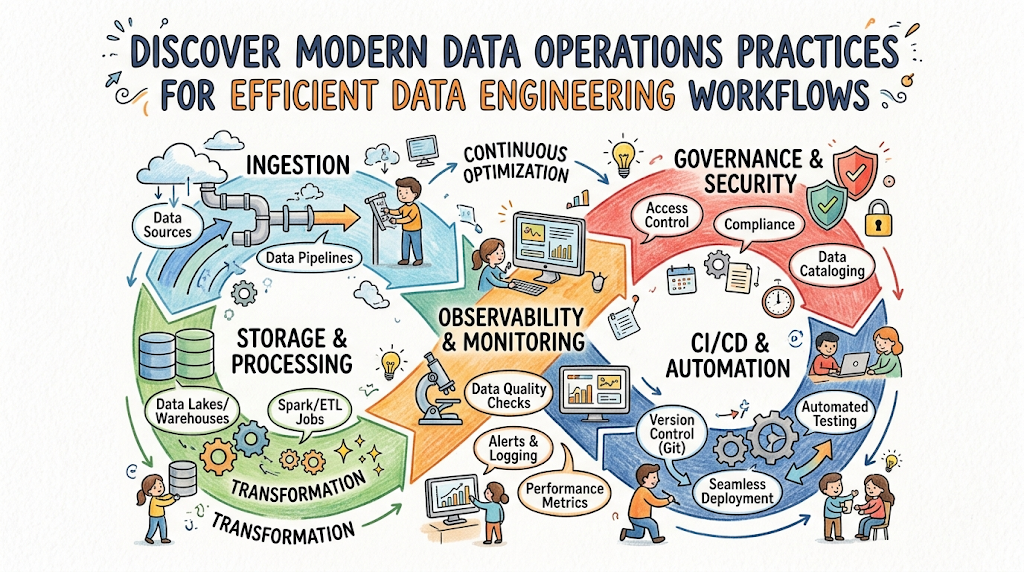
Introduction
When data pipelines break silently, business leaders make decisions based on outdated or incorrect information. Engineers spend their weekends fixing code instead of building new and exciting features.DataOps is a collaborative data management practice designed to improve the speed and accuracy of data analytics. Think of it as manufacturing efficiency brought directly into the world of data engineering workflows.It combines automated testing, continuous integration, and team collaboration to eliminate errors before they reach business users. This modern framework transforms how teams handle information across the entire data lifecycle management spectrum.In this beginner-friendly guide, you will learn the core principles, essential tools, and clear career paths within this growing field. You will discover how organizations transition from chaotic data handling to structured, automated analytics pipelines.Ready to master these modern concepts and build reliable data systems? Explore structured learning opportunities and industry-guided programs at DataOpsSchool to kickstart your data journey today.
Evolution of Data Management
Traditional Data Handling Challenges
Years ago, data management operated in heavily isolated silos where software developers, data analysts, and IT administrators rarely spoke. Requests for new data required manual intervention, complex approvals, and months of custom coding work.
Whenever a source system changed its database format, downstream reports broke without warning or explanation. These manual processes made it nearly impossible to maintain consistent data quality across enterprise systems.
Rise of Modern Data Engineering Practices
As cloud computing expanded, organizations realized they needed faster, more scalable ways to process information. This demand sparked the rise of the modern data stack, characterized by flexible cloud data warehouses and powerful transformation tools.
Data engineering evolved from a simple support function into a highly strategic software engineering discipline. Teams began treating data as a product that requires version control, automated testing, and reliable infrastructure.
Shift Toward DataOps Culture
Even with advanced cloud tools, technology alone could not solve communication barriers between data creators and data consumers. The industry needed a cultural shift similar to how DevOps revolutionized software development practices.
This realization birthed the modern DataOps movement, focusing on people, processes, and automated technology combined. It turns data engineering from a series of fragile, manual tasks into a predictable, highly automated factory.
Core Concepts of DataOps
Data Pipelines and Automation
A data pipeline is the foundational highway that moves information from source systems to final analytics destinations. DataOps heavily prioritizes data pipeline automation to eliminate manual data movement and human error entirely.
Automated pipelines run on schedules or trigger instantly when new information arrives in the system. This ensures that business dashboards stay updated without requiring constant manual intervention from engineers.
Collaboration Between Teams
Data projects involve diverse groups, including data scientists, business analysts, data engineers, and security compliance experts. DataOps establishes common workflows, shared tools, and open communication channels between these unique roles.
