1. Introduction & Overview
What is Data Classification?
Data Classification is the process of organizing data into categories based on its sensitivity, value, and regulatory requirements. This categorization helps organizations manage, protect, and govern data effectively across its lifecycle—from creation to deletion.
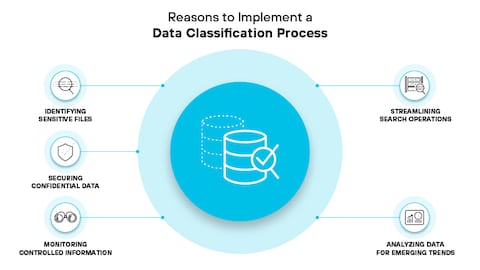
History or Background
Data classification emerged in the 1970s in military and intelligence communities to manage access control for sensitive information. Over the years, it evolved into a fundamental practice for enterprises handling vast amounts of data, especially with the rise of compliance regulations like GDPR, HIPAA, and CCPA. In modern DevSecOps, it plays a pivotal role in integrating security into fast-paced software delivery pipelines.
Why is it Relevant in DevSecOps?
DevSecOps integrates security into every stage of the development lifecycle. In this context, data classification:
- Enables risk-aware development and deployment.
- Automates security controls and compliance enforcement.
- Facilitates zero-trust architecture by applying proper access controls.
- Helps prioritize vulnerabilities based on data sensitivity.
2. Core Concepts & Terminology
Key Terms and Definitions
| Term | Definition |
|---|---|
| Data Sensitivity | The degree of confidentiality or potential damage from unauthorized access |
| Classification Levels | Categories like Public, Internal, Confidential, and Restricted |
| Metadata Tagging | Assigning metadata tags to data based on classification |
| PII | Personally Identifiable Information that requires protection |
| Data Stewardship | The governance and accountability of managing classified data |
How It Fits into the DevSecOps Lifecycle
- Plan: Determine classification schemes and governance.
- Develop: Tag data within application code or schemas.
- Build/Test: Enforce classification policies in CI/CD pipelines.
- Release: Validate deployment security based on classification.
- Operate/Monitor: Audit access and usage of classified data.
- Respond: Apply incident response based on data classification severity.
3. Architecture & How It Works
Components
- Classification Engine: Analyzes data using pattern matching, ML, or rules.
- Tagging Service: Adds metadata labels to files, databases, and API payloads.
- Policy Engine: Enforces controls based on classification level.
- Monitoring & Audit Module: Tracks access and anomalies.
- Integration Layer: Connects with CI/CD, cloud, or DLP tools.
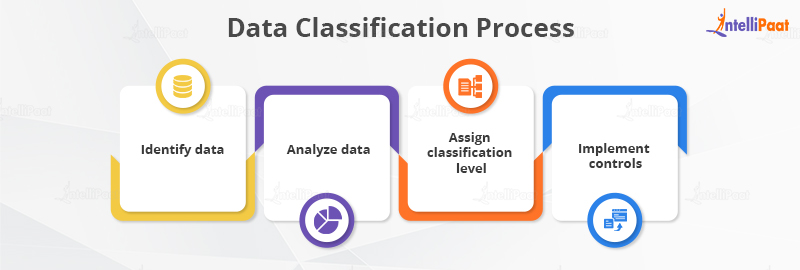
Internal Workflow
[Data Source] → [Classification Engine] → [Metadata Tagging] → [Policy Enforcement] → [Audit/Monitor]
Architecture Diagram (Described)

Since images can’t be rendered here, imagine the following:
- Left: Multiple Data Sources (e.g., code repo, S3, DBs).
- Center: Classification Engine with scanning plugins (RegEx, ML models).
- Right: Outputs tagged data to:
- CI/CD tools (e.g., GitHub Actions)
- Cloud Security tools (e.g., AWS Macie, Azure Purview)
- IAM policies and WAFs.
Integration Points with CI/CD or Cloud Tools
| Tool / Stage | Integration Point |
|---|---|
| GitHub Actions | Validate metadata in pull requests |
| Jenkins Pipelines | Scan data artifacts pre/post-build |
| AWS Macie | Discover and classify sensitive data in S3 |
| Terraform | Classify infrastructure data in IaC |
| Azure Purview | Unified classification for hybrid environments |
4. Installation & Getting Started
Basic Setup or Prerequisites
- Cloud Account (AWS, Azure, GCP) if using managed tools.
