Introduction & Overview
In today’s data-driven world, organizations rely on efficient, reliable, and scalable systems to process and transform raw data into actionable insights. Data pipelines are the backbone of modern data infrastructure, enabling the seamless flow of data from source to destination while ensuring quality, governance, and speed. In the context of DataOps, a methodology that applies DevOps principles to data management, data pipelines play a critical role in automating and optimizing data workflows to deliver value faster.
This tutorial provides a comprehensive guide to understanding, building, and optimizing data pipelines within a DataOps framework. It covers the core concepts, architecture, setup, real-world applications, benefits, limitations, and best practices, tailored for technical readers such as data engineers, analysts, and architects. By the end, you’ll have a solid foundation to implement data pipelines effectively in a DataOps environment.
What is a Data Pipeline?
A data pipeline is an automated process that moves, transforms, and manages data from one or more sources to a destination, such as a data warehouse, data lake, or analytics platform. It encompasses a series of steps, including data ingestion, transformation, and delivery, ensuring data is clean, consistent, and ready for analysis.
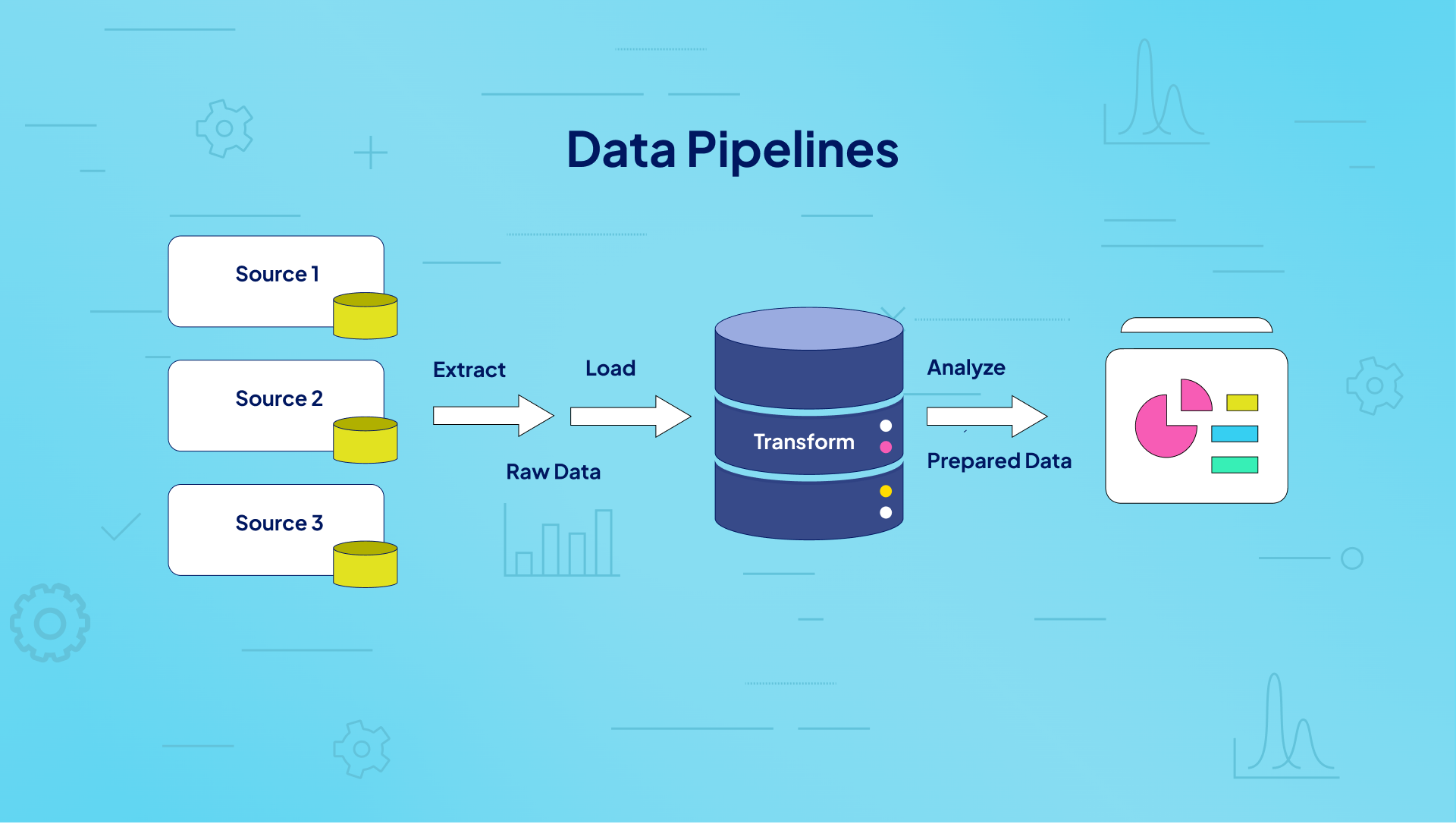
History or Background
- Origins: The concept of data pipelines evolved from traditional ETL (Extract, Transform, Load) processes used in data warehousing. As data volume, variety, and velocity grew with the rise of big data, traditional ETL became insufficient, leading to the development of more flexible and scalable data pipelines.