By breaking down organizational walls, teams can build and deploy analytics features in days rather than months. Everyone works with a unified understanding of how data flows through the enterprise.
Continuous Data Integration and Delivery
Borrowing from software engineering, DataOps introduces the concept of CI/CD for data pipelines and analytics code. When an engineer updates a data transformation script, the changes undergo automated testing before entering production.
This ensures that new code does not accidentally corrupt existing reports or disrupt downstream business operations. Delivery becomes a continuous, smooth, and highly predictable process.
Data Quality and Governance
High speed means very little if the underlying information is inaccurate, misleading, or poorly formatted. DataOps embeds automated data quality checks directly into every stage of the active pipeline.
If a data delivery contains missing values or invalid formats, the system alerts the team immediately. This prevents bad data from ever reaching final business dashboards or machine learning models.
Data Lifecycle Management
Every piece of information has a lifecycle, from initial ingestion to ultimate deletion or archival. DataOps provides structured oversight for data lifecycle management, ensuring data remains secure, accessible, and compliant.
Teams can track exactly where data came from, how it changed, and who accessed it over time. This rigorous tracking simplifies compliance with global privacy regulations and internal data policies.
Key Principles of DataOps
Automation in Data Workflows
Automation is the primary engine that drives modern data operations forward successfully. By automating repetitive tasks like ingestion, formatting, and scheduling, engineers free up time for valuable innovation.
Automated workflows run consistently day or night, reducing operational costs and accelerating business insights significantly. If an unexpected error occurs, automated alerting systems notify engineers immediately.
Continuous Improvement
DataOps is not a static milestone; it is an ongoing journey of refinement and optimization. Teams constantly monitor pipeline performance, processing speeds, and error rates to identify system bottlenecks.
By analyzing these operational metrics, organizations can incrementally improve their data engineering workflows over time. Each small optimization leads to more resilient systems and happier data consumers.
Collaboration Across Teams
True data operations success relies on shared responsibility and mutual trust across the entire corporate structure. Engineers, analysts, and business stakeholders must collaborate closely to define clear data goals.
When everyone uses the same definitions and platforms, misunderstandings disappear completely. Collaboration ensures that the data team builds products that truly solve real business problems.
Data Quality First Approach
In a mature DataOps culture, data quality is never treated as an afterthought or a final cleanup step. Quality checks are placed at the very beginning, middle, and end of every analytics journey.
This proactive approach ensures that anomalies are caught at the source before causing business confusion. High data quality builds long-term organizational trust in data-driven decision-making tools.
Agile Data Management
Traditional data projects followed rigid, multi-month timelines that struggled to adapt to changing market conditions. DataOps adopts agile methodologies, breaking massive data projects down into smaller, manageable, two-week delivery cycles.
This allows teams to deliver value rapidly and pivot easily when business requirements shift unexpectedly. Frequent, small updates reduce deployment risks and keep stakeholders continuously engaged.
DataOps vs Traditional Data Management
Core Differences Explained
Traditional data management relies heavily on manual checklists, human oversight, and specialized siloed teams. DataOps replaces this slow, fragmented approach with automated systems and unified, cross-functional collaboration.
Workflow and Efficiency Comparison
The following table highlights the operational shifts between legacy practices and modern data operations:
| Feature | Traditional Data Management | Modern DataOps Approach |
| Deployment Speed | Months of manual validation | Minutes through automated pipelines |
| Error Detection | Found by angry business users | Caught instantly by automated alerts |
| Team Structure | Siloed engineers and analysts | Collaborative, cross-functional teams |
| Testing Practices | Occasional manual spot checks | Continuous automated quality testing |
| Process Control | Low visibility, brittle systems | High visibility, resilient architecture |
Role of Automation
In legacy environments, moving data from a database to a report required manual SQL scripts and file transfers. DataOps uses sophisticated data orchestration engines to manage these complex dependencies automatically.
Automation ensures that tasks execute in the correct order and recover gracefully from temporary network glitches. This turns data management from a manual craft into a scalable industrial process.
Business Impact Differences
Slow data management causes missed market opportunities, frustrated employees, and flawed corporate strategies. DataOps empowers organizations to act on fresh, accurate insights ahead of their industry competitors.
By reducing pipeline downtime, companies save significant engineering hours and lower cloud infrastructure bills. Reliable data operations ultimately convert raw information into a measurable competitive advantage.
