1. Introduction & Overview
What is Delta Lake?
Delta Lake is an open-source storage layer that brings ACID (Atomicity, Consistency, Isolation, Durability) transactions to Apache Spark and big data workloads. It sits on top of existing data lakes (like S3, ADLS, or HDFS) and transforms them into reliable, scalable, and secure data repositories.
Delta Lake introduces features like schema enforcement, time travel, and data versioning, making data pipelines more resilient and compliant—a critical requirement for DevSecOps.
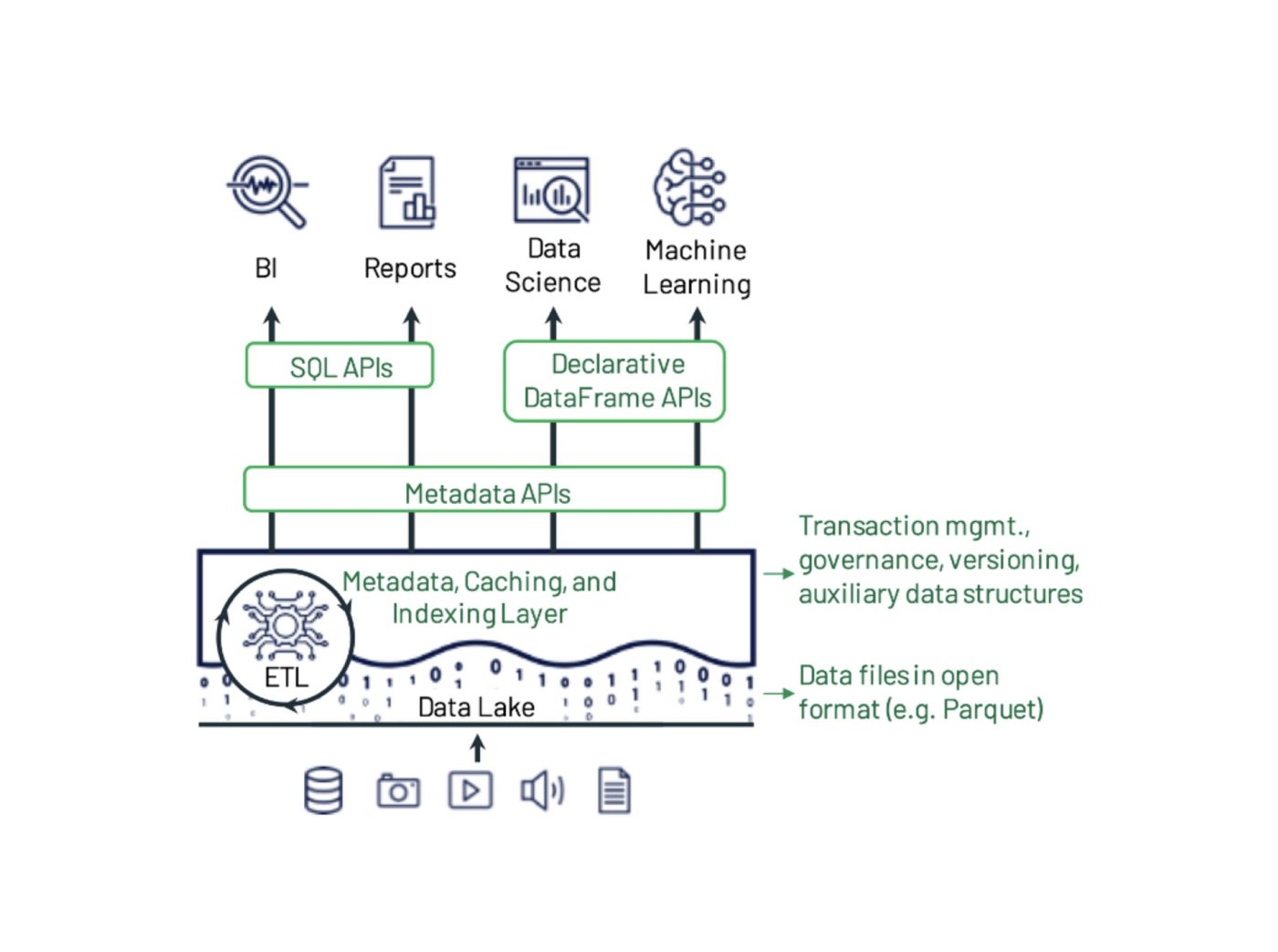
History or Background
- Developed by Databricks and open-sourced in 2019.
- Built to address shortcomings in traditional data lakes, such as data corruption, schema mismatches, and lack of transaction control.
- Delta Lake is now part of the Linux Foundation.
Why is it Relevant in DevSecOps?
