.
Test
Run automated tests for data integrity, security, and compliance.
Release
Deploy data pipelines via CI/CD with audit trails and rollback capabilities.
Operate
Monitor data SLAs, performance, and anomalies in production environments.
Monitor
Use observability tools to detect data drift, breaches, or pipeline failures.
3. Architecture & How It Works
Components of a DataOps Architecture
Data Sources: Structured (SQL databases), unstructured (logs, IoT), or streaming (APIs, Kafka).
Ingestion Layer: Tools like Apache Kafka, Fivetran, or AWS Glue for real-time or batch data ingestion.
Storage & Lakehouse: Cloud-native solutions like Databricks Delta Lake, Snowflake, or Google BigQuery.
Transformation Layer: dbt, Apache Spark, or SQL-based tools for data modeling and ETL/ELT.
Testing & Validation: Great Expectations, Soda, or Monte Carlo for data quality and integrity checks.
Orchestration: Apache Airflow, Prefect, or Dagster for workflow automation.
CI/CD Integration: GitHub Actions, GitLab CI, or Azure DevOps for pipeline deployment.
Monitoring & Observability: Tools like Monte Carlo, Databand, or Prometheus for real-time insights.
Security & Compliance: HashiCorp Vault, AWS IAM, or Apache Ranger for access control and encryption.
Internal Workflow
Data or code changes are committed to a Git repository.
CI/CD pipelines trigger automated tests for data quality, schema, and security compliance.
Validated pipelines are deployed to staging, then production, using orchestration tools.
Observability tools monitor data health, performance, and compliance in real time.
Alerts and logs feed into DevSecOps dashboards or SIEM systems for unified monitoring.
Software: Git, Python 3.10+, Docker, and a cloud provider account (AWS/GCP/Azure).
Tools: dbt, Apache Airflow, Great Expectations, and a cloud data platform (e.g., Snowflake).
Access: Cloud credentials with IAM roles for secure data access.
Step-by-Step: DataOps with Airflow + dbt + Great Expectations
# Step 1: Clone a DataOps template repository
git clone https://github.com/dataops-examples/starter-kit.git
cd starter-kit
# Step 2: Launch Dockerized environment (Airflow, Postgres, dbt, Great Expectations)
docker-compose up -d
# Step 3: Execute dbt transformations
cd dbt/
dbt run --profiles-dir .
# Step 4: Validate data with Great Expectations
cd ../great_expectations/
great_expectations checkpoint run my_data_checkpoint
# Step 5: Access Airflow UI for orchestration
# Open browser to http://localhost:8080
Notes
Ensure Docker has sufficient resources (4GB RAM, 2 CPUs recommended).
Configure cloud credentials in docker-compose.yml or environment variables.
Check Airflow DAGs for pipeline status and logs.
5. Real-World Use Cases
Use Case 1: Healthcare Data Pipeline with Compliance
Scenario: A hospital builds a secure data lake for patient analytics.
Toolchain: Apache Airflow, dbt, AWS Lake Formation, Monte Carlo.
Value: HIPAA-compliant ETL pipelines with automated PII masking, lineage tracking, and audit logs.
Use Case 2: Real-Time Financial Fraud Detection
Scenario: A bank processes streaming transaction data to detect fraud.
Toolchain: Kafka, Spark Streaming, Amazon Redshift, Great Expectations.
Value: Real-time anomaly detection with DevSecOps-integrated monitoring and compliance checks.
Use Case 3: Retail Analytics with GDPR Compliance
Scenario: A retailer transforms customer data for personalized marketing.
Toolchain: Airflow, dbt, Snowflake, Soda.
Value: GDPR-compliant pipelines with data quality validation and automated masking for BI dashboards.
Use Case 4: AI Model Feature Engineering
Scenario: A tech company automates feature pipelines for generative AI models.
📉 Maturity: Success depends on organizational data readiness.
7. Best Practices & Recommendations
Security, Performance, Maintenance
Encrypt sensitive data at rest and in transit using AES-256 or higher.
Implement RBAC and least-privilege access with tools like AWS IAM or Apache Ranger.
Use immutable data lakes to preserve raw data integrity.
Compliance & Automation
Automate data lineage with tools like Marquez or OpenLineage for auditability.
Enforce schema validation and data contracts in CI/CD pipelines.
Integrate with SIEM systems (e.g., Splunk, Datadog) for compliance monitoring.
Maintenance
Define SLAs/SLOs for pipeline uptime, latency, and data freshness.
Rotate secrets automatically using AWS Secrets Manager or Vault.
Schedule regular pipeline reviews to optimize performance and costs.
8. Comparison with Alternatives
Feature
DataOps
DevOps
MLOps
Focus
Data pipelines & analytics
Code & app deployment
ML model lifecycle
Data Quality
✅ Native
❌ Minimal
✅ Optional
Security
✅ Integrated
✅ Integrated
✅ Integrated
Observability
High
Moderate
High
Tools
dbt, Airflow, Great Expectations
Jenkins, ArgoCD
MLflow, Kubeflow
When to Choose DataOps
Your workflows involve heavy ETL, analytics, or BI reporting.
Compliance (e.g., GDPR, HIPAA) and data governance are critical.
You need scalable, secure, and observable data pipelines.
9. Conclusion
Final Thoughts
DataOps is a transformative approach that aligns data management with DevSecOps principles, enabling organizations to deliver secure, high-quality data pipelines at scale. By automating testing, governance, and monitoring, DataOps empowers teams to meet the demands of real-time analytics and AI-driven applications while maintaining compliance and trust.
Future Trends
Data Contracts: Formalized agreements for data schema and quality, enforced via API-like governance.
AI Observability: Integration with tools like Arize or WhyLabs for monitoring AI-driven data pipelines.
Serverless DataOps: Fully managed platforms like AWS Glue Studio or Google Cloud Composer for reduced overhead.
Zero Trust Data Security: Enhanced focus on end-to-end encryption and dynamic access controls.