Introduction & Overview
Message queues are a cornerstone of modern data architectures, enabling asynchronous communication between systems in DataOps workflows. This tutorial explores message queues, their role in DataOps, and how they streamline data pipelines, ensuring scalability and reliability.
What is a Message Queue?
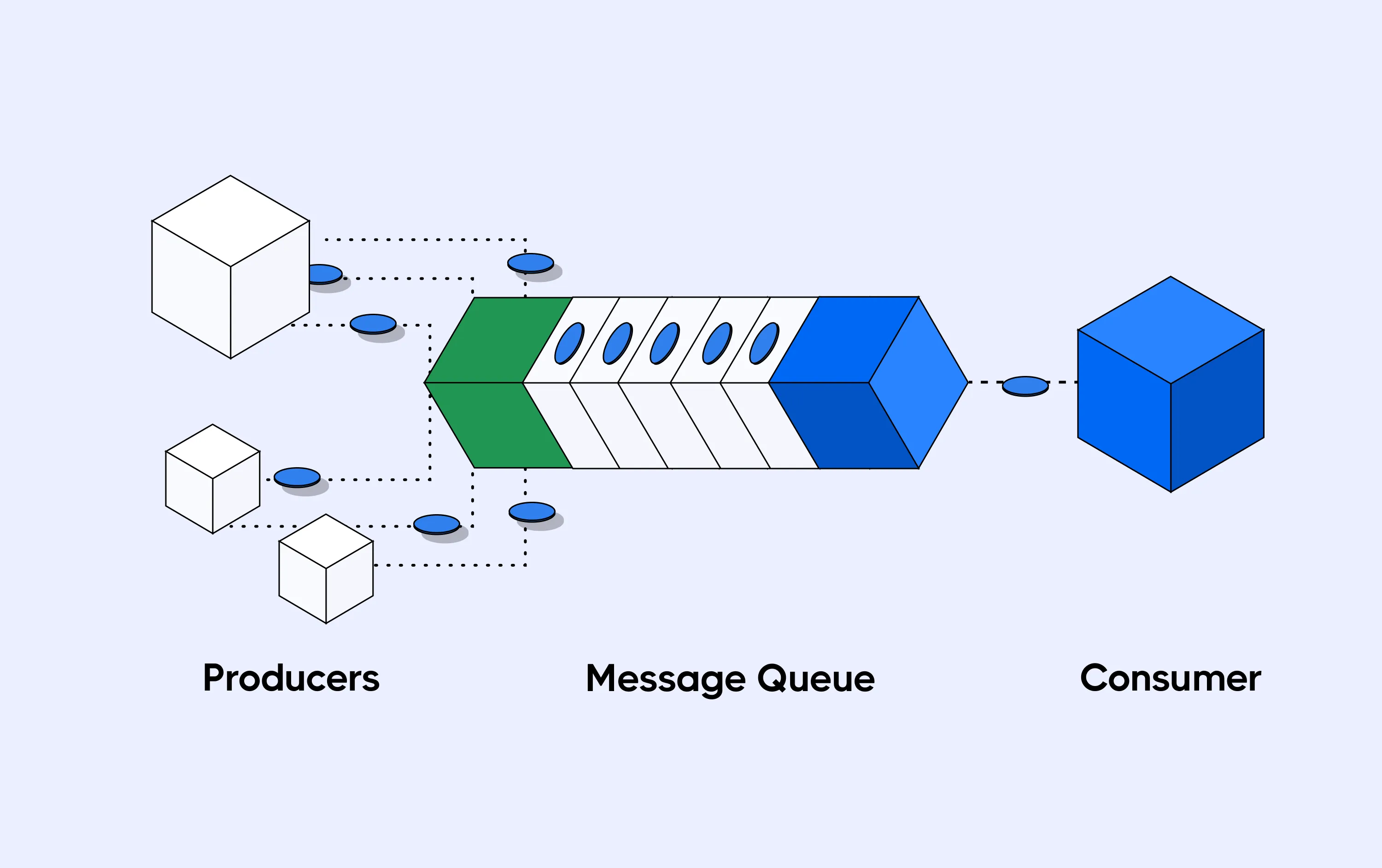
A message queue is a form of asynchronous service-to-service communication used in distributed systems. It allows producers to send messages to a queue, which consumers can process at their own pace, decoupling data processing components.
History or Background
- Origins: Message queues emerged in the 1980s with systems like IBM’s MQSeries, designed for reliable enterprise messaging.
- Evolution: Modern message queues like RabbitMQ (2007), Apache Kafka (2011), and Amazon SQS (2006) cater to big data and cloud-native environments.
- DataOps Relevance: As DataOps emphasizes automation and collaboration, message queues facilitate real-time data flows and orchestration across tools.
Why is it Relevant in DataOps?
- Decoupling: Separates data ingestion, processing, and delivery, reducing dependencies.
- Scalability: Handles high-throughput data pipelines in distributed environments.
- Reliability: Ensures data delivery with persistence and retry mechanisms.
- Real-Time Processing: Supports streaming analytics and monitoring, critical for DataOps agility.
Core Concepts & Terminology
Key Terms and Definitions
- Message: A unit of data (e.g., JSON, XML) sent from a producer to a consumer.
- Queue: A buffer that holds messages until they are processed.
- Producer: The entity generating and sending messages.
- Consumer: The entity retrieving and processing messages.
- Broker: The middleware (e.g., RabbitMQ, Kafka) managing the queue.
- Topics: In systems like Kafka, messages are categorized into topics for selective consumption.
- Dead Letter Queue (DLQ): Stores messages that fail processing for later analysis.
| Term | Definition | Example in DataOps |
|---|---|---|
| Producer | Application or service that sends messages to the queue. | ETL tool sending log data. |
| Consumer | Application or service that retrieves messages. | Spark job consuming batch data. |
| Message | Unit of data exchanged (JSON, XML, Avro, etc.). | Kafka message containing sensor readings. |
| Queue | Storage layer that holds messages until processed. | RabbitMQ queue of event logs. |
| Topic | In pub-sub systems, a channel to which producers publish and consumers subscribe. | Kafka topic user_activity. |
| Broker | Middleware that manages message queues. | Kafka broker or RabbitMQ server. |
| Dead Letter Queue (DLQ) | Queue for messages that failed to process. | Invalid JSON records stored for debugging. |
How It Fits into the DataOps Lifecycle
- Data Ingestion: Captures data from sources like IoT devices or databases.
- Processing: Enables parallel processing in ETL pipelines.
- Orchestration: Coordinates workflows across tools like Airflow or Jenkins.
- Monitoring: Feeds metrics to observability platforms for pipeline health checks.
Architecture & How It Works
Components and Internal Workflow
- Producer: Generates messages and pushes them to the queue via APIs or SDKs.
- Broker: Manages message storage, routing, and delivery. Examples: RabbitMQ (AMQP-based), Kafka (log-based), AWS SQS (cloud-native).
- Consumer: Polls or subscribes to the queue, processes messages, and acknowledges completion.
- Workflow:
- Producer sends a message to the broker.
- Broker stores the message in a queue or topic.
- Consumer retrieves the message, processes it, and sends an acknowledgment.
- Broker removes the processed message or moves failures to a DLQ.
Architecture Diagram (Text Description)
Imagine a diagram with:
- Left: Producers (e.g., IoT devices, APIs) sending messages.
- Center: A broker with queues/topics (e.g., RabbitMQ or Kafka cluster).
- Right: Consumers (e.g., ETL jobs, analytics engines) pulling messages.
- Arrows: Data flow from producers to queues to consumers, with a DLQ for failed messages.
- Cloud Layer: Integration with cloud services like AWS Lambda or Kubernetes for scaling.
[Producer] → [Message Broker / Queue] → [Consumer]
| | (Retry/DLQ) | |
Multiple Clusters/Topics Multiple
Producers Consumers
Integration Points with CI/CD or Cloud Tools
- CI/CD: Message queues integrate with Jenkins or GitLab CI/CD to trigger data pipeline jobs based on events.
- Cloud Tools:
- AWS: SQS/SNS for serverless workflows with Lambda.
- GCP: Pub/Sub for real-time analytics.
- Azure: Service Bus for enterprise messaging.
- Orchestrators: Airflow or Kubernetes uses queues to manage task scheduling.
Installation & Getting Started
Basic Setup or Prerequisites
- Hardware: Minimum 4GB RAM, 2-core CPU for small-scale deployments.
- Software: Docker (for containerized setup), Java (for Kafka), or Erlang (for RabbitMQ).
- Dependencies: SDKs for your programming language (e.g., Pika for Python, Confluent Kafka client).
Hands-on: Step-by-Step Beginner-Friendly Setup Guide
This guide sets up RabbitMQ using Docker and demonstrates a Python producer-consumer example.
- Install Docker:
sudo apt-get update
sudo apt-get install docker.io2. Run RabbitMQ:
docker run -d --name rabbitmq -p 5672:5672 -p 15672:15672 rabbitmq:3-management3. Install Python Client:
pip install pika4. Producer Script (save as producer.py):
import pika
# Connect to RabbitMQ
connection = pika.BlockingConnection(pika.ConnectionParameters('localhost'))
channel = connection.channel()
# Declare a queue
channel.queue_declare(queue='dataops_queue')
# Send a message
channel.basic_publish(exchange='', routing_key='dataops_queue', body='Hello DataOps!')
print(" [x] Sent 'Hello DataOps!'")
connection.close()5. Consumer Script (save as consumer.py):
import pika
def callback(ch, method, properties, body):
print(f" [x] Received {body.decode()}")
ch.basic_ack(delivery_tag=method.delivery_tag)
# Connect to RabbitMQ
connection = pika.BlockingConnection(pika.ConnectionParameters('localhost'))
channel = connection.channel()
# Declare the same queue
channel.queue_declare(queue='dataops_queue')
# Set up consumer
channel.basic_consume(queue='dataops_queue', on_message_callback=callback)
print(' [*] Waiting for messages. To exit press CTRL+C')
channel.start_consuming()6. Run the Scripts:
- Start consumer:
python consumer.py - Send message:
python producer.py
7. Verify: Access RabbitMQ management UI at http://localhost:15672 (default credentials: guest/guest).
Real-World Use Cases
Scenario 1: Real-Time ETL Pipeline
- Context: A retail company processes customer transactions in real-time.
- Implementation: Kafka captures transaction events from POS systems, streams them to a Spark cluster for processing, and stores results in a data warehouse.
- Benefit: Low-latency analytics for inventory management.
Scenario 2: CI/CD Data Pipeline Trigger
- Context: A DataOps team automates ML model retraining.
- Implementation: Jenkins pushes a message to AWS SQS when new data is available, triggering a Lambda function to preprocess data and retrain models.
- Benefit: Automated, event-driven workflows.
Scenario 3: Log Aggregation for Monitoring
- Context: A fintech company monitors application logs.
- Implementation: RabbitMQ collects logs from microservices, routing them to an ELK stack for visualization.
- Benefit: Centralized observability for compliance.
Industry-Specific Example: Healthcare
- Use Case: A hospital streams patient vitals from IoT devices to a queue, processed by an analytics engine for real-time alerts.
- Implementation: Google Pub/Sub integrates with BigQuery for predictive analytics.
- Benefit: Faster response to critical patient events.
Benefits & Limitations
Key Advantages
- Asynchronous Processing: Reduces bottlenecks in data pipelines.
- Scalability: Handles millions of messages with distributed brokers.
- Fault Tolerance: Persistent queues ensure no data loss.
- Flexibility: Supports multiple protocols (AMQP, MQTT, STOMP).
Common Challenges or Limitations
- Complexity: Managing brokers requires expertise in clustering and monitoring.
- Latency: May introduce delays in low-throughput scenarios.
- Cost: Cloud-based queues (e.g., AWS SQS) can be expensive at scale.
- Message Ordering: Not guaranteed in some systems (e.g., SQS standard queues).
Best Practices & Recommendations
Security Tips
- Authentication: Use strong credentials and role-based access (e.g., IAM for AWS SQS).
- Encryption: Enable TLS for data in transit and at rest.
- Access Control: Restrict queue access to specific IPs or VPCs.
Performance
- Batching: Group messages to reduce overhead.
- Scaling: Use partitioning (Kafka) or sharding (RabbitMQ) for high throughput.
- Monitoring: Track queue depth and consumer lag with tools like Prometheus.
Maintenance
- Purge Old Messages: Configure TTL (time-to-live) to avoid queue bloat.
- DLQ Management: Regularly analyze and reprocess failed messages.
- Backup: Snapshot queues for disaster recovery.
Compliance Alignment
- GDPR/HIPAA: Ensure encryption and audit logs for sensitive data.
- Automation: Use Infrastructure-as-Code (e.g., Terraform) to provision queues.
Comparison with Alternatives
| Feature/Tool | Message Queues (e.g., RabbitMQ, Kafka) | ETL Tools (e.g., Airflow) | Streaming (e.g., Apache Spark) |
|---|---|---|---|
| Purpose | Asynchronous messaging | Workflow orchestration | Real-time data processing |
| Strength | Decouples producers/consumers | Scheduled batch jobs | Complex transformations |
| Weakness | Setup complexity | Limited real-time support | Resource-intensive |
| Use Case | Event-driven pipelines | Batch ETL | Stream analytics |
When to Choose Message Queues
- Use Message Queues: For asynchronous, high-throughput, event-driven systems (e.g., real-time analytics, IoT).
- Use Alternatives: For batch processing (ETL tools) or complex stream transformations (Spark).
Conclusion
Message queues are indispensable in DataOps for enabling scalable, reliable, and decoupled data pipelines. As organizations adopt real-time analytics and cloud-native architectures, tools like Kafka and RabbitMQ will remain critical. Future trends include deeper integration with serverless platforms and AI-driven queue management.
Next Steps
- Experiment with the setup guide above.
- Explore advanced features like Kafka Streams or RabbitMQ clustering.
- Join communities: RabbitMQ Community, Kafka Documentation.