- Evolution: The advent of cloud computing, real-time analytics, and DataOps in the 2010s transformed data pipelines into dynamic, automated systems. Tools like Apache Kafka, Airflow, and cloud-native platforms (e.g., AWS Data Pipeline, Azure Data Factory) emerged to support modern data needs.
- DataOps Context: Data pipelines became central to DataOps, a methodology inspired by DevOps, focusing on collaboration, automation, and continuous improvement in data workflows. DataOps emphasizes rapid, reliable data delivery, making pipelines critical for operational success.
Why is it Relevant in DataOps?
- Speed and Agility: Data pipelines enable rapid data processing, aligning with DataOps’ goal of delivering insights quickly to meet business demands.
- Collaboration: Pipelines facilitate cross-functional teamwork by providing a unified framework for data engineers, scientists, and analysts.
- Automation: Automated pipelines reduce manual errors, supporting DataOps’ focus on streamlined workflows.
- Quality and Governance: Pipelines incorporate testing and monitoring, ensuring high-quality, compliant data delivery, a core DataOps principle.
Core Concepts & Terminology
Key Terms and Definitions
- Data Ingestion: The process of collecting raw data from sources like databases, APIs, or event streams.
- Data Transformation: Cleaning, enriching, aggregating, or reformatting data to make it suitable for analysis.
- Data Orchestration: Coordinating the flow of data through pipeline stages, often using tools like Apache Airflow or DataOps.live orchestrators.
- Batch Processing: Processing large volumes of data at scheduled intervals.
- Streaming Processing: Real-time data processing for immediate insights.
- Data Product: A reusable, business-ready data asset created by a pipeline, often accompanied by metadata in a manifest.
- CI/CD: Continuous Integration/Continuous Deployment practices adapted for data pipelines to ensure automated testing and deployment.
| Term | Definition |
|---|---|
| ETL/ELT | Extract, Transform, Load (or vice versa) – the flow of data |
| Orchestration | Scheduling and managing data pipeline tasks |
| DAG | Directed Acyclic Graph – task flow representation in tools like Airflow |
| Transformation | Data cleaning, standardization, enrichment |
| Sink | Destination of processed data (e.g., warehouse, dashboard) |
| Source | Origin of raw data (e.g., APIs, files, DBs) |
| Metadata | Data about the data – schema, lineage, quality, etc. |
| Observability | Monitoring and alerting on pipeline health, performance |
How it Fits into the DataOps Lifecycle
The DataOps lifecycle includes stages like data ingestion, processing, analytics development, and delivery. Data pipelines serve as the operational backbone:
- Ingestion: Pipelines extract data from diverse sources, ensuring seamless integration.
- Processing: They transform and validate data, maintaining quality and consistency.
- Analytics Development: Pipelines feed clean data into analytics tools, enabling rapid insight generation.
- Delivery: They ensure data is available to end-users or downstream systems in a timely manner.
- Monitoring and Governance: Pipelines incorporate automated testing and observability, aligning with DataOps’ focus on continuous improvement.
Raw Data → Ingestion → Pipeline Processing → Validation → CI/CD → Monitoring → Delivery
Architecture & How It Works
Components
A typical data pipeline architecture consists of:
- Sources: Databases (e.g., MySQL, MongoDB), APIs, streaming platforms (e.g., Kafka), or flat files.