- Security & Compliance: Enables audit trails, data rollback, and secure data handling.
- Data Integrity: Ensures validated, versioned, and immutable records—key for secure CI/CD pipelines.
- Scalability & Governance: Supports large-scale, multi-tenant data applications while enforcing access policies.
- Automation: Fits well with automated workflows for analytics, ML, and monitoring within DevSecOps.
2. Core Concepts & Terminology
Key Terms and Definitions
| Term | Definition |
|---|---|
| Delta Table | A versioned, transactional table built using Delta Lake. |
| Time Travel | Ability to query past snapshots of data. |
| Schema Evolution | Support for automatic schema changes with version tracking. |
| ACID Transactions | Guaranteed consistency and isolation in data updates. |
| Upserts (MERGE) | Merge updates and inserts in one atomic operation. |
| CDC (Change Data Capture) | Detect changes in data for auditing and monitoring. |
How It Fits Into the DevSecOps Lifecycle
| DevSecOps Stage | Delta Lake Role |
|---|---|
| Plan | Define secure, compliant data schemas. |
| Develop | Facilitate secure test environments using snapshot data. |
| Build | Automate data integrity checks during builds. |
| Test | Use time travel to test against historical data. |
| Release | Ensure version control in ML/data pipelines. |
| Deploy | Deploy governed data as part of infrastructure-as-code (IaC). |
| Operate | Real-time CDC for security monitoring. |
| Monitor | Audit access and data lineage for anomalies. |
3. Architecture & How It Works
Components
- Delta Lake Core: Layer enabling ACID and transaction log support.
- Delta Log (_delta_log/): Stores metadata, schema versions, and transaction history.
- Spark Engine: Performs computation and interacts with Delta format.
- Cloud/Object Store: Stores actual parquet data files and logs (e.g., AWS S3).
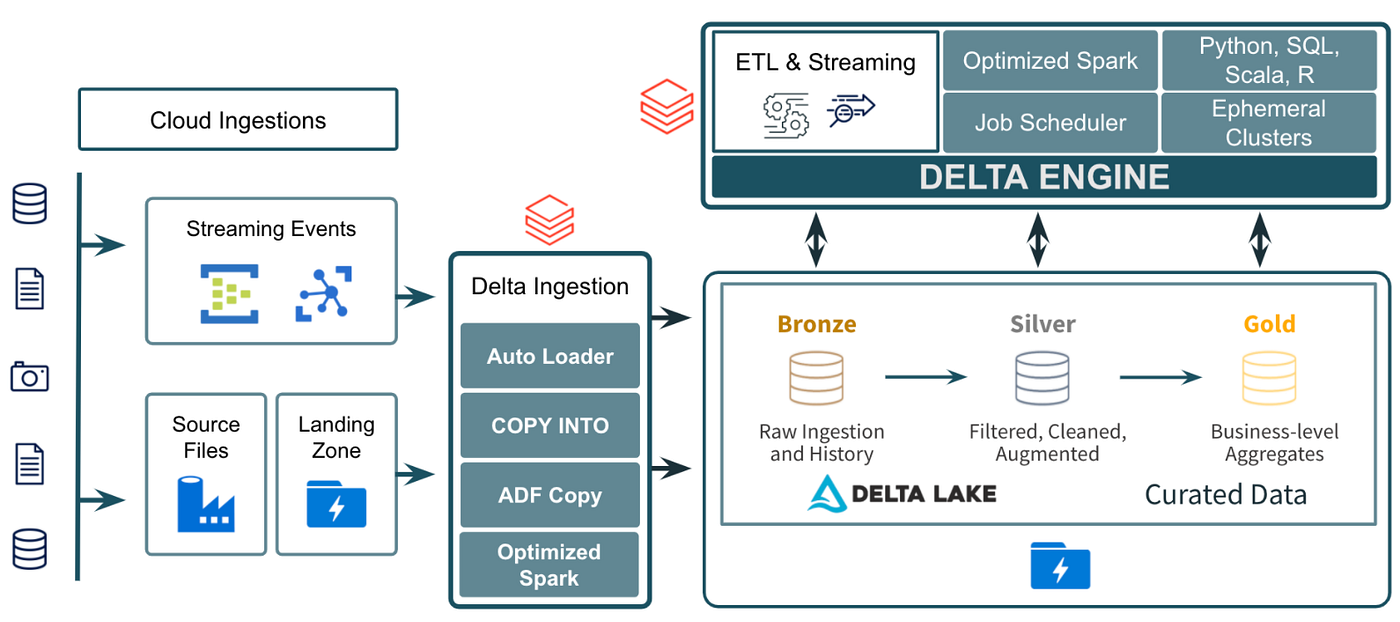
Internal Workflow
- Write Operations: Data written using Spark APIs, creating new parquet files and log entries.
