1. Introduction & Overview
What is the DataOps Lifecycle?
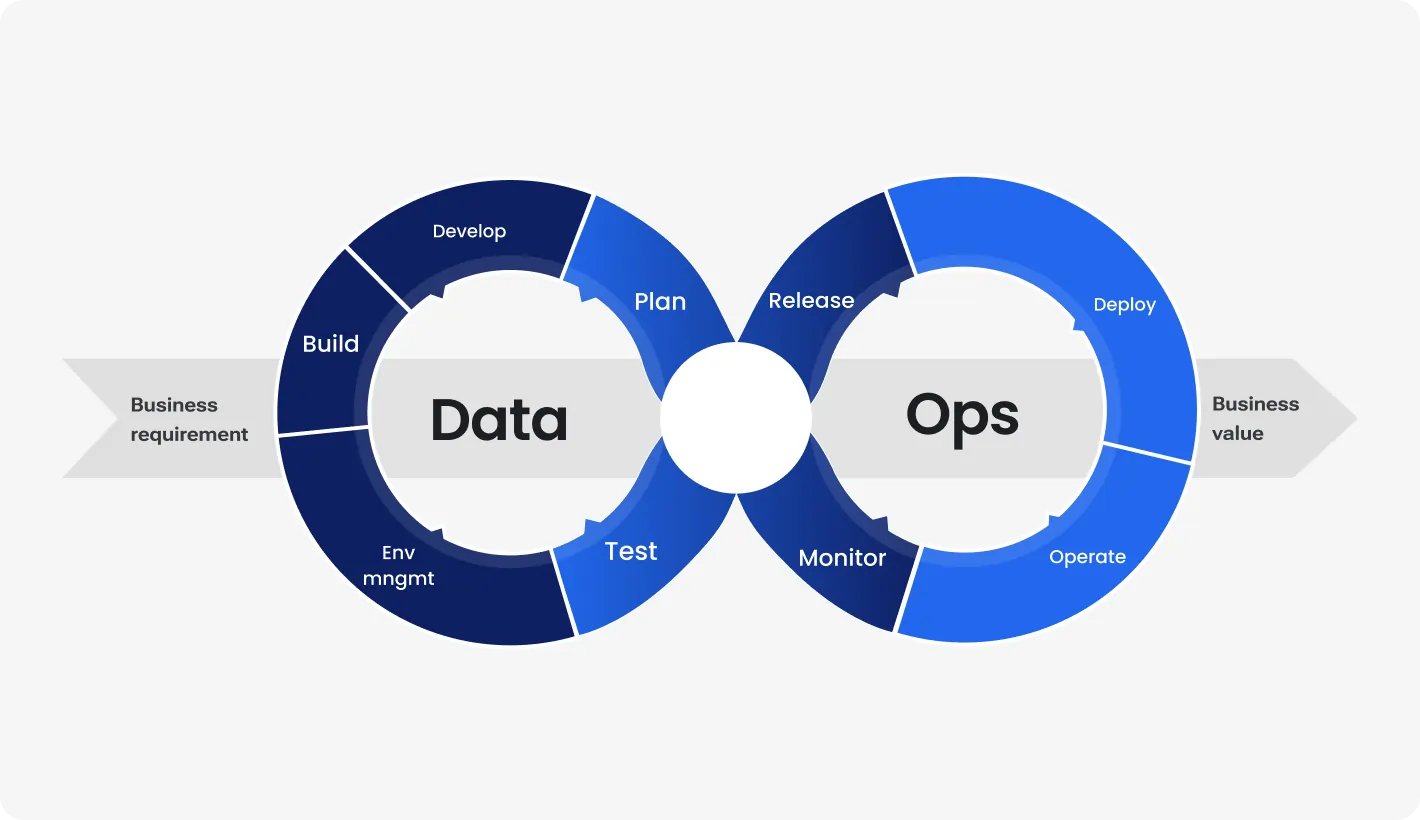
The DataOps Lifecycle refers to the end-to-end process of managing data workflows—from ingestion and transformation to deployment and monitoring—using DevOps principles like automation, collaboration, and continuous improvement. It ensures that data engineering, operations, and security are seamlessly integrated in agile environments.
History or Background
- Coined in 2014 by Lenny Liebmann and later popularized by organizations like Gartner and IBM.