- GitHub or CI/CD pipeline for integration.
- CLI tools: AWS CLI / Azure CLI / Terraform (optional).
Hands-on: Step-by-Step Beginner-Friendly Setup (Example with AWS Macie)
Step 1: Enable Macie in AWS Console
aws macie2 enable-macie --status ENABLED
Step 2: Create a classification job
aws macie2 create-classification-job \
--name "S3SensitiveDataScan" \
--s3-job-definition '{"bucketDefinitions":[{"accountId":"123456789012","buckets":["my-bucket"]}]}' \
--job-type ONE_TIME \
--custom-data-identifier-ids ["custom-id"] \
--initial-run-enabled
Step 3: Monitor findings
aws macie2 list-findings
Step 4: Automate classification in CI/CD (example GitHub Actions)
- name: Run data classifier
run: |
./scripts/classify.sh ./artifacts/output.json
5. Real-World Use Cases
1. Preventing Secrets Leakage
Scenario: A DevSecOps pipeline scans artifacts before deployment. A classification engine detects hardcoded secrets or PII and blocks deployment.
2. Complying with GDPR in CI/CD
Scenario: A European e-commerce company uses Azure Purview to classify and label customer PII, integrating classification tags with their CI pipeline to avoid PII in logs.
3. Secure Cloud Storage Audits
Scenario: AWS Macie auto-classifies S3 objects and alerts DevSecOps when unencrypted confidential files are found, triggering automated remediation.
4. Label-based IAM Policies
Scenario: GCP projects enforce IAM rules where access is dynamically granted based on classification labels using context-aware access policies.
6. Benefits & Limitations
Key Advantages
- Improved Risk Management: Prioritize and protect sensitive data.
- Automation Friendly: Seamless integration with CI/CD and DevSecOps tools.
- Regulatory Compliance: Align with HIPAA, GDPR, CCPA, etc.
- Data Minimization: Identify redundant or over-exposed data.
Common Challenges or Limitations
- False Positives/Negatives: Especially with pattern-based scanning.
- Performance Overhead: Large-scale classification may affect pipeline speed.
- Policy Complexity: Misconfigured tagging may result in incorrect enforcement.
- Tool Fragmentation: No single solution fits all environments.
7. Best Practices & Recommendations
Security Tips
- Tag Early: Apply classification as early in the lifecycle as possible.
- Immutable Tags: Prevent users from downgrading classification.
- Least Privilege: Use tags to enforce access control in IAM policies.
Compliance Alignment
- Use Data Loss Prevention (DLP) tools integrated with classifiers.
- Map classifications to compliance frameworks automatically.
Automation Ideas
- Integrate with Git pre-commit hooks to classify code changes.
- Use Infrastructure as Code (IaC) tagging policies for cloud resources.
8. Comparison with Alternatives
| Feature / Tool | Data Classification | Data Loss Prevention | Data Masking |
|---|---|---|---|
| Focus | Tagging & labeling | Preventing exfiltration | Obfuscation |
| Automation | High | Medium | Low |
| Integration with CI | Strong | Moderate | Weak |
| Use in DevSecOps | Proactive | Reactive | Passive |
When to Choose Data Classification
- When you want proactive tagging and context-aware security.
- When your pipeline requires compliance enforcement at scale.
- When integrating access control with sensitivity labels.
9. Conclusion
Data classification is a critical building block for DevSecOps, enabling secure development and deployment practices through awareness, tagging, and enforcement. When integrated properly, it not only enhances security but also helps meet compliance mandates without slowing down innovation.
Future Trends
- AI/ML-driven smart classification.
- Auto-remediation based on classification context.
- Real-time classification in edge and IoT deployments.
References & Further Reading
- 📘 AWS Macie Documentation
- 📘 Azure Purview Documentation
- 📘 Google Data Loss Prevention API
- 📘 [Open Classification Frameworks – NIST, ISO/IEC 27001]