Introduction & Overview
Data lineage is a critical component of modern data management, providing a clear map of how data flows through an organization’s systems. In the context of DataOps, it ensures transparency, traceability, and trust in data pipelines, enabling teams to deliver high-quality data products efficiently. This tutorial explores data lineage in depth, covering its concepts, architecture, practical setup, use cases, benefits, limitations, and best practices.
What is Data Lineage?
Data lineage refers to the lifecycle of data as it moves from its source to its destination, documenting transformations, dependencies, and processes along the way. It provides a visual and metadata-driven representation of data flows, answering questions like:
- Where did this data originate?
- How was it transformed?
- Who accessed or modified it?
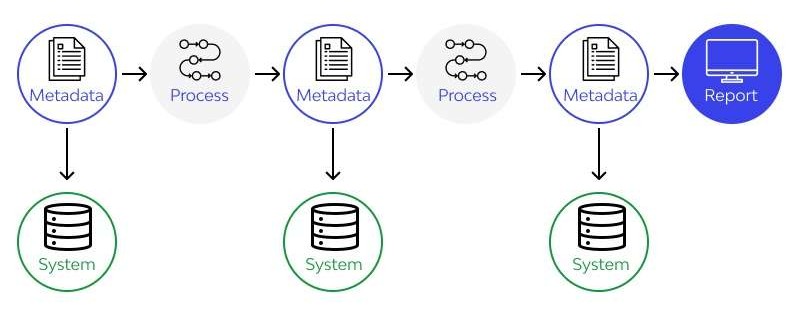
History or Background
The concept of data lineage emerged with the rise of data warehousing in the 1990s, where organizations needed to track data transformations for reporting. With the advent of big data, cloud computing, and DataOps, lineage became essential for managing complex, distributed data pipelines. Tools like Apache Atlas, Collibra, and Informatica began incorporating lineage tracking to address compliance and governance needs.
Why is it Relevant in DataOps?
DataOps emphasizes collaboration, automation, and agility in data management. Data lineage supports these principles by:
- Ensuring Trust: Validates data accuracy and consistency.
- Facilitating Compliance: Helps meet regulations like GDPR, CCPA, and HIPAA.
- Enhancing Collaboration: Provides visibility for data engineers, analysts, and stakeholders.
- Streamlining Debugging: Identifies errors in pipelines quickly.
Core Concepts & Terminology
Key Terms and Definitions
- Data Lineage: A visual or metadata-based representation of data’s journey from source to destination.
- Metadata: Information about data, such as its source, format, and transformations.
- Data Pipeline: A sequence of processes that extract, transform, and load (ETL) data.
- Provenance: The origin and history of data, often a subset of lineage.
- Impact Analysis: Assessing how changes in one dataset affect downstream systems.
- Dependency Mapping: Identifying relationships between datasets and processes.
| Term | Definition |
|---|---|
| Lineage | The complete history of data movement and transformation. |
| Upstream | The sources or processes that feed data into a given system. |
| Downstream | Systems or processes that depend on the output data. |
| Transformation Logic | The rules/scripts applied to alter data during its journey. |
| Metadata | Data about data — includes source details, timestamps, owners, and schema changes. |
| Impact Analysis | Assessing what systems will be affected by a change in data. |
How It Fits into the DataOps Lifecycle
DataOps involves stages like ingestion, transformation, testing, deployment, and monitoring. Data lineage integrates as follows:
- Ingestion: Tracks data sources (e.g., databases, APIs).
- Transformation: Logs transformations (e.g., SQL queries, Python scripts).
- Testing: Validates data quality using lineage metadata.
- Deployment: Ensures pipelines reflect accurate lineage for auditing.
- Monitoring: Detects anomalies by comparing lineage patterns.
Architecture & How It Works
Components and Internal Workflow
Data lineage systems typically include:
- Metadata Repository: Stores metadata about data sources, transformations, and destinations.
- Lineage Collector: Gathers metadata from ETL tools, databases, or scripts.
- Visualization Layer: Displays lineage as graphs or diagrams.
- API/Integration Layer: Connects to DataOps tools like Airflow or dbt.

Workflow:
- Metadata Extraction: Collect metadata from sources (e.g., SQL queries, Apache Spark jobs).
- Lineage Mapping: Create relationships between datasets and processes.
- Storage: Save lineage data in a metadata repository (e.g., Apache Atlas).
- Visualization: Render lineage graphs for users.
- Querying: Allow users to query lineage for impact analysis or debugging.
Architecture Diagram
Imagine a diagram with:
- Left: Data sources (databases, APIs, files).
- Center: ETL processes (Airflow, dbt, Spark) with arrows showing data flow.
- Right: Data destinations (data warehouses, BI tools).
- Top Layer: Metadata repository and visualization tool (e.g., Apache Atlas).
- Bottom Layer: CI/CD and monitoring tools (e.g., Jenkins, Prometheus) linked to lineage.
Integration Points with CI/CD or Cloud Tools
- CI/CD: Lineage tools integrate with Jenkins or GitHub Actions to track pipeline changes.
- Cloud Tools: AWS Glue, Azure Data Factory, or Google Data Catalog natively support lineage.
- Orchestration: Airflow or Prefect logs lineage metadata during pipeline execution.
- BI Tools: Tableau and Power BI use lineage for report validation.
Installation & Getting Started
Basic Setup or Prerequisites
To implement data lineage, you’ll need:
- A metadata management tool (e.g., Apache Atlas, Collibra, or open-source MANTA).
