Introduction & Overview
Data anonymization is a critical practice in DataOps, ensuring sensitive data is protected while maintaining its utility for analysis and development. This tutorial provides an in-depth exploration of anonymization in the context of DataOps, covering its concepts, implementation, and real-world applications. Designed for data engineers, DevOps professionals, and compliance officers, this guide offers practical insights and hands-on steps to integrate anonymization into DataOps workflows.
What is Anonymization?
Anonymization refers to the process of transforming data to prevent the identification of individuals while preserving its analytical value. Unlike pseudonymization, which allows reversible data masking, anonymization ensures data cannot be re-identified, making it a cornerstone of privacy compliance.
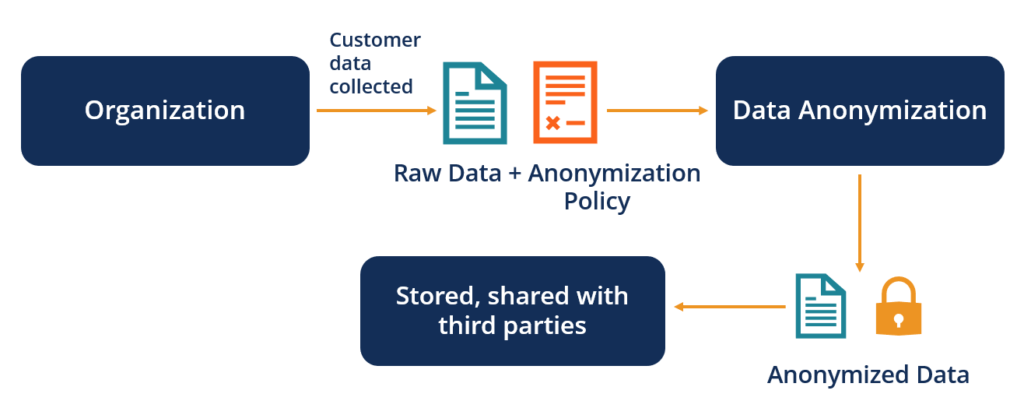
History or Background
Anonymization has evolved alongside data privacy regulations like GDPR (2018) and CCPA (2020). Early techniques focused on simple masking, but modern approaches leverage advanced algorithms to balance privacy and utility. The rise of DataOps, which emphasizes collaboration, automation, and continuous delivery in data workflows, has made anonymization essential for secure data pipelines.
Why is it Relevant in DataOps?
In DataOps, anonymization enables:
- Compliance: Adherence to regulations like GDPR, HIPAA, and CCPA.
- Secure Collaboration: Safe data sharing across teams and environments.
- Testing and Development: Use of production-like data without privacy risks.
- Risk Mitigation: Protection against data breaches and misuse.
Core Concepts & Terminology
Key Terms and Definitions
- Anonymization: Irreversible removal or alteration of personally identifiable information (PII).
- Pseudonymization: Reversible data masking, e.g., replacing names with pseudonyms.
- PII (Personally Identifiable Information): Data that can identify an individual, such as names, SSNs, or emails.
- k-Anonymity: Ensures each record is indistinguishable from at least k-1 other records.
- Differential Privacy: Adds noise to data to protect individual identities while allowing statistical analysis.
- Data Masking: Techniques like substitution, shuffling, or encryption to obscure data.
| Term | Description |
|---|---|
| PII | Personally Identifiable Information — data that can identify an individual. |
| Direct Identifiers | Name, Email, SSN — directly identify a person. |
| Quasi-identifiers | Age, Gender, Zip code — may identify when combined with others. |
| Masking | Replacing sensitive data with fictional values while keeping structure. |
| Generalization | Reducing precision (e.g., changing exact age to age range). |
| Randomization | Introducing noise to prevent reverse engineering. |
| Pseudonymization | Replacing identifiers with reversible placeholders. |
| Irreversible Anonymization | Transforming data such that re-identification is impossible. |
How It Fits into the DataOps Lifecycle
DataOps involves stages like data ingestion, processing, analysis, and deployment. Anonymization integrates as follows:
- Ingestion: Anonymize data at the source to ensure privacy from the start.
- Processing: Apply anonymization during ETL (Extract, Transform, Load) pipelines.
- Analysis: Use anonymized datasets for analytics and machine learning.
- Deployment: Share anonymized data with production or test environments.
Architecture & How It Works
Components and Internal Workflow
Anonymization in DataOps typically involves:
- Data Discovery: Identifying PII using tools like regex or metadata scanning.
- Transformation Engine: Applying techniques like generalization, suppression, or noise addition.
- Policy Management: Defining rules for anonymization based on compliance needs.
- Monitoring and Auditing: Tracking anonymization processes for compliance and quality.
Workflow:
- Scan input data for PII.
- Apply anonymization rules (e.g., mask SSNs, generalize ages).
- Validate output to ensure no re-identification risk.
- Log processes for audit trails.
Architecture Diagram (Text Description)
Imagine a pipeline with:
- Input Layer: Raw data from databases or APIs.
- Anonymization Layer: Tools like Apache NiFi or custom scripts process data.
- Storage Layer: Anonymized data stored in a data lake (e.g., AWS S3, Azure Data Lake).
- Output Layer: Data consumed by analytics tools or CI/CD pipelines.
