Introduction & Overview
The DataOps Lifecycle is a structured framework that streamlines the management, processing, and delivery of data within an organization. Inspired by DevOps and Agile methodologies, DataOps (Data Operations) integrates automation, collaboration, and continuous improvement to enhance data quality, reduce cycle times, and foster data-driven decision-making. This tutorial provides an in-depth exploration of the DataOps Lifecycle, detailing its components, implementation, real-world applications, and best practices for technical practitioners such as data engineers, data scientists, and IT professionals.
What is the DataOps Lifecycle?
The DataOps Lifecycle is a cyclical, iterative process that governs the flow of data from ingestion to delivery, ensuring high-quality, reliable, and timely data analytics. It combines technical practices, workflows, and cultural norms to enable rapid innovation, high data quality, and collaboration across data teams and stakeholders.
- Definition: A set of practices and processes that automate and optimize data workflows, from data ingestion to analytics delivery, to improve speed, quality, and collaboration.
- Core Objective: To break down silos between data producers and consumers, reduce bottlenecks, and deliver business-ready data efficiently.
- Scope: Encompasses the entire data journey, including planning, development, testing, deployment, and monitoring.
History or Background
The concept of DataOps emerged in the mid-2010s as organizations grappled with the increasing complexity of managing big data. The term was first introduced by Lenny Liebmann in a 2014 blog post, “3 reasons why DataOps is essential for big data success,” and later popularized by data management experts like Andy Palmer and Steph Locke. It draws inspiration from:
- DevOps: Focuses on continuous integration and delivery (CI/CD) for software development.
- Agile Methodology: Emphasizes iterative development and adaptability.
- Lean Manufacturing: Aims to reduce waste and optimize processes.
By 2018, Gartner recognized DataOps in its Hype Cycle for Data Management, signaling its growing adoption. The rise of cloud computing, big data, and machine learning further accelerated its relevance, as organizations sought scalable, automated solutions to manage exponential data growth, projected to reach 180 zettabytes by 2025.
Why is it Relevant in DataOps?
The DataOps Lifecycle is critical in DataOps because it addresses the challenges of modern data management, such as data silos, inconsistent quality, and slow delivery. Its relevance stems from:
- Scalability: Handles increasing data volumes and diverse sources (e.g., IoT, mobile, machine learning).
- Agility: Enables rapid response to changing business needs through iterative workflows.
- Collaboration: Bridges gaps between data engineers, scientists, analysts, and business stakeholders.
- Quality Assurance: Ensures high data quality through continuous monitoring and validation.
- Business Value: Accelerates time-to-insights, enabling faster, data-driven decisions.
Core Concepts & Terminology
Key Terms and Definitions
- Data Pipeline: A series of processes that extract, transform, and load (ETL/ELT) data from sources to destinations.
- Data Observability: Continuous monitoring of data pipelines to detect anomalies, errors, or performance issues.
- Data Governance: Policies and processes to ensure data security, compliance, and accessibility.
- CI/CD (Continuous Integration/Continuous Deployment): Automated testing and deployment of data pipelines, inspired by DevOps.
- Data Lineage: Tracking the origin, movement, and transformation of data across the lifecycle.
- Orchestration: Automation of data workflows, scheduling, and dependency management.
- Self-Service Analytics: Tools that allow business users to access and analyze data without IT intervention.