- A data source (e.g., PostgreSQL, Snowflake, or CSV files).
- A DataOps orchestration tool (e.g., Apache Airflow).
- Basic knowledge of SQL, Python, or ETL processes.
- Cloud or on-premises infrastructure with access to metadata APIs.
Hands-On: Step-by-Step Beginner-Friendly Setup Guide
This guide sets up Apache Atlas for data lineage on a local machine.
- Install Java and Maven:
- Ensure Java 11 and Maven 3.6+ are installed.
sudo apt update
sudo apt install openjdk-11-jdk maven2. Download Apache Atlas:
- Get the latest version from Apache Atlas
wget https://downloads.apache.org/atlas/2.3.0/apache-atlas-2.3.0-bin.tar.gz
tar -xzf apache-atlas-2.3.0-bin.tar.gz
cd apache-atlas-2.3.03. Configure Atlas:
- Edit
conf/atlas-application.propertiesto set up metadata storage (e.g., HBase or Cassandra).
atlas.graph.storage.backend=hbase
atlas.graph.index.backend=elasticsearch4. Start Atlas:
./bin/atlas_start.py Access the UI at http://localhost:21000.
5. Connect a Data Source:
- Use Atlas’s REST API to ingest metadata from a PostgreSQL database.
curl -X POST -u admin:admin -H "Content-Type: application/json" \
http://localhost:21000/api/atlas/v2/entity \
-d @postgres_metadata.json Sample postgres_metadata.json:
{
"entity": {
"typeName": "rdbms_table",
"attributes": {
"name": "sales_data",
"qualifiedName": "sales_db.sales_data",
"db": {
"typeName": "rdbms_db",
"attributes": {
"name": "sales_db"
}
}
}
}
}6. Visualize Lineage:
In the Atlas UI, navigate to the “Lineage” tab to view data flow.
Real-World Use Cases
- Financial Compliance (Banking):
- Scenario: A bank uses data lineage to track customer transaction data for regulatory audits (e.g., SOX compliance).
- Implementation: Lineage tools map data from transaction databases to reporting systems, ensuring no unauthorized transformations occur.
- Industry Benefit: Meets regulatory requirements with auditable data trails.
- Healthcare Data Governance:
- Scenario: A hospital tracks patient data from EHR systems to analytics platforms to ensure HIPAA compliance.
- Implementation: Lineage identifies data transformations and access points, flagging unauthorized access.
- Industry Benefit: Protects sensitive data and supports compliance.
- E-Commerce Analytics:
- Scenario: An e-commerce platform uses lineage to debug skewed sales analytics caused by incorrect ETL transformations.
- Implementation: Lineage traces data from raw logs to aggregated reports, identifying a faulty join operation.
- Industry Benefit: Improves data reliability for business decisions.
- Supply Chain Optimization:
- Scenario: A logistics company tracks inventory data across warehouses to optimize supply chain processes.
- Implementation: Lineage maps data from IoT sensors to data lakes, ensuring accurate inventory reporting.
- Industry Benefit: Enhances operational efficiency.
Benefits & Limitations
Key Advantages
- Transparency: Clear visibility into data flows.
- Compliance: Simplifies audits for GDPR, CCPA, etc.
- Error Detection: Pinpoints pipeline issues quickly.
- Collaboration: Aligns data teams with shared understanding.
Common Challenges or Limitations
- Complexity: Setting up lineage for large, legacy systems is time-consuming.
- Tool Integration: Not all tools support seamless lineage tracking.
- Performance Overhead: Metadata collection can slow down pipelines.
- Cost: Enterprise tools like Collibra can be expensive.
Best Practices & Recommendations
Security Tips
- Restrict access to lineage metadata using role-based access control (RBAC).
- Encrypt sensitive metadata in transit and at rest.
- Regularly audit lineage data for unauthorized access.
Performance
- Use incremental metadata collection to reduce overhead.
- Optimize storage by archiving old lineage data.
- Leverage cloud-native tools like AWS Glue for scalability.
Maintenance
- Automate lineage updates with CI/CD pipelines.
- Regularly validate lineage accuracy against actual data flows.
- Document lineage processes for team onboarding.
Compliance Alignment
- Map lineage to compliance frameworks (e.g., GDPR’s data traceability requirements).
- Use lineage for data retention policies to delete outdated data.
Automation Ideas
- Integrate lineage with Airflow using hooks to auto-capture metadata.
- Use dbt’s documentation features to generate lineage alongside transformations.
Comparison with Alternatives
| Feature/Tool | Apache Atlas | Collibra | MANTA | Informatica EDC |
|---|---|---|---|---|
| Open Source | Yes | No | No | No |
| Cloud Integration | Moderate | Strong | Strong | Strong |
| Ease of Setup | Complex | Moderate | Easy | Moderate |
| Cost | Free | High | High | High |
| Visualization | Good | Excellent | Good | Excellent |
When to Choose Data Lineage
- Choose Data Lineage: When compliance, debugging, or transparency is critical.
- Alternatives: Use data catalogs (e.g., Alation) for simpler metadata management or data quality tools (e.g., Great Expectations) for validation-focused workflows.
Conclusion
Data lineage is a cornerstone of DataOps, enabling organizations to build trust, ensure compliance, and streamline data operations. As data ecosystems grow more complex, lineage tools will evolve with AI-driven automation and real-time tracking. To get started, explore tools like Apache Atlas or Collibra, and engage with communities for support.