Introduction & Overview
Tracing in DataOps is a critical practice for ensuring observability and transparency in complex data pipelines. It enables teams to monitor, debug, and optimize data workflows by tracking the flow of data and operations across systems. This tutorial provides an in-depth exploration of tracing in the context of DataOps, covering its core concepts, architecture, setup, use cases, and best practices.
What is Tracing?
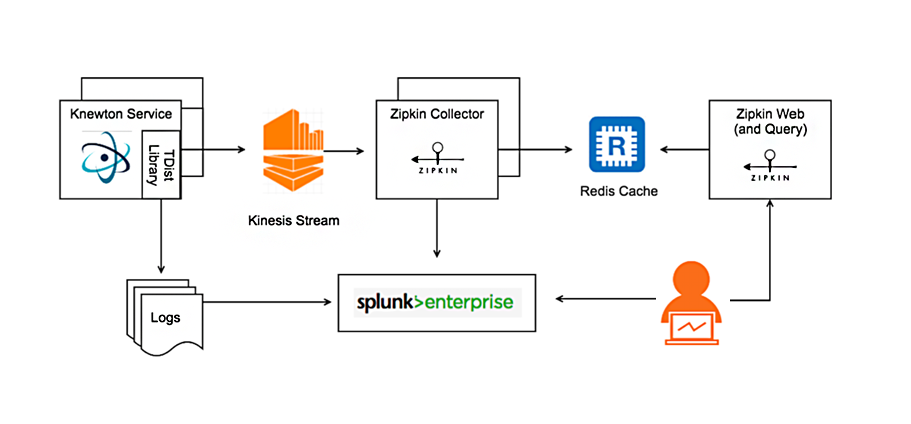
Tracing is the process of tracking and recording the journey of data or operations through a system, capturing detailed information about each step, such as execution time, inputs, outputs, and errors. In DataOps, tracing focuses on monitoring data pipelines, transformations, and integrations to ensure reliability and performance.
- Purpose: Provides visibility into data flows, identifies bottlenecks, and aids in debugging.
- Scope: Applies to batch processing, real-time streaming, ETL (Extract, Transform, Load) pipelines, and more.
History or Background
Tracing originated in software engineering as part of distributed systems observability, particularly with tools like OpenTelemetry and Jaeger. Its adoption in DataOps emerged as data pipelines grew in complexity with the rise of big data, cloud computing, and microservices.
- Evolution: From application performance monitoring (APM) to data pipeline observability.
- Key Milestones:
- 2016: OpenTracing project launched to standardize distributed tracing.
- 2019: OpenTelemetry merged OpenTracing and OpenCensus, becoming a CNCF standard.
- 2020s: Tracing adopted in DataOps for end-to-end pipeline visibility.
Why is it Relevant in DataOps?
DataOps emphasizes automation, collaboration, and agility in data management. Tracing aligns with these principles by:
- Enhancing Observability: Tracks data lineage and pipeline performance.
- Improving Collaboration: Provides shared visibility for data engineers, analysts, and DevOps teams.
- Supporting Automation: Enables automated monitoring and alerting for pipeline issues.
- Ensuring Compliance: Helps audit data flows for regulatory requirements.
Tracing is critical for organizations managing large-scale, distributed data systems where errors or delays can have significant business impacts.
Core Concepts & Terminology
Key Terms and Definitions
- Trace: A record of the end-to-end journey of a data operation through a pipeline.
- Span: A single unit of work within a trace, representing a specific operation (e.g., data ingestion, transformation).
- Trace ID: A unique identifier linking all spans in a trace.
- Context Propagation: Passing metadata (e.g., Trace ID) across systems to maintain trace continuity.
- Observability: The ability to understand system behavior through logs, metrics, and traces.
- Distributed Tracing: Tracking operations across multiple services or nodes in a distributed system.
| Term | Definition |
|---|---|
| Trace | A record of the full execution path of a request or pipeline. |
| Span | A single operation within a trace (e.g., a Spark job step). |
| Context Propagation | Passing trace IDs across different systems/services. |
| Data Lineage | Tracking how data moves and transforms through the pipeline. |
| Sampling | Collecting only a subset of traces for efficiency. |
| Distributed Tracing | Following requests/data across microservices or distributed systems. |
How It Fits into the DataOps Lifecycle
The DataOps lifecycle includes stages like data ingestion, processing, integration, and delivery. Tracing integrates as follows:
- Ingestion: Tracks data sources and ingestion times.