| Term | Definition |
|---|---|
| Data Ingestion | The process of collecting raw data from various sources (APIs, IoT devices, DBs). |
| Data Transformation | Converting raw data into a usable format using ETL/ELT processes. |
| Data Orchestration | Automated scheduling & execution of data workflows. |
| Data Testing | Automated validation to ensure quality and accuracy. |
| Data Governance | Policies and processes to ensure compliance, security, and lineage tracking. |
| Data Observability | Monitoring pipelines to detect failures or anomalies. |
| Data Deployment | Publishing clean, transformed data to consumers or BI tools. |
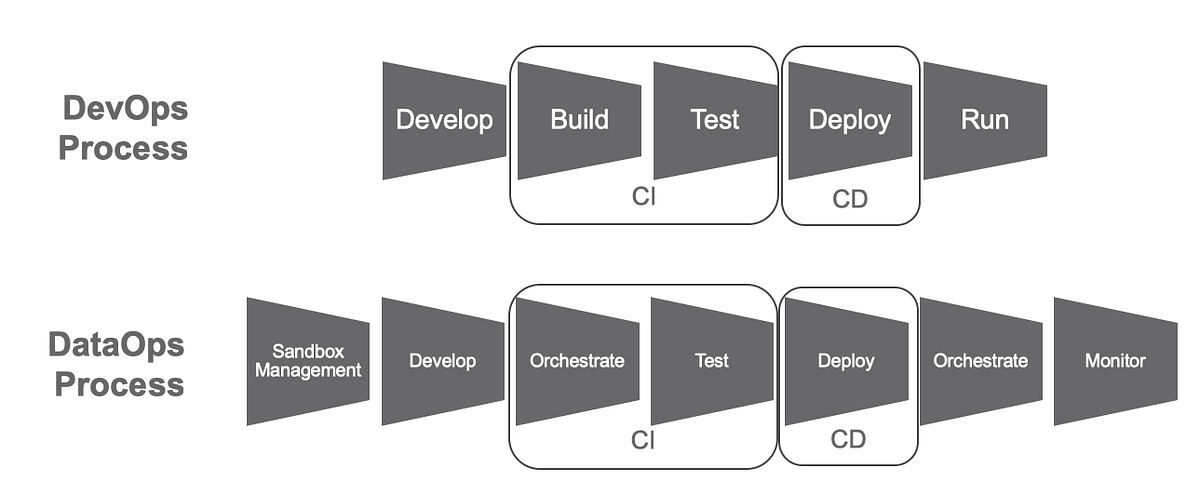
How It Fits into the DataOps Lifecycle
The DataOps Lifecycle is typically divided into five key phases, each addressing a specific aspect of data management:
- Plan: Define business goals, data requirements, and pipeline specifications.
- Develop: Build and refine data pipelines, transformations, and analytics models.
- Test: Validate data quality, pipeline performance, and model accuracy through automated tests.
- Deploy: Release data pipelines or analytics models to production environments using CI/CD.
- Monitor: Continuously observe pipeline health, data quality, and performance metrics.
These phases form a continuous feedback loop, enabling iterative improvements and adaptability to changing data needs.
Architecture & How It Works
Components and Internal Workflow
The DataOps Lifecycle architecture consists of interconnected components that facilitate data flow and management:
- Data Ingestion Layer: Collects raw data from diverse sources (databases, APIs, IoT devices).
- Data Processing Layer: Transforms and enriches data using ETL/ELT processes.
- Data Storage Layer: Stores processed data in data lakes, warehouses, or databases.
- Analytics Layer: Generates insights through business intelligence (BI) tools, machine learning models, or dashboards.
- Orchestration Layer: Automates workflows, schedules tasks, and manages dependencies.
- Observability Layer: Monitors pipeline health, data quality, and performance metrics.
Workflow:
- Data is ingested from sources (e.g., SQL databases, streaming platforms like Kafka).
- Pipelines transform and clean data using tools like Apache Airflow or DBT.
- Automated tests validate data integrity and quality.
- CI/CD pipelines deploy changes to production environments.
- Observability tools (e.g., Datadog, Monte Carlo) monitor pipelines and alert teams to issues.
Architecture Diagram Description
Since images cannot be generated, here’s a textual description of a typical DataOps Lifecycle architecture diagram:
- Top Layer (Sources): Icons representing diverse data sources (databases, APIs, IoT, files).
- Arrow to Ingestion Layer: Data flows into a centralized ingestion module (e.g., Apache NiFi).
- Processing Layer: A pipeline with nodes for ETL/ELT processes, connected to tools like Apache Spark or DBT.
- Storage Layer: Data lakes (e.g., AWS S3) and warehouses (e.g., Snowflake) store processed data.
- Analytics Layer: BI tools (e.g., Tableau) and ML models connect to storage for insights.
