Introduction & Overview
What is Data Ingestion?
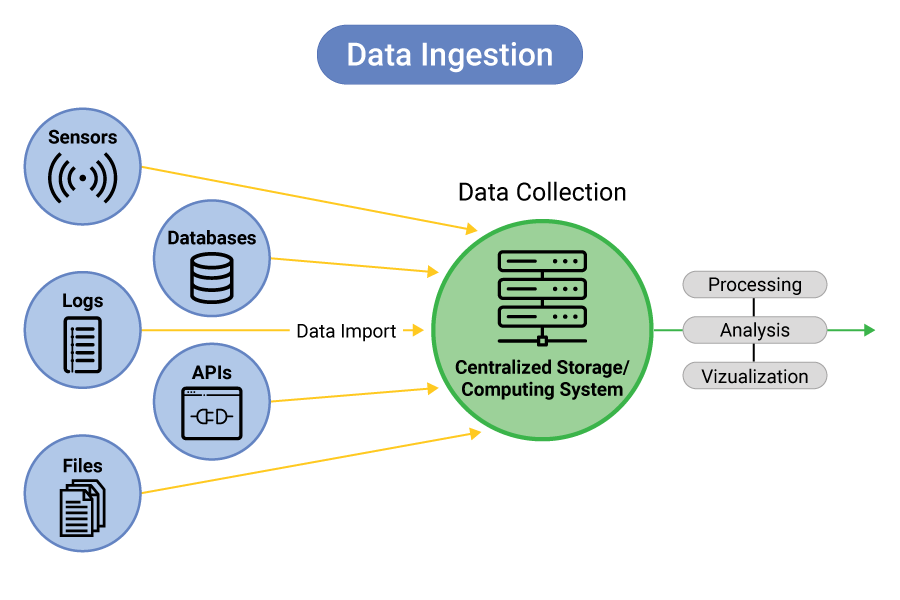
Data ingestion is the process of collecting, importing, and integrating raw data from various sources into a centralized system, such as a data lake, data warehouse, or database, for further processing, storage, or analysis. It serves as the entry point for data pipelines in DataOps, handling both batch and real-time (streaming) data from sources like APIs, databases, IoT devices, or log files. Ingestion may involve lightweight transformations, such as format conversion or validation, to prepare data for downstream use.
History or Background
Data ingestion has its roots in traditional ETL (Extract, Transform, Load) processes used in data warehousing since the 1970s. With the advent of big data, cloud computing, and real-time analytics in the 2000s, ingestion systems evolved to handle high-volume, high-velocity, and diverse data formats (e.g., JSON, CSV, Parquet). The rise of DataOps in the 2010s, inspired by DevOps principles, emphasized automation, collaboration, and scalability in data pipelines. Modern ingestion tools now integrate with cloud platforms, streaming frameworks, and CI/CD pipelines, making ingestion a critical enabler of agile data operations.
Why is it Relevant in DataOps?
Data ingestion is foundational to DataOps, a methodology that combines DevOps practices with data management to improve collaboration, automation, and data quality. Its relevance stems from:
- Scalability: Ingestion systems handle large, diverse datasets from multiple sources.
- Real-time Processing: Supports streaming for near-instant insights, critical for time-sensitive applications.
- Collaboration: Bridges data engineering, analytics, and business teams by ensuring reliable data flow.
- Automation: Integrates with CI/CD pipelines to enable rapid deployment and iteration of data workflows.
Effective ingestion ensures high-quality data enters the pipeline, directly impacting analytics accuracy and business outcomes.
Core Concepts & Terminology
Key Terms and Definitions
- Data Source: The origin of data, such as relational databases (e.g., MySQL), APIs, IoT devices, or log files.
- Batch Ingestion: Processing data in fixed-size chunks at scheduled intervals (e.g., nightly ETL jobs).
- Streaming Ingestion: Processing data in real-time as it arrives (e.g., via Apache Kafka).
- Data Pipeline: A sequence of processes for ingesting, transforming, and storing data.
- Schema-on-Read: Applying structure to data during ingestion, common in data lakes.
- Data Connector: A tool or API that interfaces with data sources to extract data.
- Ingestion Engine: The core system (e.g., Apache NiFi, Airflow) that orchestrates data flow.
| Term | Definition | Example in DataOps |
|---|---|---|
| Data Ingestion | Importing data from one or multiple sources into a storage/processing system | Streaming logs into Kafka |
| Batch Ingestion | Collecting and loading data in scheduled intervals | Daily ETL from an ERP system |
| Real-time Ingestion | Continuous data ingestion with minimal latency | IoT sensor streaming to AWS Kinesis |
| ETL | Extract, Transform, Load – Traditional pipeline with transformations before loading | Cleaning data before storing in a warehouse |
| ELT | Extract, Load, Transform – Modern approach, transform after loading | Loading raw data to Snowflake, then processing |
| Streaming Ingestion | Data is processed as it arrives | Kafka Streams, Apache Flink |
| Data Source | Origin of data to be ingested | APIs, databases, message queues |
How it Fits into the DataOps Lifecycle
Data ingestion is the first stage of the DataOps lifecycle, which includes:
- Ingestion: Collecting raw data from sources.