- Ingestion Layer: Tools like Apache NiFi or AWS Glue to collect data.
- Processing Layer: Frameworks like Apache Spark or dbt for transformation and cleaning.
- Storage Layer: Data lakes (e.g., AWS S3), data warehouses (e.g., Snowflake), or databases.
- Orchestration Layer: Tools like Apache Airflow or DataOps.live to manage workflow execution.
- Monitoring Layer: Tools for observability, such as DataKitchen or Prometheus, to track pipeline health.
| Component | Role |
|---|---|
| Ingestor | Collects data from APIs, DBs, files |
| Processor | Transforms, validates, cleans data |
| Orchestrator | Manages scheduling and dependencies (e.g., Airflow, Dagster) |
| Storage | Stores final output (data lake, warehouse) |
| Monitoring | Tracks metrics, alerts on failures |
| Logging | Logs all events, errors, audit trails |
Internal Workflow
- Data Ingestion: Data is extracted from sources, either in batches or real-time streams.
- Transformation: Data is cleaned, normalized, enriched, or aggregated based on business rules.
- Storage: Processed data is stored in a destination like a data warehouse or lake.
- Orchestration: Tasks are scheduled and executed in sequence, with dependencies managed.
- Monitoring: Pipeline performance, errors, and data quality are tracked in real-time.
Architecture Diagram (Description)
Imagine a flowchart with:
- Left: Multiple data sources (e.g., a database, API, and Kafka stream).
- Middle: An ingestion layer feeding into a processing layer (e.g., Spark cluster) where transformations occur.
- Right: A data warehouse (e.g., Snowflake) as the destination, with an orchestration tool (e.g., Airflow) managing the flow and a monitoring dashboard tracking metrics.
- Arrows: Show data moving from sources to ingestion, processing, storage, and finally to end-users.
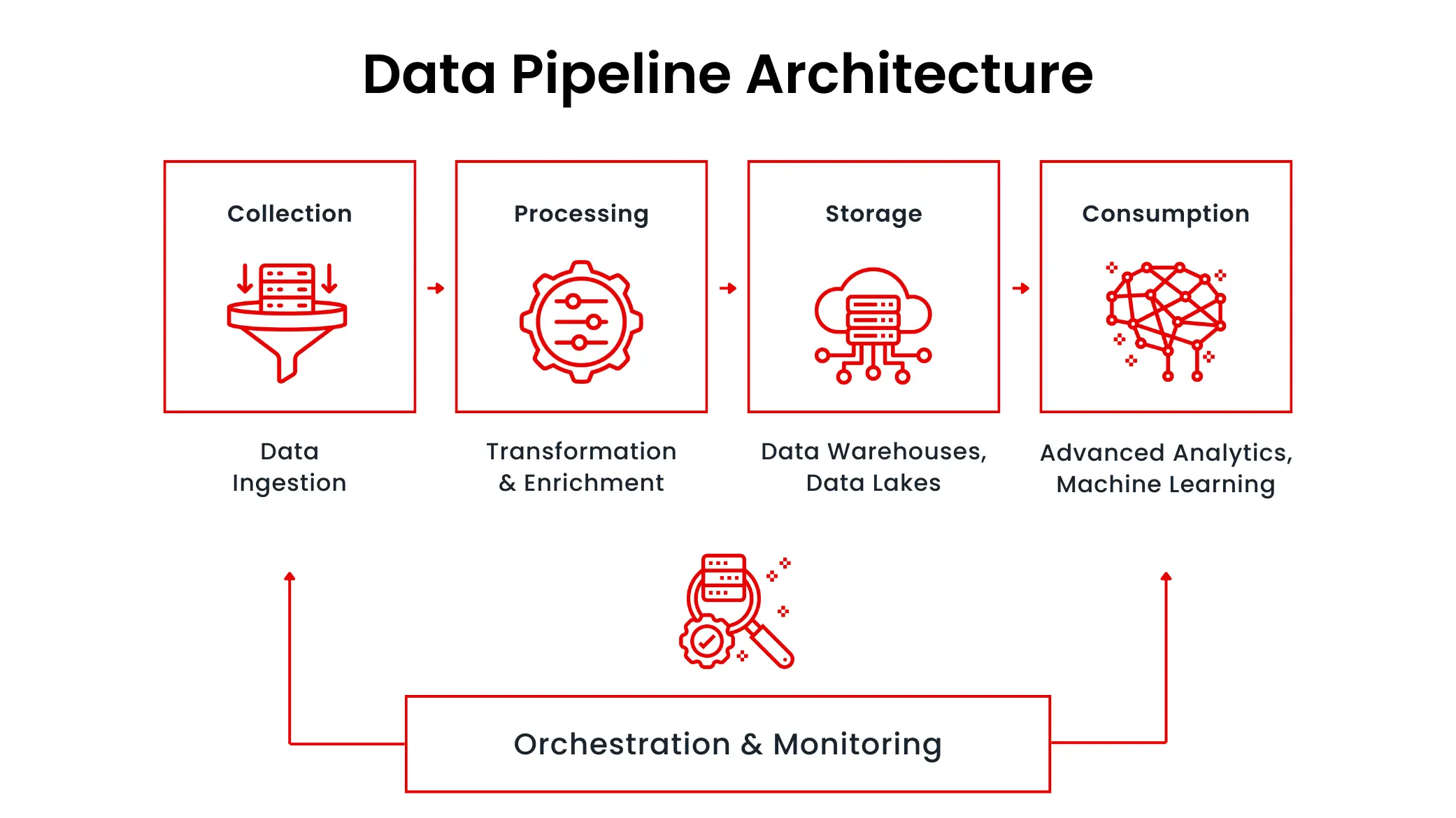
+------------------+
| Data Sources |
| (API, DB, Files) |
+--------+---------+
|
v
+--------+--------+
| Ingestion |
| (ETL Tools) |
+--------+--------+
|
v
+--------+--------+
| Transformation |
| (PySpark/Pandas)|
+--------+--------+
|
v
+--------+--------+
| Storage |
| (Data Lake/WH) |
+--------+--------+
|
v
+--------+--------+
| Monitoring & CI |
+----------------+
Integration Points with CI/CD or Cloud Tools
- CI/CD: Pipelines integrate with tools like GitHub or Azure DevOps for version control and automated deployment of pipeline definitions (e.g., JSON in Azure Data Factory).