+------------------+
| Data Sources |
| (CRM, DB, APIs) |
+--------+----------+
|
Data Ingestion
↓
+------------------+
| Anonymization |
| Layer |
| - Masking |
| - Hashing |
| - Generalization |
+--------+----------+
|
+---------+---------+
| Validation Layer |
| (PII Scan) |
+---------+---------+
|
Secure Storage
↓
Analytics / ML ToolsIntegration Points with CI/CD or Cloud Tools
- CI/CD: Anonymization scripts integrated into Jenkins or GitHub Actions for automated testing.
- Cloud Tools: AWS Glue, Azure Data Factory, or Google Cloud Dataflow for scalable anonymization.
- APIs: RESTful APIs to trigger anonymization on demand.
Installation & Getting Started
Basic Setup or Prerequisites
- Environment: Python 3.8+, Docker (optional for containerized tools).
- Libraries:
pandas,faker(for synthetic data),pycryptodome(for encryption). - Tools: Apache NiFi or Open-source anonymization tools like ARX.
- Access: Permissions to access data sources and write to storage.
Hands-On: Step-by-Step Beginner-Friendly Setup Guide
Let’s set up a simple anonymization pipeline using Python and the faker library.
- Install Dependencies:
pip install pandas faker2. Create a Sample Dataset:
import pandas as pd
data = pd.DataFrame({
'name': ['John Doe', 'Jane Smith', 'Alex Brown'],
'ssn': ['123-45-6789', '987-65-4321', '456-78-9012'],
'age': [34, 28, 45]
})
data.to_csv('sample_data.csv', index=False)3. Write Anonymization Script:
from faker import Faker
import pandas as pd
fake = Faker()
df = pd.read_csv('sample_data.csv')
# Anonymize name and SSN
df['name'] = [fake.name() for _ in range(len(df))]
df['ssn'] = [fake.ssn() for _ in range(len(df))]
# Generalize age to ranges
df['age'] = pd.cut(df['age'], bins=[0, 30, 40, 50, 100], labels=['<30', '30-40', '40-50', '>50'])
df.to_csv('anonymized_data.csv', index=False)
print(df)4. Run the Script:
python anonymize.py 5. Verify Output:
Check anonymized_data.csv for anonymized data.
Real-World Use Cases
Scenario 1: Healthcare Data Sharing
A hospital uses anonymization to share patient data with researchers. PII like names and medical IDs are replaced with synthetic data, while diagnosis codes are preserved for analysis.
Scenario 2: Financial Data Testing
A bank anonymizes customer data for CI/CD testing environments. Credit card numbers are masked, and transaction amounts are generalized to ranges to prevent re-identification.
Scenario 3: Retail Analytics
An e-commerce company anonymizes user purchase data for third-party analytics. Email addresses are hashed, and purchase timestamps are rounded to the nearest day.
Industry-Specific Example: Telecom
A telecom provider anonymizes call detail records (CDRs) to share with marketing teams. Phone numbers are encrypted, and call durations are bucketed to ensure k-anonymity.
Benefits & Limitations
Key Advantages
- Compliance: Meets GDPR, HIPAA, and CCPA requirements.
- Data Utility: Preserves data for analytics and machine learning.
- Security: Reduces risk of data breaches.
- Scalability: Integrates with automated DataOps pipelines.
Common Challenges or Limitations
- Data Quality: Over-anonymization can reduce analytical value.
- Complexity: Requires expertise to balance privacy and utility.
- Performance: Computationally intensive for large datasets.
- Re-identification Risk: Advanced attacks may still exploit poorly anonymized data.
Best Practices & Recommendations
Security Tips
- Use strong anonymization techniques like differential privacy for sensitive data.
- Encrypt data in transit and at rest during anonymization.
Performance
- Parallelize anonymization tasks using cloud tools like AWS Lambda.
- Cache frequently used anonymization rules for efficiency.
Maintenance
- Regularly update anonymization policies to align with new regulations.
- Monitor re-identification risks using tools like ARX.
Compliance Alignment
- Align with GDPR’s “data minimization” principle.
- Maintain audit logs for regulatory audits.
Automation Ideas
- Integrate anonymization into CI/CD pipelines using Jenkins or GitLab.
- Use Apache Airflow to schedule anonymization tasks.
Comparison with Alternatives
| Feature | Anonymization | Pseudonymization | Data Encryption |
|---|---|---|---|
| Reversibility | Irreversible | Reversible | Reversible |
| Use Case | Analytics, sharing | Internal use | Secure storage |
| Compliance | GDPR, HIPAA | Partial GDPR | GDPR, PCI-DSS |
| Complexity | High | Medium | Medium |
| Data Utility | Moderate | High | Low |
When to Choose Anonymization
- Use anonymization for external data sharing or analytics.
- Opt for pseudonymization for internal testing with reversible needs.
- Choose encryption for secure storage but not analysis.
Conclusion
Anonymization is a vital component of DataOps, enabling secure, compliant, and efficient data workflows. As data privacy regulations evolve and DataOps adoption grows, anonymization will remain critical for balancing utility and security. Future trends include AI-driven anonymization and tighter integration with cloud-native tools.
Next Steps
- Explore tools like ARX or Presidio for advanced anonymization.
- Join communities like the DataOps Unleashed Slack group.