- Transformation: Cleaning, enriching, or structuring data.
- Storage: Loading data into data lakes (e.g., AWS S3) or warehouses (e.g., Snowflake).
- Analysis: Generating insights via analytics or machine learning.
- Monitoring: Tracking pipeline performance and data quality.
Ingestion directly affects downstream processes, as poor ingestion can lead to data quality issues or pipeline bottlenecks.
Architecture & How It Works
Components, Internal Workflow
A data ingestion architecture typically includes:
- Source Connectors: Interfaces to extract data (e.g., Kafka Connect, JDBC drivers).
- Ingestion Engine: Orchestrates data flow, handling extraction, validation, and routing (e.g., Apache NiFi, Apache Airflow).
- Transformation Layer: Optional lightweight transformations, such as format conversion or data validation.
- Target Storage: Destinations like data lakes (e.g., AWS S3), warehouses (e.g., Snowflake), or databases.
- Monitoring Tools: Track pipeline health and performance (e.g., Prometheus, Grafana).
Workflow:
- Connect to data sources using connectors or APIs.
- Extract data in batches or streams.
- Validate data (e.g., check for missing values) and optionally apply lightweight transformations.
- Load data into the target system.
- Monitor ingestion performance and log errors.
Architecture Diagram (Text Description)
Imagine a flowchart with the following components:
- Left: Multiple data sources (e.g., MySQL database, REST API, IoT sensor) represented as icons.
- Center: An ingestion engine (e.g., Apache NiFi) depicted as a processing node, with arrows from sources feeding into it.
- Middle Layer: A transformation module (optional) shown as a smaller node connected to the ingestion engine.
- Right: Target storage systems (e.g., AWS S3, Snowflake) as endpoints, with arrows from the ingestion engine.
- Top: A monitoring dashboard (e.g., Grafana) observing the entire pipeline, with dotted lines indicating metrics collection.
[Data Sources: APIs, Databases, IoT Sensors]
↓
[Source Connectors / Agents]
↓
[Ingestion Engine: Kafka, NiFi, Flume]
↓
[Processing Layer: Spark Streaming, AWS Lambda]
↓
[Data Lake / Warehouse: S3, Snowflake, BigQuery]
↓
[Monitoring & Alerts: Prometheus, Grafana]Integration Points with CI/CD or Cloud Tools
- CI/CD Integration: Ingestion pipelines can be versioned and deployed using tools like Jenkins or GitLab CI. For example, pipeline configurations in Apache Airflow can be stored in Git and deployed automatically.
- Cloud Tools: Integrates with cloud services like AWS Glue, Azure Data Factory, or Google Cloud Dataflow for scalable ingestion. Connectors for cloud storage (e.g., S3, Google Cloud Storage) and databases (e.g., Redshift) are commonly used.
- Automation: Tools like Kubernetes orchestrate containerized ingestion workloads, ensuring scalability and fault tolerance.
Installation & Getting Started
Basic Setup or Prerequisites
To set up a data ingestion pipeline using Apache NiFi (a popular open-source ingestion tool):
- Hardware: A server with at least 4GB RAM and 2 CPU cores.
- Software: Java 8 or later, Apache NiFi (download from
https://nifi.apache.org). - Dependencies: Network access to data sources and target systems.
- Optional: Docker for containerized deployment, monitoring tools like Prometheus.
Hands-on: Step-by-Step Beginner-Friendly Setup Guide
This guide demonstrates setting up Apache NiFi to ingest data from a CSV file into a PostgreSQL database.
- Install Java:
On Ubuntu, run:
sudo apt update
sudo apt install openjdk-11-jdkVerify: java -version.
2. Download and Install Apache NiFi:
Download NiFi from https://nifi.apache.org/download.html.
Extract the tarball:
tar -xvzf nifi-1.x.x-bin.tar.gz
cd nifi-1.x.xStart NiFi:
./bin/nifi.sh startAccess the NiFi UI at http://localhost:8080/nifi.
3. Configure Data Source (CSV File):
- In the NiFi UI, drag a Processor to the canvas.
- Add a GetFile processor to read a CSV file (e.g.,
/data/input.csv). - Configure:
- Input Directory:
/data/ - File Filter:
.*\.csv
- Input Directory:
4. Set Up PostgreSQL Destination:
- Add a PutDatabaseRecord processor.
- Configure:
- Database Connection URL:
jdbc:postgresql://localhost:5432/mydb - Username/Password: Your PostgreSQL credentials.
- Table Name:
target_table
- Database Connection URL:
- Ensure the PostgreSQL JDBC driver is in NiFi’s
libdirectory.
5. Connect Processors:
- Drag an arrow from GetFile to PutDatabaseRecord to create a data flow.
