Introduction
In the contemporary corporate landscape, an organization’s computational infrastructure functions as its nervous system. Strategic choices—ranging from inventory optimization algorithms to hyper-targeted marketing campaigns—rely entirely on the integrity of underlying data repositories.
When structural integrity fails within these systems, business strategies quickly degrade. A single corrupted column, misaligned schema, or silent data drift event can cascade through business intelligence layers, resulting in invalid executive dashboards, regulatory compliance failures, and lost revenue.
To bridge the gap between technical infrastructure and strategic execution, specialized training platforms like DataOpsSchool provide practitioners with the exact architectural patterns needed to design, deploy, and scale self-healing data delivery ecosystems.
In Simple Terms
Imagine running a massive factory that packages drinking water. If you only check the water quality at the very end of the assembly line after thousands of bottles are sealed, you will waste time, money, and materials when a contaminant enters the system. DataOps works like automated digital sensors installed at every single pipe, valve, and filtration stage, catching impurities the second they appear so bad data never reaches the final consumer.
Real-World Example
A prominent global e-commerce enterprise experienced a severe localization parsing bug during an overnight database migration. Currency exchange fields from international storefronts were ingested without applying the correct regional divisor metrics. Because the analytical dashboard lacked end-to-end data validation checks, automated inventory procurement scripts interpreted a $10.00 product value as $1,000.00. This triggered a systemic cancellation of supply chain orders, costing the firm over $450,000 in lost transactional volume before the anomaly was identified.
Common Mistake
Treating data quality as an isolated cleanup project handled exclusively by downstream analytics teams. When data analysts must spend 40% of their operational hours writing manual SQL clean-up scripts, the organization fails to address the root systemic failures embedded within the upstream ingestion pipelines.
Key Takeaways
- Inaccurate data propagates exponentially across enterprise reporting layers, compounding minor upstream anomalies into major strategic mistakes.
- Traditional data management architectures fail to scale alongside modern multi-source cloud data lakes and real-time streaming infrastructure.
- DataOps transforms quality control from a reactive, manual debugging chore into an automated, integrated step within the engineering pipeline.
Featured Snippet
How Does DataOps Ensure Data Quality and Accuracy?
DataOps ensures data quality and accuracy by embedding automated testing, continuous observability, and strict validation checks directly into CI/CD data pipelines. By treating data infrastructure as code, DataOps automates schema verification, isolates anomalies via circuit breakers, and tracks data lineage, transforming quality management from a reactive manual process into a proactive, continuous engineering workflow.
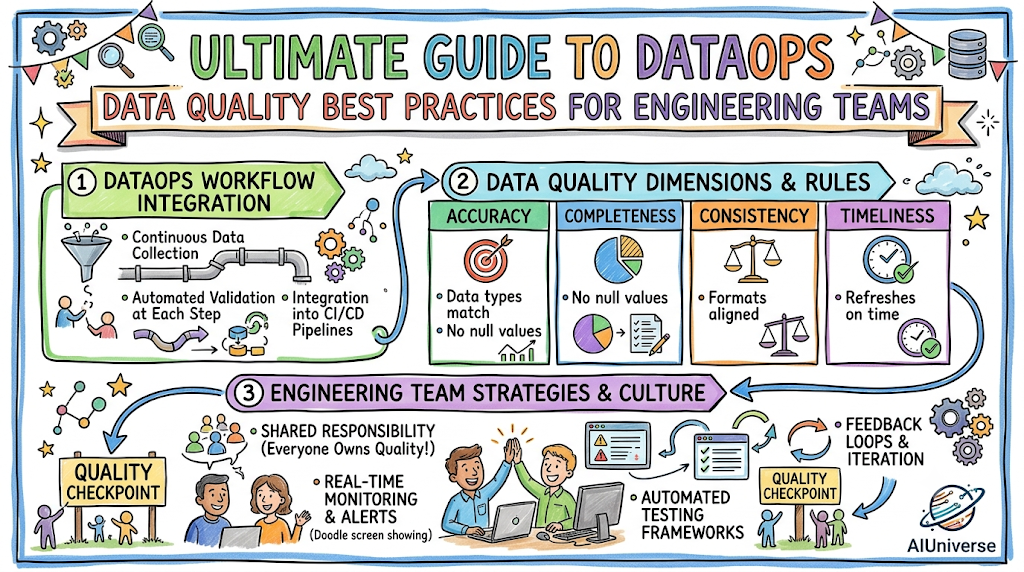
Understanding Data Quality
What Is Data Quality?
Data quality is a multi-dimensional measurement of how well a given dataset serves its intended operational, analytical, and governance requirements. It is not an absolute state; rather, it represents a spectrum of reliability, structural integrity, and contextual relevance. In high-throughput data platforms, quality is defined by programmatic validation rules that ensure incoming data structures exactly match downstream business logic expectations.