- Cloud Tools: AWS Data Pipeline, Azure Data Factory, or Google Cloud Dataflow provide native integration with cloud storage (S3, Azure Data Lake) and compute services (EMR, Databricks).
- Testing: Automated unit, integration, and regression tests are embedded in pipelines using tools like Great Expectations or DataOps.live.
| Tool | Integration Role |
|---|---|
| GitHub Actions | Trigger pipeline deployment/testing automatically |
| Docker | Package ETL jobs in containers |
| Airflow | Define and schedule pipelines as DAGs |
| AWS S3 | Store raw or transformed data |
| Snowflake | Cloud Data Warehouse sink |
| DataDog | Monitoring pipeline performance |
Installation & Getting Started
Basic Setup or Prerequisites
To build a simple data pipeline using Apache Airflow in a DataOps context:
- Hardware: A machine with at least 4GB RAM and 2 CPU cores.
- Software: Python 3.8+, pip, and a database (e.g., PostgreSQL) for Airflow’s metadata.
- Cloud (Optional): Access to a cloud platform like AWS or Azure for storage and compute.
- Tools: Install Git for version control and Docker for containerized environments.
Hands-on: Step-by-Step Beginner-Friendly Setup Guide
- Install Python and pip:
sudo apt update
sudo apt install python3 python3-pip2. Install Apache Airflow:
pip install apache-airflow3. Initialize Airflow Database:
airflow db init 4. Create a DAG (Directed Acyclic Graph):
Create a file ~/airflow/dags/simple_pipeline.py:
from airflow import DAG
from airflow.operators.python import PythonOperator
from datetime import datetime
def extract_data():
print("Extracting data from source...")
def transform_data():
print("Transforming data...")
def load_data():
print("Loading data to destination...")
with DAG(
dag_id='simple_data_pipeline',
start_date=datetime(2025, 8, 1),
schedule_interval='@daily'
) as dag:
extract = PythonOperator(task_id='extract', python_callable=extract_data)
transform = PythonOperator(task_id='transform', python_callable=transform_data)
load = PythonOperator(task_id='load', python_callable=load_data)
extract >> transform >> load5. Start Airflow:
airflow webserver -p 8080 &
airflow scheduler & 6. Access Airflow UI:
Open http://localhost:8080 in a browser, log in (default: admin/admin), and enable the simple_data_pipeline DAG.