- Orchestration Layer: A central orchestrator (e.g., Airflow) manages workflows, with arrows to all layers.
- Observability Layer: Dashboards and alerts (e.g., Prometheus) monitor the entire pipeline.
- CI/CD Pipeline: A parallel workflow showing version control (Git), testing, and deployment stages.
Integration Points with CI/CD or Cloud Tools
- CI/CD Integration:
- Version Control: Git repositories store pipeline configurations and transformations.
- Automated Testing: Unit, integration, and end-to-end tests validate data pipelines (e.g., Great Expectations for data quality).
- Deployment: Tools like Jenkins or GitHub Actions automate pipeline deployment to production.
- Cloud Tools:
- AWS: S3 for storage, Glue for ETL, and Step Functions for orchestration.
- Azure: Data Factory for pipelines, Synapse for analytics, and Azure Monitor for observability.
- GCP: BigQuery for warehousing, Dataflow for processing, and Cloud Composer for orchestration.
Installation & Getting Started
Basic Setup or Prerequisites
To implement a DataOps Lifecycle, you’ll need:
- Infrastructure: Cloud platform (AWS, Azure, GCP) or on-premises servers.
- Tools:
- Orchestration: Apache Airflow, Prefect, or Kubernetes.
- Data Processing: Apache Spark, DBT, or Informatica.
- Observability: Datadog, Monte Carlo, or Prometheus.
- Version Control: Git (e.g., GitHub, GitLab).
- Skills: Knowledge of Python, SQL, and CI/CD practices.
- Access: Permissions to access data sources and cloud resources.
Hands-On: Step-by-Step Beginner-Friendly Setup Guide
This guide sets up a basic DataOps pipeline using Apache Airflow on a local machine.
- Install Prerequisites:
- Install Python 3.8+ and pip.Install Docker (for Airflow’s containerized setup).
sudo apt-get update sudo apt-get install python3-pip docker.io2. Install Apache Airflow:
pip install apache-airflow airflow db init3. Configure Airflow:
- Edit
airflow.cfgin~/airflowto set the executor toLocalExecutor. - Create a DAG (Directed Acyclic Graph) file in
~/airflow/dags.
4. Create a Sample DAG:
from airflow import DAG
from airflow.operators.python import PythonOperator
from datetime import datetime
def extract_data():
print("Extracting data...")
def transform_data():
print("Transforming data...")
with DAG('dataops_pipeline', start_date=datetime(2025, 1, 1), schedule_interval='@daily') as dag:
extract = PythonOperator(task_id='extract', python_callable=extract_data)
transform = PythonOperator(task_id='transform', python_callable=transform_data)
extract >> transform5. Start Airflow:
airflow webserver -p 8080 airflow scheduler6. Access Airflow UI:
- Open
http://localhost:8080in a browser. - Trigger the
dataops_pipelineDAG and monitor its execution.
7. Add Observability:
- Integrate a monitoring tool like Prometheus by adding its client library:
pip install prometheus-clientReal-World Use Cases
- Financial Services: Regulatory Reporting:
- Scenario: A bank uses DataOps to streamline GDPR-compliant reporting.
- Implementation: Automated pipelines in Azure Data Factory ingest customer data, tag personally identifiable information (PII) using Atlan Playbooks, and generate compliance reports in hours instead of days.
- Outcome: Reduced manual effort by 80% and ensured regulatory compliance.
- Retail: Real-Time Inventory Analytics:
- Scenario: A retail chain optimizes inventory using real-time sales data.
- Implementation: Apache Kafka streams sales data, processed by Spark, and stored in Snowflake. Airflow orchestrates the pipeline, with Datadog monitoring for anomalies.
- Outcome: Reduced stockouts by 30% and improved supply chain efficiency.
- Healthcare: Clinical Decision Support:
- Scenario: A hospital uses DataOps to ensure high-quality patient data for diagnostics.
- Implementation: ETL pipelines in Informatica clean and validate patient records, with CI/CD via Jenkins for updates. Monte Carlo provides data observability.
- Outcome: Improved data accuracy for clinical decisions, reducing errors by 25%.