Why Data Accuracy Matters
Data accuracy serves as the core foundation for algorithmic trust. If an enterprise feeds inaccurate feature sets into machine learning models or financial optimization algorithms, the outputs become actively dangerous to business operations. High data accuracy ensures that the digital representation of an asset, financial transaction, or user profile perfectly aligns with real-world conditions.
Business Impact of Poor Data Quality
The financial and operational consequences of unverified data systems are severe. Beyond direct financial losses from operational errors, poor data quality degrades organizational velocity. Teams stop trusting their business intelligence reporting, falling back on subjective decision-making.
Furthermore, data quality deficiencies expose enterprises to regulatory fines under frameworks such as GDPR, CCPA, and Basel III, where reporting discrepancies can trigger mandatory independent audits.
Key Characteristics of High-Quality Data
To accurately evaluate systemic health, data teams analyze six primary dimensions of quality management:
- Accuracy: The degree to which data values correctly reflect the true real-world attributes they describe.
- Completeness: The presence of all required data elements across designated fields without unexpected null values or omissions.
- Consistency: The alignment of matching datasets across disparate systems, platforms, and chronological intervals.
- Timeliness: The interval between data generation and availability within downstream analytical repositories.
- Validity: The adherence of data elements to strict structural formats, predefined data types, and range constraints.
- Uniqueness: The elimination of redundant records or duplicate entries within unified data entities.
┌────────────────────────────────────────────────────────┐
│ Data Quality Dimensions │
├──────────────┬──────────────┬──────────────┬───────────┤
│ Accuracy │ Completeness │ Consistency │Timeliness │
├──────────────┴──────────────┼──────────────┴───────────┤
│ Validity │ Uniqueness │
└─────────────────────────────┴──────────────────────────┘
In Simple Terms
Think of data quality like the dashboard metrics inside an airplane cockpit. If the altitude gauge shows you are at 10,000 feet when you are actually at 2,000 feet (poor accuracy), or if the fuel gauge simply goes blank midway through a flight (poor completeness), the pilot cannot safely navigate the plane. High-quality data means every instrument shows the exact same, correct information in real-time.
Real-World Example
A regional healthcare provider unified patient records across three acquired clinical platforms. Because the ingestion pipelines lacked consistency validation, date-of-birth formats fluctuated between YYYY-MM-DD and DD/MM/YYYY. This structural misalignment caused automated pharmacy systems to flag safe adult medication dosages as pediatric overdoses, freezing the clinical distribution workflow for 72 hours until database engineers standardized the underlying schemas.
Common Mistake
Relying entirely on validation rules that check if a field is populated while ignoring whether the values are contextually accurate. A database column can boast 100% completeness with strings like "N/A", "Null", or "000000", completely bypassing basic validation alerts while corrupting downstream machine learning models.
Key Takeaways
- Data quality is context-dependent and must be measured across multiple structural dimensions, not just row counts.
- Poor data quality slows down engineering teams, reduces organizational trust, and creates major legal compliance risks.
- Establishing clear, automated tests for all six dimensions of quality is a prerequisite for scaling modern data operations.
What Is DataOps?
Definition of DataOps
DataOps is an automated, collaborative methodology designed to improve the quality, velocity, and predictability of data analytics and data engineering workflows. Modeled after the successes of DevOps in software development, DataOps unifies data creators, data engineers, analytics professionals, and business stakeholders under a shared, automated operational framework.
Evolution of Data Operations
Historically, data operations operated under rigid, slow-moving structures. Data warehouse teams spent months constructing monolithic Extract, Transform, Load (ETL) paths that broke whenever a source database changed a single column schema.
As cloud-native environments introduced high-velocity data collection, these brittle systems failed. DataOps emerged to replace manual data management with automated validation, infrastructure-as-code (IaC), continuous testing, and real-time observability.
Core Principles of DataOps
The operational foundation of DataOps is guided by several core principles adapted from agile methodologies:
- Continuous Delivery: Data changes, schema migrations, and transformation models are continuously integrated and deployed via automated delivery tracks.
- Infrastructure as Code (IaC): Every pipeline definition, orchestration dag, and infrastructure element is treated as version-controlled code.
- Automated Orchestration: Eliminates human intervention by automating processing stages, error handling, and data dependency resolution.
- Collaborative Ownership: Breaks down traditional engineering siloes by creating clear, code-driven contracts between data producers and data consumers.
Why DataOps Matters for Modern Organizations
Modern enterprise architectures process diverse data types across batch, streaming, and API-driven layers. Without DataOps, managing these complex environments becomes unfeasible. DataOps provides the structural guardrails required to accelerate engineering cycles while simultaneously improving data accuracy across the organization.