- Processing: Monitors transformations, computations, and errors.
- Integration: Ensures seamless data flow across tools (e.g., Apache Kafka, Airflow).
- Delivery: Verifies data reaches endpoints (e.g., dashboards, databases).
- Monitoring & Feedback: Provides insights for continuous improvement.
Architecture & How It Works
Components and Internal Workflow
Tracing in DataOps involves several components:
- Instrumentation: Code or agents added to data pipelines to generate trace data.
- Collector: Aggregates trace data from multiple sources (e.g., OpenTelemetry Collector).
- Storage: Persists trace data for analysis (e.g., Elasticsearch, Jaeger).
- Visualization: Tools like Jaeger, Grafana Tempo, or Zipkin display traces.
Workflow:
- A data operation (e.g., ETL job) is initiated.
- Instrumentation generates spans with metadata (e.g., timestamps, errors).
- Spans are grouped under a Trace ID and sent to the collector.
- The collector stores data in a backend (e.g., database).
- Visualization tools query the backend to display traces.
Architecture Diagram Description
Imagine a diagram with:
- Left: Data sources (databases, APIs) feeding into a pipeline.
- Center: Pipeline stages (ingestion, transformation, storage) with instrumentation generating spans.
- Right: Collector sending data to a storage backend, visualized via a UI (e.g., Jaeger).
- Arrows: Show data and trace flow, with context propagation linking spans.
Integration Points with CI/CD or Cloud Tools
- CI/CD: Tracing integrates with tools like Jenkins or GitHub Actions to monitor pipeline deployments.
- Cloud Tools:
- AWS X-Ray: Native tracing for AWS services.
- Google Cloud Trace: For GCP-based pipelines.
- Azure Monitor: Application Insights for tracing.
- DataOps Tools: Apache Airflow, dbt, and Kafka support tracing via OpenTelemetry.
Installation & Getting Started
Basic Setup or Prerequisites
- Software: Docker, a tracing tool (e.g., Jaeger, OpenTelemetry), and a programming language (e.g., Python).
- Environment: A data pipeline (e.g., Apache Airflow or a custom ETL script).
- Dependencies: Install OpenTelemetry SDK and exporter for your language.
Hands-On: Step-by-Step Beginner-Friendly Setup Guide
This guide sets up tracing for a Python-based ETL pipeline using OpenTelemetry and Jaeger.
- Install Jaeger:
Run Jaeger in Docker for local testing:
docker run -d --name jaeger \
-e COLLECTOR_ZIPKIN_HOST_PORT=:9411 \
-p 5775:5775/udp \
-p 6831:6831/udp \
-p 6832:6832/udp \
-p 5778:5778 \
-p 16686:16686 \
-p 9411:9411 \
jaegertracing/all-in-one:latestAccess Jaeger UI at http://localhost:16686.
2. Install OpenTelemetry:
pip install opentelemetry-api opentelemetry-sdk opentelemetry-exporter-jaeger3. Instrument a Python ETL Script:
from opentelemetry import trace
from opentelemetry.exporter.jaeger.thrift import JaegerExporter
from opentelemetry.sdk.trace import TracerProvider
from opentelemetry.sdk.trace.export import BatchSpanProcessor
import time
# Set up tracer
trace.set_tracer_provider(TracerProvider())
tracer = trace.get_tracer(__name__)
# Configure Jaeger exporter
jaeger_exporter = JaegerExporter(
agent_host_name="localhost",
agent_port=6831,
)
span_processor = BatchSpanProcessor(jaeger_exporter)
trace.get_tracer_provider().add_span_processor(span_processor)
# Sample ETL function
def extract_data():
with tracer.start_as_current_span("extract"):
time.sleep(1) # Simulate data extraction
print("Extracting data...")
return "data"
def transform_data(data):
with tracer.start_as_current_span("transform"):
time.sleep(0.5) # Simulate transformation
print("Transforming data...")
return data.upper()
def load_data(data):
with tracer.start_as_current_span("load"):
time.sleep(0.3) # Simulate loading
print("Loading data...")