- E-Commerce: Customer Behavior Insights:
- Scenario: An e-commerce platform analyzes user behavior for personalized recommendations.
- Implementation: GCP’s Dataflow processes clickstream data, stored in BigQuery. Cloud Composer orchestrates workflows, with automated testing via Great Expectations.
- Outcome: Increased customer engagement by 15% through targeted recommendations.
Benefits & Limitations
Key Advantages
- Improved Data Quality: Continuous monitoring and automated testing ensure accurate, reliable data.
- Faster Time-to-Insights: Automation and CI/CD reduce pipeline development time from months to days.
- Enhanced Collaboration: Cross-functional teams align on goals, reducing silos.
- Scalability: Cloud-native tools and orchestration support growing data volumes.
- Cost Efficiency: Automation minimizes manual intervention, reducing operational costs.
Common Challenges or Limitations
- Complexity: Setting up automated pipelines requires significant initial investment in tools and skills.
- Cultural Resistance: Teams may resist adopting new workflows or collaboration models.
- Tool Integration: Ensuring interoperability between diverse tools can be challenging.
- Data Security: Managing compliance (e.g., GDPR, HIPAA) across pipelines requires robust governance.
Best Practices & Recommendations
- Security Tips:
- Implement role-based access control (RBAC) for data access.
- Use encryption for data at rest and in transit (e.g., AWS KMS, Azure Key Vault).
- Automate compliance checks using tools like Atlan or Collibra.
- Performance:
- Optimize pipelines with distributed processing (e.g., Spark, Flink).
- Use serverless architectures (e.g., AWS Lambda) for cost-effective scaling.
- Maintenance:
- Regularly update pipeline configurations in version control.
- Monitor KPIs like error rates and processing times using dashboards.
- Compliance Alignment:
- Ensure data lineage tracking for auditability (e.g., Monte Carlo, Alation).
- Align with regulations like GDPR, HIPAA, or CCPA using governance tools.
- Automation Ideas:
- Automate data quality checks with Great Expectations or DBT tests.
- Use Infrastructure-as-Code (IaC) tools like Terraform for environment provisioning.
Comparison with Alternatives
| Aspect | DataOps Lifecycle | Traditional Data Management | MLOps |
|---|---|---|---|
| Focus | End-to-end data lifecycle management | Manual, siloed data processes | Machine learning model lifecycle |
| Automation | High (CI/CD, orchestration) | Low (manual ETL) | Moderate (model training, deployment) |
| Collaboration | Cross-functional teams | Limited, siloed teams | Data scientists and IT collaboration |
| Use Case | General data analytics, BI, compliance | Legacy data warehousing | AI/ML model development |
| Tools | Airflow, DBT, Monte Carlo, Snowflake | SQL Server, Oracle | TensorFlow, Kubeflow, SageMaker |
| Scalability | High (cloud-native, distributed) | Limited | High for ML-specific workloads |
When to Choose the DataOps Lifecycle
- Choose DataOps Lifecycle when you need to manage diverse data sources, ensure high data quality, and deliver insights rapidly across teams.
- Choose Alternatives:
- Traditional Data Management: For small-scale, legacy systems with minimal automation needs.
- MLOps: For projects focused solely on machine learning model development and deployment.
Conclusion
The DataOps Lifecycle is a transformative framework that empowers organizations to manage data with agility, quality, and collaboration. By integrating automation, CI/CD, and observability, it addresses the challenges of modern data ecosystems, enabling faster insights and better decision-making. As data volumes continue to grow and AI/ML adoption accelerates, the DataOps Lifecycle will remain a cornerstone of data-driven enterprises.
Future Trends:
- AI Integration: Increased use of AI for automated data quality and pipeline optimization.
- Real-Time DataOps: Growth in streaming architectures for low-latency insights.
- Data Mesh: Adoption of decentralized data architectures for scalability.
Next Steps:
- Explore tools like Apache Airflow, DBT, or Monte Carlo for hands-on practice.
- Join communities like the DataOps Community (dataops.community) or attend webinars from Qlik or IBM.