7. Monitor Execution:
Check the Airflow UI for pipeline status and logs.
Real-World Use Cases
- E-commerce Analytics (Retail):
- Scenario: An e-commerce company uses a data pipeline to process real-time customer data from its website, CRM (Salesforce), and inventory systems.
- Pipeline: Ingests clickstream data via Kafka, transforms it using Apache Spark, and loads it into Snowflake for BI dashboards.
- DataOps Benefit: Automated testing ensures data quality, enabling rapid updates to sales forecasts.
- Fraud Detection (Finance):
- Scenario: A bank processes transaction data to detect fraudulent activities in real-time.
- Pipeline: Uses Apache Flink for streaming processing, with anomaly detection models, and stores results in a data lake for auditing.
- DataOps Benefit: CI/CD integration allows quick deployment of updated fraud models.
- Healthcare Data Integration:
- Scenario: A hospital integrates patient data from EHR systems and IoT devices for predictive analytics.
- Pipeline: Ingests data via AWS Glue, processes it with Databricks, and delivers insights to a BI tool like Power BI.
- DataOps Benefit: Governance ensures HIPAA compliance, and observability detects data quality issues.
- Marketing Campaign Analysis:
Benefits & Limitations
Key Advantages
- Efficiency: Automates data workflows, reducing manual effort and errors.
- Scalability: Cloud-native pipelines handle large data volumes with ease.
- Reliability: Automated testing and monitoring ensure consistent data quality.
- Flexibility: Supports both batch and real-time processing for diverse use cases.
Common Challenges or Limitations
- Complexity: Managing dependencies and orchestration in large pipelines can be challenging.
- Cost: Cloud-based pipelines can incur significant costs for high data volumes.
- Latency: Real-time pipelines may introduce latency if not optimized.
- Skill Gap: Requires expertise in tools like Airflow, Spark, or cloud platforms.
Best Practices & Recommendations
- Security Tips:
- Encrypt data in transit and at rest using tools like AWS KMS or Azure Key Vault.
- Implement role-based access control (RBAC) for pipeline components.
- Performance:
- Maintenance:
- Regularly update pipeline dependencies to avoid vulnerabilities.
- Implement logging and alerting for quick issue resolution.
- Compliance Alignment:
- Embed data governance policies (e.g., GDPR, HIPAA) into pipeline workflows.
- Use metadata management tools to ensure data lineage and traceability.
- Automation Ideas:
- Integrate CI/CD pipelines with Git for version control of pipeline definitions.
- Use automated testing frameworks like Great Expectations for data validation.
Comparison with Alternatives
| Feature | Data Pipeline (General) | ETL (e.g., SSIS) | Streaming (e.g., Kafka) |
|---|---|---|---|
| Processing Type | Batch & Real-time | Batch | Real-time |
| Flexibility | High | Moderate | High |
| Complexity | Moderate to High | Low to Moderate | High |
| Use Case | General-purpose | BI/Data Warehousing | Real-time Analytics |
| Tools | Airflow, Dataflow, ADF | SSIS, Informatica | Kafka, Flink, Striim |
When to Choose Data Pipelines
- Choose Data Pipelines: When you need a flexible, scalable solution for both batch and real-time processing in a DataOps context.
- Choose ETL: For traditional BI or data warehousing with structured data.
- Choose Streaming: For low-latency, event-driven applications like fraud detection.
Conclusion
Data pipelines are the cornerstone of modern data management in DataOps, enabling organizations to transform raw data into actionable insights with speed, reliability, and governance. By automating data workflows, integrating with CI/CD, and leveraging cloud tools, pipelines empower data teams to deliver value efficiently. As data volumes grow and AI-driven analytics become mainstream, data pipelines will continue to evolve, incorporating more automation and observability.
Next Steps:
- Experiment with the Airflow setup provided in this tutorial.
- Explore advanced tools like Databricks or DataOps.live for enterprise-grade pipelines.
- Stay updated on trends like real-time processing and AI-driven pipeline optimization.