# Run ETL pipeline
data = extract_data()
transformed = transform_data(data)
load_data(transformed)4. View Traces:
Open http://localhost:16686 in a browser, select the service (e.g., __main__), and view the trace timeline.
Real-World Use Cases
1. Debugging ETL Pipelines
- Scenario: A retail company’s ETL pipeline fails intermittently due to a slow database query.
- Application: Tracing identifies the slow query span, revealing a bottleneck in the transformation stage.
- Industry: Retail, e-commerce.
2. Monitoring Real-Time Data Streams
- Scenario: A financial firm processes stock market data in real-time using Apache Kafka.
- Application: Tracing tracks data flow from Kafka to downstream analytics, detecting delays.
- Industry: Finance.
3. Ensuring Data Lineage for Compliance
- Scenario: A healthcare organization must audit data flows for GDPR compliance.
- Application: Tracing records the journey of patient data through pipelines, ensuring traceability.
- Industry: Healthcare.
4. Optimizing Machine Learning Pipelines
- Scenario: A tech company trains ML models with data from multiple sources.
- Application: Tracing monitors data preprocessing and model training, identifying inefficiencies.
- Industry: Technology, AI.
Benefits & Limitations
Key Advantages
- Visibility: Provides end-to-end pipeline observability.
- Debugging: Pinpoints errors or bottlenecks quickly.
- Compliance: Supports data lineage and auditability.
- Scalability: Works with distributed systems and cloud environments.
Common Challenges or Limitations
- Overhead: Instrumentation can add performance overhead.
- Complexity: Requires expertise to set up and interpret traces.
- Cost: Storage and processing of trace data can be expensive at scale.
- Tooling: Not all DataOps tools support tracing natively.
Best Practices & Recommendations
Security Tips
- Restrict Access: Secure trace data with role-based access control.
- Anonymize Data: Remove sensitive information from traces.
- Encrypt Communication: Use TLS for trace data transmission.
Performance
- Sampling: Use sampling to reduce trace volume (e.g., probabilistic sampling in OpenTelemetry).
- Optimize Spans: Limit span granularity to avoid excessive data.
- Distributed Storage: Use scalable backends like Elasticsearch for large-scale tracing.
Maintenance
- Retention Policies: Set trace retention periods to manage storage costs.
- Regular Updates: Keep instrumentation libraries and tools updated.
Compliance Alignment
- Align with GDPR, HIPAA, or CCPA by ensuring traces capture data lineage without storing sensitive data.
Automation Ideas
- Integrate tracing with CI/CD for automated pipeline monitoring.
- Use alerting tools (e.g., Grafana) to notify teams of trace anomalies.
Comparison with Alternatives
| Feature/Tool | Tracing (OpenTelemetry) | Logging | Metrics |
|---|---|---|---|
| Purpose | Tracks data flow across systems | Records discrete events | Measures system performance |
| Granularity | Detailed, operation-level | Event-based | Aggregate data |
| Use Case | Debugging pipelines, lineage | Error tracking | Performance monitoring |
| Tools | Jaeger, Zipkin, Grafana Tempo | ELK Stack, Splunk | Prometheus, Grafana |
| Overhead | Moderate | High for verbose logs | Low |
| DataOps Fit | Best for pipeline observability | General debugging | Performance tuning |
When to Choose Tracing
- Use tracing for end-to-end visibility in complex, distributed pipelines.
- Choose logging for discrete error tracking or auditing.
- Opt for metrics for high-level performance monitoring.
Conclusion
Tracing is a cornerstone of DataOps observability, enabling teams to monitor, debug, and optimize data pipelines effectively. By integrating with modern tools like OpenTelemetry and Jaeger, it provides unparalleled visibility into complex workflows. As DataOps evolves, tracing will become even more critical with the rise of real-time analytics and AI-driven pipelines.
Next Steps:
- Experiment with the provided setup guide.
- Explore advanced tracing features like custom attributes or sampling.
- Join communities like CNCF or OpenTelemetry for updates.
Official Docs & Communities
- OpenTelemetry
- Jaeger
- Zipkin
- DataOps Community