1. Introduction & Overview
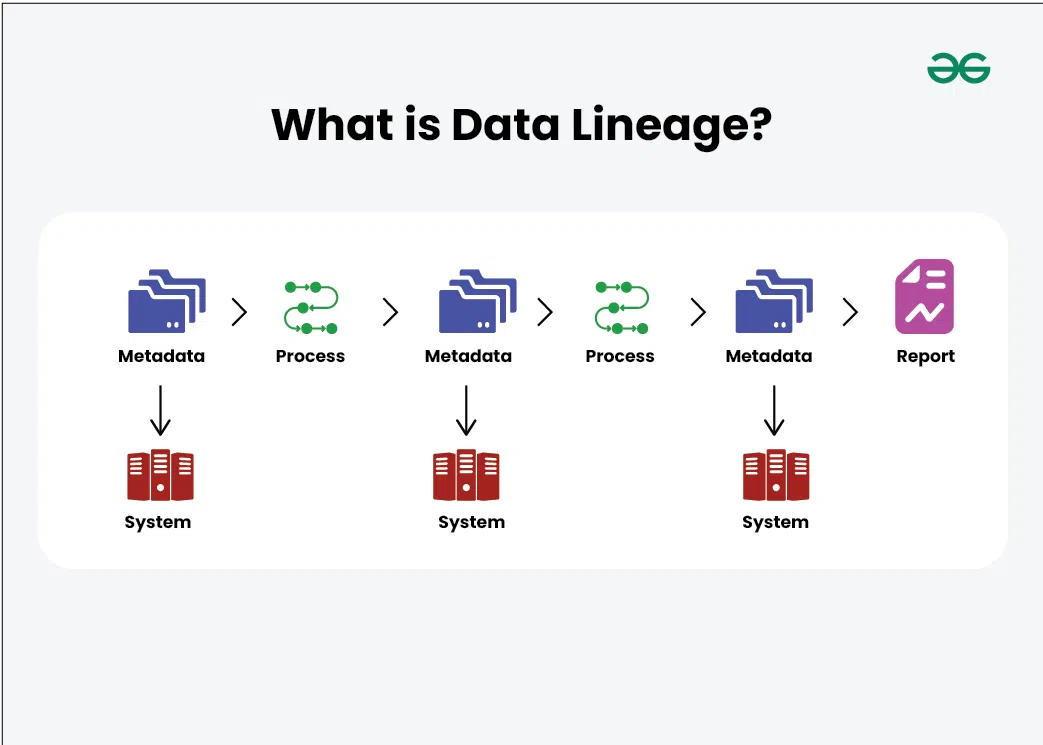
What is Data Lineage?
Data Lineage refers to the life cycle of data—its origins, movements, transformations, and how it interacts across systems. It maps the data flow from source to destination and tracks how it evolves through various processes.
History or Background
- Pre-Cloud Era: Data lineage was largely manual, involving documentation in spreadsheets.
- Modern Systems: With the rise of big data, cloud-native systems, and DevOps, automated lineage became essential for maintaining data integrity, compliance, and traceability.
- DevSecOps Integration: Modern pipelines now embed security and compliance, making lineage crucial for securing data processes.
Why is it Relevant in DevSecOps?
- Security: Tracks sensitive data across environments.
- Audit & Compliance: Provides proof of data handling for regulations like GDPR, HIPAA, SOC 2.
- Incident Response: Quickly identify what data was affected in a breach.
- Automation: Integrates with CI/CD pipelines to automate scanning and validation.
2. Core Concepts & Terminology
Key Terms
| Term | Definition |
|---|---|
| Source | The origin of the data (e.g., database, API). |
| Transformation | Operations applied to data (e.g., filtering, aggregation). |
| Target | Final destination (e.g., dashboard, ML model). |
| Metadata | Data about data (e.g., schema, column names, sensitivity tags). |
| Provenance | Historical record of data origin and changes. |
| Impact Analysis | Determining what downstream systems are affected by a change. |
How It Fits into the DevSecOps Lifecycle
| DevSecOps Stage | Data Lineage Role |
|---|---|
| Plan | Define data flow requirements and classifications. |
| Develop | Embed lineage tracking into ETL/data processing code. |
| Build | Integrate data scan tools in CI pipelines. |
| Test | Validate transformations and detect anomalies. |
| Release | Ensure downstream lineage is updated before promotion. |
| Deploy | Visualize flow in staging/production for monitoring. |
| Operate | Alerting, audits, and live monitoring. |
| Monitor | Continuous compliance and security analysis. |
3. Architecture & How It Works
Components
- Data Collectors: Agents or APIs that collect metadata and lineage info from sources.
- Lineage Engine: Parses, analyzes, and connects the flow paths.
- Metadata Repository: Stores all lineage details, schemas, tags.
- Visualization Layer: Provides graphs and dashboards to view lineage.
- APIs & Connectors: Integrate with CI/CD, cloud tools, and data platforms.
Internal Workflow
- Metadata Ingestion: Collect from sources like SQL, Kafka, S3, etc.
- Lineage Extraction: Parse queries, transformations, and logs.