In Simple Terms
DataOps is like upgrading a manual assembly line to a fully automated smart factory. Instead of having engineers manually check code, build databases from scratch, and email spreadsheets to fix errors, you build an automated system that tests itself, deploys code updates instantly, and alerts engineers the moment a pipeline component malfunctions.
Real-World Example
A logistics enterprise historically required three weeks to deploy modifications to its supply chain forecasting models, as changes required manual QA verification across multiple database environments. By adopting DataOps patterns, including automated integration pipelines and isolated testing instances via Git, the engineering team reduced deployment cycles to less than 30 minutes, allowing them to instantly react to sudden maritime shipping updates.
Common Mistake
Assuming that buying a collection of modern data observability software tools automatically establishes a functional DataOps culture. Tools are useless without defining the underlying team structures, automated deployment guardrails, and code-driven testing processes required to manage them.
Key Takeaways
- DataOps applies proven software development strategies (agile development, CI/CD, IaC) directly to data ecosystem operations.
- The framework shifts data teams away from fragile, manual migrations toward reliable, automated delivery systems.
- Implementing DataOps minimizes operational bottlenecks, allowing organizations to deploy pipeline updates quickly without risking production data quality.
Relationship Between DataOps and Data Quality
┌────────────────────────────────────────────────────────┐
│ DataOps Quality Lifecycle │
├────────────────────────────────────────────────────────┤
│ Ingestion ──► Automated Testing ──► Pipeline Circuit │
│ Layer & Validation Breaker Triggered │
└───────────────────────────┬────────────────────────────┘
│ (If Test Fails)
▼
[Quarantined Target Zone]
Continuous Data Quality Management
Traditional quality control relies on post-processing audits that occur after data reaches the analytics layer. DataOps replaces this approach with continuous data quality management. Quality monitoring is embedded directly into the execution path, evaluating transactions as they pass through ingestion, transformation, and distribution layers.
Automated Data Validation
By utilizing programmable assertions, DataOps validates incoming records against exact schema boundaries and business definitions before allowing them to enter production warehouses. This prevents corrupted records from contaminating existing clean historical tables.
Pipeline Reliability
DataOps decouples data pipelines from individual engineering environments. By ensuring that pipeline definitions are programmatic, versioned, and easily reproducible, organizations achieve high pipeline reliability. If a production node fails, automated orchestration paths spin up alternative containerized clusters to resume data movement without dropping or corrupting messages.
Faster Issue Detection
When data issues arise, DataOps architectures leverage real-time observability frameworks to pinpoint the exact processing node or upstream API responsible for the anomaly. This reduces Mean Time to Detection (MTTD) from weeks to seconds, allowing engineers to resolve failures before downstream users spot them.
Cross-Team Collaboration
DataOps fosters cross-team collaboration by defining data quality metrics as executable code contracts. When software development teams modify a production microservice database schema, the changes are automatically flagged against the data engineering team’s continuous integration tests, forcing cross-functional alignment before code hits production.
In Simple Terms
Think of a traditional system like a human guard checking passports at a border control gate with a physical book of rules. DataOps is like a biometric scanning system linked to an instant cloud database; it scans thousands of travelers every second, catches invalid documentation immediately, and alerts security personnel before an unauthorized individual can enter.
Real-World Example
A fintech enterprise experienced an upstream API change where a third-party payment processor shifted transactional timestamps from EST to UTC. Because the engineering team utilized a DataOps framework with automated range and drift testing, the pipeline automatically identified the sudden three-hour divergence in data distribution patterns, stopped the automated merge into the primary ledger, and alerted the on-call analytics engineer within two minutes of the API deployment.
Common Mistake
Failing to implement automated pipeline circuit breakers. If your validation tools find severe data anomalies but allow the pipeline to keep writing corrupted data into your primary production database, you have built an expensive alerting mechanism rather than a true DataOps quality framework.
Key Takeaways
- DataOps shifts data quality testing from a post-hoc manual review to an inline, automated validation process.
- Automated circuit breakers prevent corrupted source files from polluting downstream production environments.
- The continuous monitoring model dramatically reduces the time required to detect, isolate, and resolve pipeline failures.
Common Causes of Poor Data Quality
To construct resilient data pipelines, engineers must understand and prepare for the structural, human, and system failures that degrade data accuracy.
Human Errors
Human mistakes remain a primary source of data contamination. These errors occur when application users enter inconsistent text patterns, manually override database records, or misconfigure operational fields.
- Data Entry Problems: Free-form text fields without strict UI input validation lead to unpredictable variations in critical records.
- Duplicate Records: Failing to implement strict entity resolution rules across sales, CRM, and billing systems creates multiple conflicting records for the same real-world entity.
- Inconsistent Data Formats: Inconsistent date structures, localized address strings, and changing currency codes across international business units create fractured datasets.