- Inspired by DevOps, DataOps evolved to tackle the growing complexity of data pipelines, governance, and quality.
- Shifted focus from data management to collaborative, iterative data pipeline development with embedded security practices.
Why is it Relevant in DevSecOps?
- Security and compliance risks increase with real-time and high-volume data.
- DataOps ensures security is embedded into every phase of the data lifecycle.
- Brings CI/CD, IaC (Infrastructure as Code), and policy enforcement into data pipeline management.
2. Core Concepts & Terminology
Key Terms and Definitions
| Term | Definition |
|---|---|
| Data Pipeline | An automated process for moving, transforming, and validating data. |
| Metadata Ops | Management of metadata across the pipeline for lineage and auditability. |
| Test Data Management (TDM) | Generating and managing synthetic or anonymized data for testing. |
| Data Governance | Policies and processes that ensure data security, quality, and compliance. |
| Data Observability | Monitoring data quality, lineage, and anomalies in real-time. |
| Security-as-Code | Defining security policies in machine-readable formats, version-controlled like code. |
How It Fits into the DevSecOps Lifecycle
| DevSecOps Phase | DataOps Contribution |
|---|---|
| Plan | Define data quality and compliance requirements. |
| Develop | Build modular, versioned data transformations. |
| Build/Test | Automate data validation, schema checks, and security scanning. |
| Release | Promote certified pipelines through environments. |
| Deploy | Use CI/CD to deploy data workflows securely. |
| Operate | Monitor data SLAs, anomalies, and threat models. |
| Secure | Continuously apply security, privacy, and access controls. |
3. Architecture & How It Works
Components
- Source Systems: Databases, APIs, files.
- Ingestion Layer: Kafka, Airbyte, Apache NiFi.
- Transformation Layer: dbt, Apache Spark, Talend.
- Testing/Validation: Great Expectations, Soda.
- Orchestration: Apache Airflow, Dagster.
- Monitoring/Observability: Monte Carlo, Databand.
- Security Controls: Vault, Lake Formation, Sentry.
- CI/CD Pipelines: Jenkins, GitLab CI, GitHub Actions.
- Governance Layer: Data Catalogs (e.g., Amundsen, Alation).
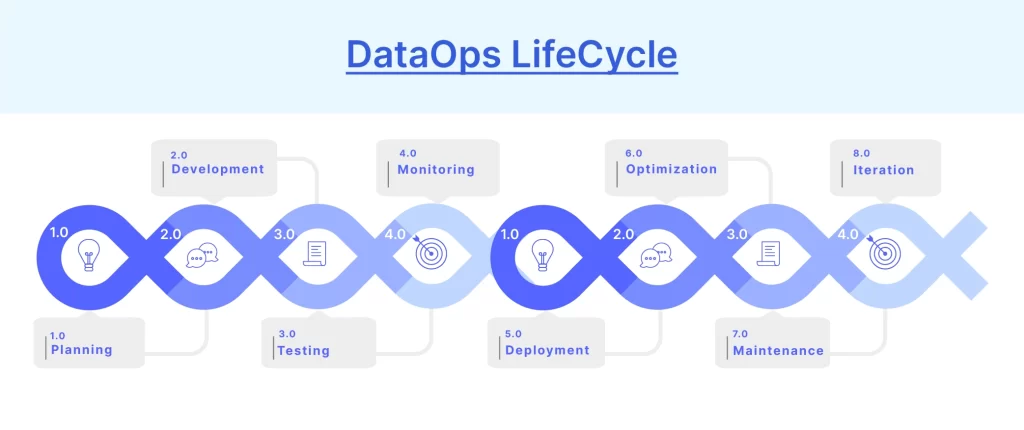
Internal Workflow
- Ingest → Connect to multiple data sources.
- Transform → Clean and shape the data.
- Validate → Perform quality/security checks.
- Deploy → Push to data lakes/warehouses.
- Monitor → Track data lineage and SLA breaches.
- Govern → Ensure compliance and audit trails.