Essential DataOps Concepts Beginners Must Know
Data Pipelines
A data pipeline is a series of automated data processing steps connected in a structured sequence. It extracts data from sources, transforms it into useful formats, and loads it into analytics repositories.
ETL and ELT Concepts
ETL stands for Extract, Transform, and Load, where data is modified before reaching its destination warehouse. ELT reverses this, loading raw data into powerful modern cloud data warehouses first, then transforming it later.
Data Orchestration
Data orchestration is the centralized coordination of various automated tasks within your broader data engineering workflows. It ensures that step B runs only after step A completes successfully, managing all operational dependencies.
Data Observability
Data observability is the continuous monitoring of data health, pipeline performance, and system lineage across the enterprise. It helps teams answer whether the data is fresh, accurate, and arriving on time.
Data Governance and Compliance
Data governance is the framework of rules, roles, and standards ensuring secure and proper data utilization. It guarantees that data management processes respect user privacy laws and internal security policies.
Real-World Use Cases of DataOps
Business Intelligence Systems
Retail companies use automated analytics pipelines to track daily sales performance across thousands of global stores. DataOps ensures that executive dashboards update reliably every morning with verified, error-free revenue numbers.
Real-Time Analytics Platforms
Ride-sharing applications rely on real-time data operations to match drivers with nearby passengers instantly based on location. These automated systems process millions of streaming data points per second without experiencing processing delays.
Cloud Data Warehouses
Financial institutions migrate legacy on-premise storage systems into highly scalable, modern cloud data warehouses using DataOps frameworks. This shift allows analysts to query massive historical transaction datasets in seconds rather than hours.
Machine Learning Data Pipelines
E-commerce platforms use automated data pipelines to feed fresh customer behavioral data into product recommendation engines. Continuous data delivery ensures that machine learning models suggest relevant products based on recent browsing trends.
Enterprise Reporting Systems
Global healthcare organizations use data lifecycle management to aggregate patient records safely from hundreds of regional clinics. Automated governance workflows keep this sensitive healthcare data fully compliant with strict regional privacy regulations.
Common Mistakes in DataOps Adoption
Poor Data Quality Management
Many teams focus entirely on data delivery speed while completely ignoring automated data quality validations. Moving inaccurate data faster through automated pipelines only results in widespread business confusion and broken trust.
Lack of Automation
Attempting to implement a modern data culture while clinging to manual deployment methods creates severe operational bottlenecks. Without automated pipelines, engineering teams remain trapped in an endless loop of manual firefighting.
Weak Team Collaboration
Buying expensive modern data stack tools will fail if engineers and analysts refuse to communicate openly. DataOps requires a deep cultural commitment to shared goals, collaborative toolsets, and transparent workflow planning.
Ignoring Data Governance
Building rapid analytics pipelines without embedding proper data governance standards creates immense compliance risks. Unsecured data pipelines can expose sensitive customer details, leading to regulatory fines and reputational damage.
Overcomplicated Pipelines
Beginners often make the mistake of stringing together dozens of complex tools for simple data tasks. Overengineered architectures are incredibly difficult to maintain, troubleshoot, and scale as business needs evolve.
Essential Tools & Technologies in DataOps
While DataOps is primarily a methodology and culture, it utilizes a powerful ecosystem of modern technologies. Understanding these tools conceptually helps beginners navigate the modern data landscape effectively.
- Apache Airflow: A popular open-source data orchestration platform used to schedule and monitor complex engineering workflows.
- dbt (Data Build Tool): A transformation tool that allows analysts and engineers to write clean SQL and run automated data quality tests.
- Snowflake: A cloud data warehouse built for speed, scalability, and seamless data sharing across organizations.
- Databricks: A unified analytics platform designed for massive data processing, engineering, and collaborative machine learning.
- Apache Kafka: A distributed streaming platform used for building real-time data pipelines and handling live data feeds.
- Data Observability Platforms: Specialized software systems that monitor pipeline health, track data drift, and alert teams to anomalies.
- Cloud Data Warehouses: Centralized modern cloud repositories that allow enterprises to store and analyze petabytes of business data efficiently.
Career Path in DataOps
Skills You Must Learn
- SQL Basics: The universal language used to communicate with databases, filter information, and perform data transformations.
- Data Engineering Fundamentals: Understanding how data structures, databases, and file formats work behind the scenes.
- Cloud Platforms: Familiarity with modern cloud ecosystems that host data infrastructure and analytics applications.