- Normalization & Storage: Store standardized lineage in a metadata repository.
- Security Tagging: Apply classifications like PII, PCI, etc.
- Visualization & Alerts: Display DAGs (Directed Acyclic Graphs), notify changes.
Architecture Diagram (Textual Description)
[Data Sources] --> [Collectors] --> [Lineage Engine] --> [Metadata Store] --> [UI/API]
|
[Security Engine]
Integration Points
- CI/CD Tools (e.g., GitHub Actions, Jenkins): Automate metadata extraction at build time.
- IaC Tools (e.g., Terraform): Tag data assets with lineage identifiers.
- Cloud Platforms (AWS Glue, Azure Purview, GCP Data Catalog): Native support for lineage.
- Security Tools (Gitleaks, Snyk): Validate that sensitive data paths are secure.
4. Installation & Getting Started
Basic Setup / Prerequisites
- Python 3.8+, Docker, access to data source(s)
- Cloud credentials if using services like AWS Glue or GCP BigQuery
- Choose a tool (e.g., OpenLineage, Marquez, DataHub)
Step-by-Step: Using OpenLineage + Marquez
- Install Marquez (Lineage Backend)
docker run -d -p 5000:5000 \
-e "MARQUEZ_DB_USER=marquez" \
-e "MARQUEZ_DB_PASSWORD=marquez" \
marquezproject/marquez
2. Install OpenLineage Python Client
pip install openlineage-airflow3. Configure Airflow DAGs
from openlineage.airflow import DAG
from openlineage.airflow.extractors import TaskMetadata
@dag(...)
def data_pipeline():
...4. Trigger the Pipeline
airflow dags trigger data_pipeline5. View in Marquez Dashboard
- Navigate to
http://localhost:5000 - Observe lineage as graph
5. Real-World Use Cases
1. Security Audit in FinTech
- Scenario: Regulators audit customer PII flow
- Lineage Tool: Marquez + Airflow + S3
- Outcome: Visual map of every transformation from source to dashboard
2. DevSecOps Pipeline Trace
- Scenario: CI/CD deploys a ML model; need to track training data origin
- Tooling: OpenLineage + MLflow
- Outcome: Full lineage from ingestion → training → production
3. Data Breach Forensics in Healthcare
- Scenario: Unauthorized access detected in a Redshift table
- Tooling: DataHub + Amazon Macie
- Outcome: Identify source of sensitive data and downstream dependencies
4. Cloud Cost Optimization in Retail
- Scenario: Data teams overuse expensive transformations
- Tooling: GCP Data Catalog + Looker
- Outcome: Unused transformations deprecated after lineage analysis
6. Benefits & Limitations
Key Advantages
- ✅ Transparency: Complete visibility into data flows.
- ✅ Compliance: Aligns with GDPR, HIPAA, PCI.
- ✅ Root Cause Analysis: Trace data issues quickly.
- ✅ Collaboration: Data engineers, security teams, and compliance can work from the same view.
Limitations
- ⚠️ Complex Setup: May require agent setup across all sources.
- ⚠️ High Volume Systems: Can become resource-intensive in real time.
- ⚠️ Tool Fragmentation: Each tool has varying integration support.
7. Best Practices & Recommendations
Security Tips
- Encrypt metadata stores and restrict access.
- Use IAM roles with least privilege for lineage agents.
- Tag sensitive fields (e.g., SSN, Card Numbers) explicitly.
Performance & Maintenance
- Regularly purge old or unused metadata.
- Use sampling or partial lineage for high-volume data.
- Optimize DAG rendering for performance.
Compliance & Automation
- Embed lineage validation in CI checks.
- Auto-tag sensitive datasets via regex or ML.
- Export lineage for audit logs.
8. Comparison with Alternatives
| Feature | OpenLineage | DataHub | AWS Glue Lineage | GCP Data Catalog |
|---|---|---|---|---|
| Open Source | ✅ | ✅ | ❌ | ❌ |
| Cloud Agnostic | ✅ | ✅ | ❌ (AWS Only) | ❌ (GCP Only) |
| Real-Time | Limited | Partial | Yes | Yes |
| UI Visualization | Good | Excellent | Limited | Moderate |
| Security Tagging | Customizable | Yes | Yes | Yes |
When to Choose Data Lineage Tools
- Use OpenLineage when integrating with Airflow or Spark.
- Choose DataHub for rich metadata and cross-functional teams.
- Go with AWS Glue Lineage or GCP Catalog for native cloud pipelines.
9. Conclusion
Data Lineage is a cornerstone of modern DevSecOps practices. It enables visibility, governance, and secure data delivery pipelines at scale. As regulatory demands and data complexity increase, integrating lineage deeply into CI/CD and cloud-native workflows becomes a strategic necessity.
Future Trends
- AI-powered lineage inference
- Deeper integration with service meshes and data lakes
- Privacy-preserving lineage visualization
Resources
- 🔗 OpenLineage
- 🔗 DataHub
- 🔗 Marquez
- 🔗 AWS Glue
- 🔗 GCP Data Catalog