Architecture Diagram (Description)
[Textual Diagram]
┌────────────┐
│ Source │ (DBs, APIs, Files)
└────┬───────┘
│
┌────▼─────┐
│ Ingestion│ (Kafka, NiFi, Airbyte)
└────┬─────┘
│
┌────▼─────┐
│Transform │ (dbt, Spark)
└────┬─────┘
│
┌───────▼────────┐
│Validation & QA │ (Great Expectations)
└───────┬────────┘
│
┌────▼─────┐
│ Orchestration │ (Airflow)
└────┬─────┘
│
┌───────▼────────┐
│ Monitoring & │
│ Security │ (Sentry, Vault, Monte Carlo)
└───────┬────────┘
│
┌─────▼─────┐
│Governance │ (Catalogs, ACLs)
└───────────┘
Integration with CI/CD & Cloud
- GitOps: Store data pipeline code in Git.
- CI/CD Tools: Automate builds/tests (Jenkins, GitHub Actions).
- Cloud Providers:
- AWS Glue, Lambda, and Lake Formation.
- Azure Synapse, Data Factory.
- GCP Dataflow and BigQuery.
4. Installation & Getting Started
Basic Setup or Prerequisites
- Python 3.x
- Docker
- Git
- Cloud credentials (if deploying pipelines in cloud)
Step-by-Step Setup Guide
A. Initialize Project
mkdir dataops-devsecops
cd dataops-devsecops
git init
B. Set Up a Basic Data Pipeline with dbt and Airflow
# Install dbt
pip install dbt-core dbt-postgres
# Initialize dbt project
dbt init my_project
C. Docker-based Apache Airflow Setup
git clone https://github.com/apache/airflow
cd airflow
# Run docker-compose
docker-compose up
D. Set Up Validation with Great Expectations
pip install great_expectations
great_expectations init
E. GitHub Actions Workflow Example
name: CI for DataOps
on: [push]
jobs:
test:
runs-on: ubuntu-latest
steps:
- uses: actions/checkout@v3
- name: Run dbt tests
run: dbt test
- name: Run Great Expectations
run: great_expectations checkpoint run my_checkpoint
5. Real-World Use Cases
1. Healthcare Compliance Pipelines
- Automating de-identification of patient data.
- Integrating HIPAA-compliant access controls via HashiCorp Vault.
2. Financial Institutions
- Data pipelines with SOC 2 controls and real-time anomaly detection.
- Data lineage tracking for audit compliance.
3. Retail & E-commerce
- Automating ETL for personalization engines.
- Validating SKU and price consistency across systems.
4. DevSecOps Toolchains
- Logging pipelines for security telemetry (Falco + Elasticsearch).
- Real-time alerting on suspicious data access patterns.
6. Benefits & Limitations
Key Advantages
- ✅ End-to-end visibility of data and metadata.
- ✅ Built-in security and testing.
- ✅ CI/CD + GitOps for data pipelines.
- ✅ Improved collaboration across teams.
Limitations
- ⚠️ Complex setup and learning curve.
- ⚠️ Integration overhead with legacy systems.
- ⚠️ Requires strong data literacy across teams.
7. Best Practices & Recommendations
Security Tips
- Use Vault or AWS KMS for secret management.
- Enforce RBAC & audit logs on all data stores.
Performance & Maintenance
- Schedule regular data quality checks.
- Use orchestrators like Airflow with retries and alerting.
Compliance & Automation
- Integrate compliance-as-code tools.
- Automate data retention policies and access reviews.
8. Comparison with Alternatives
| Feature | DataOps Lifecycle | Traditional ETL | ML Ops | DevOps |
|---|---|---|---|---|
| Automation | ✅ High | ❌ Low | ✅ Medium | ✅ High |
| Security Integration | ✅ Built-in | ❌ Manual | ❌ Limited | ✅ Partial |
| Real-time Monitoring | ✅ Yes | ❌ No | ✅ Limited | ✅ Yes |
| Governance | ✅ End-to-End | ❌ Poor | ❌ Limited | ❌ Not Focused |
When to Choose DataOps Lifecycle:
- When managing dynamic, multi-source data with compliance needs.
- When embedding data workflows in CI/CD with security controls.
- When scaling collaborative data development across teams.
9. Conclusion
The DataOps Lifecycle bridges the gap between data engineering, operations, and security. When implemented within a DevSecOps culture, it provides a secure, scalable, and compliant framework for building reliable data pipelines. As organizations increasingly become data-driven, mastering DataOps will be pivotal for maintaining data trust, governance, and agility.
Further Reading & Community
- 📘 Official DataOps Manifesto
- 🛠 dbt Documentation
- 📘 Great Expectations Docs
- 🧑🤝🧑 DataOps Slack Community