- Data Pipelines: Conceptual knowledge of how to move data safely from source systems to destination warehouses.
- Analytics Understanding: Knowing how business users interpret charts, metrics, and key performance indicators.
- Scripting Basics: Learning fundamental programming logic to help automate repetitive file management and API tasks.
Learning Roadmap
Start your career journey by mastering foundational data querying concepts using standard SQL syntax. Next, explore how modern cloud data warehouses store information and scale resources on demand.
Once comfortable with storage, study data orchestration concepts to understand how multiple pipeline steps link together. Finally, learn how to embed automated testing and data observability into your workflows.
Certifications & Learning Paths
Industry certifications from major cloud providers and data platforms can validate your conceptual knowledge to hiring managers. Focus on learning paths that emphasize data engineering workflows, pipeline automation, and modern data operations.
Practical, project-based educational courses are highly effective for understanding how these concepts apply to actual business challenges.
Career Opportunities
The demand for professionals who understand automated data systems is growing exponentially across every major industry. Job roles include DataOps Engineers, Data Engineers, Analytics Engineers, and Cloud Data Architects.
Companies are actively searching for individuals who can bridge the traditional gap between pure software development and data analytics.
Learning Resources from DataOpsSchool
Navigating the modern data stack can feel completely overwhelming for beginners trying to enter the tech field alone. Structured educational programs provide the clear guidance, mentorship, and foundational knowledge needed to succeed.
To accelerate your career and master these concepts comprehensively, explore the beginner-friendly learning paths available at DataOpsSchool today.
Future of DataOps
AI-Driven Data Pipelines
The future will see data pipelines that automatically detect structural changes in source databases and adapt without breaking. Artificial intelligence will predict system bottlenecks and optimize cloud resource allocations before performance slows down.
Real-Time Data Ecosystems
As batch processing fades, organizations will shift entirely toward continuous, real-time data operations. Businesses will analyze operational events the exact millisecond they occur, making instantaneous customer adjustments possible.
Autonomous Data Operations
Future data platforms will feature self-healing capabilities, automatically correcting common data quality errors without human intervention. This automation will allow engineering teams to focus purely on business strategy rather than routine maintenance.
Data + AI Integration
As corporate machine learning models expand, the need for clean, reliable data pipelines becomes absolute. DataOps will serve as the essential foundation ensuring AI models receive trusted, compliant, and fresh training information.
Future Skills Required
Professionals entering this field will need to balance technical engineering knowledge with strategic data governance expertise. Understanding automation, system architecture, and collaborative team communication will become the ultimate career superpowers.
FAQs
- What is DataOps in simple terms?DataOps is a collaborative data management practice focused on improving the speed, quality, and accuracy of analytics pipelines through automation.
- Is DataOps the same as DevOps?No. DevOps focuses on software development and deployment, while DataOps focuses specifically on building and managing automated data pipelines and analytics systems.
- What is a data pipeline?A data pipeline is a structured sequence of automated steps that extracts data from sources, transforms it, and loads it into a destination.
- Why is data quality important in data engineering workflows?High data quality ensures that business leaders make accurate decisions based on trusted, verified information rather than flawed data.
- What does data orchestration mean?Data orchestration is the centralized coordination and scheduling of various automated tasks within a data pipeline to ensure they run in the correct order.
- What is the modern data stack?The modern data stack is a collection of cloud-native tools designed to simplify data ingestion, storage, transformation, and analysis for organizations.
- Do I need to be a programmer to learn DataOps?No. Beginners can start by learning basic SQL and understanding data management concepts before moving on to basic automation scripting.
- What is the difference between ETL and ELT?ETL transforms data before loading it into a warehouse, while ELT loads raw data into the warehouse first and transforms it later.
- What is data observability?Data observability is the continuous monitoring of pipeline health, freshness, and quality metrics to detect and resolve errors automatically.
- What career opportunities exist in this field?Professionals can pursue rewarding roles such as DataOps Engineers, Modern Data Engineers, Analytics Engineers, and Cloud Data Architects.
Final Summary
Embracing DataOps transforms how organizations handle information, turning brittle data pipelines into resilient, automated delivery systems. By focusing on collaboration, rigorous data quality checks, and continuous integration, teams eliminate the chaos of traditional data management.
As modern data engineering workflows evolve, mastering these concepts becomes vital for anyone pursuing a data career. Cultivating an automated, quality-first mindset empowers businesses to make confident, data-driven decisions in real time.