- Start the pipeline by clicking the “Play” button.
6. Monitor the Pipeline:
- Check the NiFi UI for status and logs.
- Verify data in PostgreSQL:
SELECT * FROM target_table;Real-World Use Cases
- E-commerce: Real-time Inventory Updates:
- Scenario: An e-commerce platform ingests real-time sales data from multiple stores to update inventory in a central warehouse (e.g., Snowflake).
- Implementation: Use Apache Kafka for streaming sales data and Apache NiFi to route it to Snowflake, with validation to ensure data consistency.
- Industry: Retail.
2. Healthcare: Patient Data Integration:
- Scenario: A hospital aggregates patient records from IoT devices, EHR systems, and labs into a data lake for analytics.
- Implementation: AWS Glue ingests data from IoT streams and relational databases into S3, with schema-on-read for flexibility.
- Industry: Healthcare.
3. Finance: Fraud Detection:
- Scenario: A bank processes transaction logs in real-time to detect fraudulent activity.
- Implementation: Apache Flink ingests streaming data from transaction APIs, applies lightweight transformations, and loads it into a Redis cache for real-time analysis.
- Industry: Finance.
4. IoT: Smart City Analytics:
- Scenario: A smart city ingests sensor data (e.g., traffic, air quality) to optimize urban planning.
- Implementation: Google Cloud Dataflow ingests IoT data into BigQuery, with monitoring via Stackdriver.
- Industry: Public Sector.
Benefits & Limitations
Key Advantages
- Scalability: Handles large volumes of data across diverse sources.
- Flexibility: Supports batch and streaming ingestion for various use cases.
- Automation: Integrates with CI/CD and cloud tools for efficient pipelines.
- Reliability: Ensures data consistency with validation and error handling.
Common Challenges or Limitations
- Complexity: Managing multiple data sources and formats can be complex.
- Latency: Real-time ingestion may introduce latency in high-volume scenarios.
- Cost: Cloud-based ingestion tools (e.g., AWS Glue) can be expensive at scale.
- Data Quality: Poor source data can propagate errors downstream.
Best Practices & Recommendations
Security Tips
- Encryption: Use SSL/TLS for data in transit and encrypt sensitive data at rest.
- Access Control: Implement role-based access (RBAC) for ingestion tools and data stores.
- Data Masking: Mask sensitive fields (e.g., PII) during ingestion.
Performance
- Parallel Processing: Use tools like Apache Spark for parallel ingestion.
- Batching: Optimize batch sizes to balance throughput and latency.
- Monitoring: Set up alerts for pipeline failures or performance degradation.
Maintenance
- Version Control: Store pipeline configurations in Git for reproducibility.
- Logging: Maintain detailed logs for debugging and auditing.
- Schema Evolution: Plan for schema changes in source data to avoid pipeline failures.
Compliance Alignment
- Ensure compliance with regulations like GDPR or HIPAA by implementing data retention policies and audit trails.
- Use tools with built-in compliance features, such as AWS Glue’s data catalog for governance.
Automation Ideas
- Automate pipeline deployment using CI/CD tools like Jenkins.
- Use infrastructure-as-code (e.g., Terraform) to provision ingestion resources.
- Implement auto-scaling for cloud-based ingestion to handle variable loads.
Comparison with Alternatives
| Feature | Apache NiFi | AWS Glue | Apache Kafka Connect |
|---|---|---|---|
| Type | Open-source ingestion tool | Cloud-based ETL service | Streaming data connector |
| Ease of Use | GUI-based, beginner-friendly | Managed, requires AWS knowledge | Config-based, steeper learning curve |
| Scalability | Moderate, requires manual scaling | High, auto-scales in cloud | High, distributed architecture |
| Real-time Support | Yes, supports streaming | Limited streaming support | Strong streaming support |
| Cost | Free, but server costs apply | Pay-per-use, can be expensive | Free, but infrastructure costs |
| Best For | Flexible, on-premises pipelines | Cloud-native, AWS ecosystems | High-throughput streaming |
When to Choose Data Ingestion Tools
- Apache NiFi: Ideal for organizations needing a flexible, GUI-based tool for on-premises or hybrid pipelines.
- AWS Glue: Best for AWS-centric environments with large-scale, managed ETL needs.
- Kafka Connect: Suited for real-time streaming with high-throughput requirements.
Conclusion
Data ingestion is a critical pillar of DataOps, enabling organizations to efficiently collect and integrate data for analytics and decision-making. By leveraging modern tools like Apache NiFi, AWS Glue, or Kafka Connect, teams can build scalable, automated, and reliable ingestion pipelines. As DataOps evolves, trends like serverless ingestion, AI-driven data validation, and enhanced observability will shape the future of ingestion.
Next Steps
- Explore tools like Apache NiFi or AWS Glue with hands-on labs.
- Join DataOps communities on platforms like Slack or X for best practices.
- Monitor emerging trends in real-time ingestion and cloud-native architectures.