- Transaction Log Update:
_delta_log/directory is updated atomically with new transaction metadata. - Read Operations: Spark reads metadata from the transaction log and reads the latest data.
- Time Travel: Spark queries a specific version using timestamp or version number.
Architecture Diagram (Text Description)
+--------------------------+
| Apache Spark |
+-----------+--------------+
|
v
+--------------------------+
| Delta Lake Storage |
| - Parquet Data Files |
| - Transaction Logs |
| - Version History |
+-----------+--------------+
|
v
+--------------------------+
| Cloud Storage (S3, ADLS)|
+--------------------------+
Integration with CI/CD & Cloud Tools
- CI/CD Pipelines: Trigger data validation or lineage verification in GitHub Actions, GitLab CI, Jenkins.
- Security Tools: Integrate with tools like Apache Ranger or Lake Formation for access control.
- Cloud Environments: Native support for AWS S3, Azure Data Lake Storage, GCP Cloud Storage.
- Monitoring: Use Prometheus/Grafana to observe Delta table metrics.
4. Installation & Getting Started
Prerequisites
- Apache Spark 3.x or Databricks Runtime
- Java 8 or later
- Python 3.x for PySpark examples
- S3 or local filesystem
Setup Guide (PySpark Example)
pip install pyspark
from pyspark.sql import SparkSession
spark = SparkSession.builder \
.appName("DeltaLakeExample") \
.config("spark.sql.extensions", "io.delta.sql.DeltaSparkSessionExtension") \
.config("spark.sql.catalog.spark_catalog", "org.apache.spark.sql.delta.catalog.DeltaCatalog") \
.getOrCreate()
Create Delta Table
data = spark.range(0, 5)
data.write.format("delta").save("/tmp/delta-table")
Read Delta Table
df = spark.read.format("delta").load("/tmp/delta-table")
df.show()
Time Travel
# Read older version
df_old = spark.read.format("delta").option("versionAsOf", 0).load("/tmp/delta-table")
5. Real-World Use Cases
1. Security Logging with Time Travel
- Maintain historical logs in Delta format
- Use time travel to analyze breach impact
2. CI/CD Audit Trails
- Store pipeline artifacts, configs, and results in Delta tables
- Version history supports rollback and diffing
3. Data Governance & Compliance
- Ensure schema compliance
- Track changes using Delta logs for GDPR, HIPAA
4. Financial Transaction Validation
- Use Delta for fraud detection on immutable transactional logs
6. Benefits & Limitations
Benefits
- ✅ ACID compliance on data lakes
- ✅ Time travel & auditability
- ✅ Scalable to petabyte-scale workloads
- ✅ Supports batch & streaming (unified architecture)
- ✅ Built-in schema evolution/enforcement
Limitations
- ❌ Tightly coupled with Spark (though integrations are expanding)
- ❌ Overhead in transaction logging for write-heavy workloads
- ❌ Requires storage best practices to manage log bloat
7. Best Practices & Recommendations
Security Tips
- Use encryption at rest and in transit
- Enable fine-grained access controls (e.g., AWS IAM or Azure RBAC)
- Monitor
_delta_log/changes
Performance
- Optimize compaction (
OPTIMIZE,VACUUM) - Use Z-Ordering for query optimization
Maintenance
- Automate
VACUUMto clean up stale files - Track version history and implement data retention policies
Compliance Alignment
- Use Delta logs for audit compliance (SOX, PCI DSS)
- Implement CDC pipelines for real-time compliance validation
8. Comparison with Alternatives
| Feature / Tool | Delta Lake | Apache Hudi | Apache Iceberg |
|---|---|---|---|
| ACID Transactions | ✅ Yes | ✅ Yes | ✅ Yes |
| Time Travel | ✅ Yes | ❌ Limited | ✅ Yes |
| Schema Evolution | ✅ Yes | ✅ Yes | ✅ Yes |
| Community Support | Strong (Databricks) | Growing | Strong (Netflix, AWS) |
| Streaming Support | ✅ Unified | ✅ | ✅ |
| Integration | Spark, Presto, Trino | Spark, Flink | Spark, Flink, Trino |
When to Choose Delta Lake?
- When using Apache Spark
- Need strong version control & governance
- For regulated industries (finance, healthcare)
- Unified batch + streaming pipelines
9. Conclusion
Delta Lake transforms traditional data lakes into secure, compliant, and high-performing storage layers—critical in modern DevSecOps workflows. It ensures data reliability, traceability, and governance, aligning perfectly with security-first development pipelines.
Future Trends
- Expansion beyond Spark (Presto, Trino, Flink)
- Native cloud integration improvements
- More features around access control and data mesh patterns
Resources
Category: