Introduction & Overview
Data contracts have emerged as a pivotal concept in modern data engineering, particularly within the DataOps framework. They address the critical need for reliable, consistent, and trusted data exchange between producers and consumers in complex data ecosystems. This tutorial provides a comprehensive guide to understanding and implementing data contracts, focusing on their role in DataOps to enhance data quality, collaboration, and scalability.
What are Data Contracts?
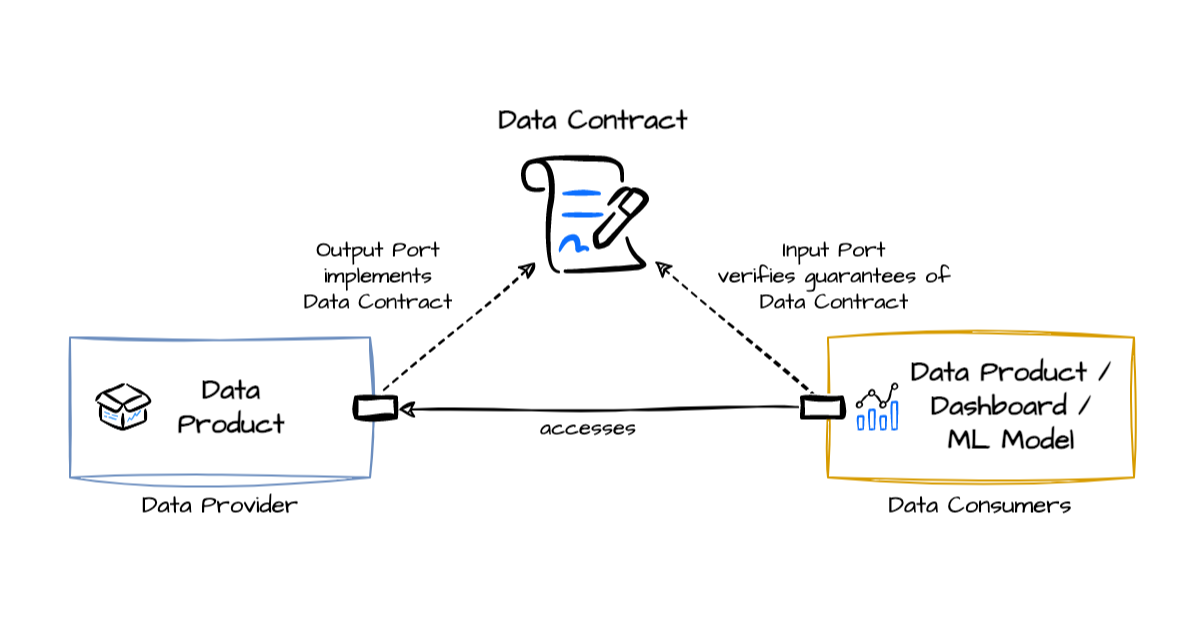
A data contract is a formal, enforceable agreement between data producers (e.g., software engineers, data pipelines) and data consumers (e.g., analysts, data scientists, business users) that defines the structure, quality, semantics, and operational expectations of data exchange. Unlike informal documentation, data contracts provide a standardized framework to ensure data reliability and interoperability across teams and systems.
History or Background
The concept of data contracts evolved from the need to address persistent data quality issues in traditional data architectures, such as schema drift, undocumented assumptions, and disconnected ownership. The term gained prominence around 2021, notably through contributions from engineers like Andrew Jones at GoCardless, who drew parallels between API contracts in software engineering and data exchange agreements. Data contracts build on principles from data governance, data mesh, and API design, adapting them to modern data platforms.
Why is it Relevant in DataOps?
DataOps is a methodology that applies agile practices, automation, and collaboration to data management, aiming to deliver high-quality data efficiently. Data contracts are integral to DataOps because they:
- Enhance Data Quality: Enforce schema and semantic consistency, reducing errors in downstream pipelines.
- Foster Collaboration: Bridge the gap between data producers and consumers, aligning technical and business stakeholders.
- Support Scalability: Enable distributed data architectures, such as data mesh, by standardizing data exchange.
- Automate Governance: Integrate with CI/CD pipelines to enforce data quality checks automatically.
- Reduce Technical Debt: Mitigate issues like schema drift and broken pipelines, streamlining data workflows.
Core Concepts & Terminology
Key Terms and Definitions
- Data Contract: A formal agreement specifying the schema, quality rules, semantics, and operational terms for data exchange.
- Schema: Defines the structure, format, and data types of fields (e.g., JSON Schema, Avro).
- Semantics: Describes the business meaning and logical consistency of data (e.g.,
created_atmust precedecompleted_at). - Service Level Agreements (SLAs): Specify operational expectations, such as data freshness or availability.
- Data Producer: The entity (e.g., service, pipeline) generating data.
- Data Consumer: The entity (e.g., analyst, ML model) using data.
- Schema Drift: Unintended changes in data structure that break downstream processes.
- Change Data Capture (CDC): A process to capture and propagate database changes, often used in data contract implementations.
| Term | Definition | Example |
|---|---|---|
| Producer | System creating or emitting data. | Kafka topic producing transactions. |
| Consumer | System using or analyzing data. | Data warehouse, ML pipeline. |
| Schema Contract | Agreement on data structure. | JSON schema for API responses. |
| SLAs (Service Level Agreements) | Performance/availability expectations. | Data freshness < 5 min. |
| SLOs (Service Level Objectives) | Quantifiable goals for SLAs. | 99.9% uptime for data feeds. |
| Validation Rules | Constraints enforced in pipeline. | price > 0, date not null. |
How It Fits into the DataOps Lifecycle
The DataOps lifecycle includes stages like data ingestion, transformation, validation, and delivery. Data contracts integrate as follows:
- Ingestion: Define expectations for incoming data from producers.
- Transformation: Ensure transformations adhere to contract schemas and semantics.
- Validation: Automate checks for schema compliance, quality, and SLAs.
- Delivery: Provide consumers with trusted, predictable data products.
- Monitoring: Track contract violations and schema drift in real-time.
Data contracts align with DataOps principles of automation, collaboration, and continuous improvement, acting as a “contract-first” approach to data management.
Architecture & How It Works
Components
A data contract typically includes:
- Schema Definitions: Field names, data types, required/optional fields, and valid ranges.
- Quality Rules: Completeness (e.g., 99% of records must have
customer_id), accuracy, and consistency checks. - Semantic Metadata: Business definitions, data lineage, and usage context.
- Operational Terms: Update frequency, retention policies, and support contacts.
- Versioning: Mechanisms to manage schema changes without breaking consumers.
Internal Workflow
- Contract Definition: Producers and consumers collaboratively define the contract using a schema format (e.g., JSON Schema, YAML).
- Validation: Contracts are enforced at the producer level (e.g., via API gateways, ETL pipelines) or database level (e.g., constraints).
- Enforcement: Automated checks ensure data complies with the contract before it reaches consumers.
- Monitoring: Tools like DataHub or Great Expectations monitor for violations or drift.
- Versioning & Communication: Changes are versioned, and stakeholders are notified to prevent downstream issues.
Architecture Diagram Description
Imagine a layered architecture:
- Data Producers: Services or databases generating data (e.g., microservices, Kafka streams).
- Contract Layer: A centralized registry (e.g., schema registry) storing and validating contracts.
- Enforcement Layer: Middleware (e.g., API gateways, ETL tools like dbt) enforcing schema and quality rules.
- Consumers: Dashboards, ML models, or analytics platforms consuming validated data.
- Monitoring Layer: Tools like Monte Carlo or DataKitchen for real-time contract monitoring.
Arrows indicate data flow from producers through the contract and enforcement layers to consumers, with monitoring feedback loops.
[Data Producer] ---> [Schema Contract Registry] ---> [Validation Engine]
| | |
| v v
| [CI/CD Pipeline] ------------> [Monitoring & Alerts]
| |
v v
[Data Consumer] <--- Contracts ensure compatibility ---> [Analytics/ML]
Integration Points with CI/CD or Cloud Tools
- CI/CD Pipelines: Data contracts integrate with tools like GitHub Actions or Jenkins to validate schemas during code deployment.
- Cloud Tools:
Installation & Getting Started
Basic Setup or Prerequisites
- Tools:
- A schema definition tool (e.g., JSON Schema, Avro, or dbt).
- A data platform (e.g., Snowflake, BigQuery, or Kafka).
- A validation tool (e.g., Great Expectations, pydantic for Python).
- A version control system (e.g., Git).
- Skills: Basic understanding of data engineering, schema design, and YAML/JSON.
- Environment: A cloud or on-premises data platform with access to CI/CD pipelines.
Hands-on: Step-by-Step Beginner-Friendly Setup Guide
This guide demonstrates setting up a data contract using dbt and Great Expectations for a simple orders table.
- Set Up dbt Project:
- Install dbt:
pip install dbt-core dbt-snowflake(assuming Snowflake as the data platform). - Initialize a dbt project:
dbt init my_project. - Configure
profiles.ymlfor your data warehouse connection.
- Install dbt:
- Define the Data Contract:
- Create a YAML file in
models/schema.ymlto define the contract.
- Create a YAML file in
version: 2
models:
- name: orders
config:
materialized: table
contract:
enforced: true
columns:
- name: order_id
data_type: string
constraints:
- type: not_null
- type: unique
description: "Unique identifier for the order"
- name: order_date
data_type: timestamp
constraints:
- type: not_null
description: "Date the order was placed"
- name: customer_id
data_type: string
constraints:
- type: not_null
description: "Unique customer identifier"
tests:
- dbt_utils.recency:
field: order_date
datepart: day
interval: 12. Define the Data Contract:
- Create a YAML file in models/schema.yml to define the contract.
version: 2
models:
- name: orders
config:
materialized: table
contract:
enforced: true
columns:
- name: order_id
data_type: string
constraints:
- type: not_null
- type: unique
description: "Unique identifier for the order"
- name: order_date
data_type: timestamp
constraints:
- type: not_null
description: "Date the order was placed"
- name: customer_id
data_type: string
constraints:
- type: not_null
description: "Unique customer identifier"
tests:
- dbt_utils.recency:
field: order_date
datepart: day
interval: 13. Create the dbt Model:
In models/orders.sql, define the model:
SELECT
order_id,
order_date,
customer_id
FROM {{ ref('raw_orders') }}4. Set Up Great Expectations:
Install: pip install great_expectations.
Initialize: great_expectations init.
Create an expectation suite for the orders table:
import great_expectations as ge
df = ge.from_pandas(pd.read_csv('sample_orders.csv'))
df.expect_column_values_to_not_be_null('order_id')
df.expect_column_values_to_match_regex('order_id', '^ORD[0-9]{10}$')
df.save_expectation_suite('orders_expectations.json')5. Integrate with CI/CD:
Add a GitHub Action to validate the contract on push:
name: Validate Data Contract
on: [push]
jobs:
validate:
runs-on: ubuntu-latest
steps:
- uses: actions/checkout@v3
- run: dbt run --profiles-dir .
- run: great_expectations checkpoint run orders_checkpoint6. Test the Setup:
Run great_expectations checkpoint run orders_checkpoint to validate data.
Run dbt run to materialize the model.
This setup enforces schema constraints and quality checks, ensuring reliable data for consumers.
Real-World Use Cases
- E-commerce: Order Processing:
- Scenario: An e-commerce platform needs consistent order data for analytics and inventory management.
- Application: A data contract defines the
orderstable schema, ensuringorder_idis unique,order_dateis timely, andcustomer_idlinks to a valid customer. dbt enforces the contract during ETL, reducing errors in downstream dashboards. - Industry: Retail.
- Fintech: Fraud Detection:
- Scenario: A fintech company monitors transactions for fraud using real-time data.
- Application: A data contract for transaction data specifies semantic rules (e.g.,
transaction_completed_ataftercreated_at) and SLAs for freshness. Kafka and a schema registry enforce the contract, enabling reliable ML models. - Industry: Financial Services.
- Healthcare: Patient Data Integration:
- Logistics: Shipment Tracking:
Benefits & Limitations
Key Advantages
- Improved Data Quality: Reduces errors by enforcing schemas and semantics.
- Enhanced Collaboration: Aligns producers and consumers, reducing miscommunication.
- Scalability: Supports distributed architectures like data mesh.
- Automation: Integrates with CI/CD for automated validation.
- Cost Savings: Reduces time spent on data cleaning (42% reduction observed).
Common Challenges or Limitations
- Cultural Resistance: Shifting ownership to producers requires organizational change.
- Initial Overhead: Defining contracts requires upfront effort.
- Tooling Complexity: Integrating with existing systems can be challenging.
- Schema Evolution: Managing versioning without breaking consumers is complex.
- Limited Adoption: Some teams may lack familiarity with contract-based workflows.
Best Practices & Recommendations
- Security Tips:
- Performance:
- Maintenance:
- Compliance Alignment:
- Automation Ideas:
Comparison with Alternatives
| Aspect | Data Contracts | Data Catalog | Data Governance Policies | API Contracts |
|---|---|---|---|---|
| Focus | Data exchange agreements | Metadata discovery | Policy enforcement | Service interface agreements |
| Scope | Schema, semantics, SLAs | Metadata inventory | Standards and compliance | API request/response structures |
| Enforcement | Producer-level, automated | Manual or semi-automated | Manual, policy-driven | Service-level, automated |
| Use Case | Data pipelines, analytics | Data discovery | Regulatory compliance | API integrations |
| Tools | dbt, Great Expectations, Schema Registry | Collibra, Alation | Informatica, Collibra | OpenAPI, Swagger |
| Pros | Ensures data quality, scalability | Simplifies data discovery | Ensures compliance | Standardizes API interactions |
| Cons | Setup complexity | Limited enforcement | Limited automation | Limited to API data |
When to Choose Data Contracts
- Choose Data Contracts: When you need enforceable, automated agreements for data quality and scalability in DataOps pipelines, especially in distributed systems like data mesh.
- Choose Alternatives:
Conclusion
Data contracts are a transformative approach in DataOps, enabling organizations to build reliable, scalable, and collaborative data ecosystems. By formalizing data exchange agreements, they address longstanding issues like schema drift and poor data quality, aligning technical and business teams. As data architectures evolve, data contracts will play a central role in supporting data mesh, real-time analytics, and automated governance.
Future Trends
- Increased Adoption: As DataOps matures, more organizations will adopt data contracts for distributed data management.
- AI Integration: Contracts will support AI-driven data pipelines, ensuring quality for ML models.
- Open Standards: Standards like Open Data Contract Standard (ODCS) will gain traction.
Next Steps
- Start with a pilot project in a high-impact data domain.
- Explore tools like dbt, Great Expectations, or schema registries.
- Engage stakeholders to define and review contracts collaboratively.