- Missing Values: Applications that fail to enforce database-level null constraints allow critical transactional fields to remain blank, corrupting downstream analytical calculations.
Integration Issues
When data flows across distributed enterprise landscapes, integration friction can break schema boundaries and corrupt records.
- Pipeline Failures: Mid-point network disconnects, unhandled API timeouts, and memory-exhausted container nodes cause incomplete data writes and corrupted data chunks.
- Schema Evolution Failures: Upstream application developers changing a column type from an integer to a string without coordinating with data teams can crash traditional ETL systems.
Root Cause Analysis Matrix
| Quality Challenge | Primary Root Cause | Upstream Impact | Prevention Strategy |
| Data Entry Issues | Lack of frontend validation masks and database constraints. | Corrupts analytical aggregations and creates broken categorical filters. | Enforce rigid regex formatting patterns at application entry nodes and database schemas. |
| Duplicate Records | Absence of unified master data indexing rules across platforms. | Inflates distinct customer counts, distorting customer acquisition metrics. | Implement automated entity resolution models and deterministic primary key linking. |
| Inconsistent Formats | Multi-regional systems operating without central serialization standards. | Disables sorting algorithms and breaks downstream datetime partitioning logic. | Mandate strict UTC and ISO 8601 formatting models at the ingestion layer. |
| Missing Critical Values | Weak upstream validation boundaries allowing null values in vital transactional metrics. | Skews financial dashboards and breaks strict machine learning matrix features. | Apply absolute non-null database conditions on all critical operational metrics. |
| Pipeline Failures | Network timeouts or unhandled database resource limitations. | Leads to partial batch ingestion and inconsistent operational states. | Leverage atomic transactional stages and stateful pipeline checkpointing. |
In Simple Terms
Imagine a water utility company where some residential pipes are rusting (pipeline failures), construction workers accidentally patch sewage pipes into the clean water network (integration issues), and field workers manually log water meter readings using completely different handwriting styles and abbreviations (human errors). Without standardization, the final water system becomes unusable.
Real-World Example
A global retail chain launched a seasonal loyalty campaign across thousands of storefronts. Because the point-of-sale terminal software did not enforce a standard layout for customer phone numbers, records were captured across varying formats, including 123-456-7890, +11234567890, and (123) 456 7890. When the data pipeline attempted to group these entries to analyze customer behavior, it generated millions of isolated duplicate profiles, rendering the marketing analytics dashboard useless.
Common Mistake
Assuming you can resolve structural data quality problems purely by writing increasingly complex cleaning code inside your data warehouse. If you do not patch the upstream software bugs or system integration flaws causing the issue, your data warehouse will become an expensive processing engine for dirty data.
Key Takeaways
- Human and application software errors represent the most frequent sources of data corruption in production warehouses.
- System integration points require strict, programmatic contract enforcement to survive upstream schema updates.
- Resolving data quality issues requires patching problems at the source application layer rather than relying solely on downstream transformation patches.
Core DataOps Practices That Improve Data Quality
┌────────────────────────────────────────────────────────────────┐
│ DataOps CI/CD Safety Gates │
├────────────────────────────────────────────────────────────────┤
│ Git Pull Request ──► Run Unit Tests ──► Build Ephemeral Environment │
│ │ │
│ Production Deploy ◄── Merge Code ◄── Run Data Assertions ──────┘
└────────────────────────────────────────────────────────────────┘
Automated Testing
Automated testing forms the foundation of defensive data engineering. Rather than manually inspecting tables, DataOps frameworks treat data checks as code. Every pipeline release undergoes automated test validation, testing data types, value distribution bounds, and business logic before processing live data.
Continuous Monitoring
Data environments fluctuate constantly. DataOps introduces continuous, non-intrusive monitoring agents that track metrics like table volume growth rates, processing runtimes, and write frequencies. These monitors instantly flag sudden behavioral changes without degrading pipeline throughput.
Version Control
By archiving all infrastructure code, pipeline orchestration definitions, and transformation scripts within version control systems like Git, organizations establish a clear trail of systemic modifications. If a pipeline update introduces an unexpected data calculation error, engineers can instantly roll back the production branch to the last known stable state.
CI/CD for Data Pipelines
Continuous Integration and Continuous Deployment (CI/CD) pipelines eliminate risky manual deployments. When a data engineer modifies an analytical model, the CI/CD pipeline automatically spins up an isolated, ephemeral staging environment, loads a representative production data slice, executes all structural assertions, and logs performance metrics before approving the production merge.
Automated Validation Rules
DataOps engines execute runtime validation checks during data movement. If incoming data breaks structural constraints (such as an alphabetic character arriving in a financial ledger column), the system isolates the bad data into a quarantine location while allowing healthy records to proceed.
Metadata Management
Modern architectures leverage automated metadata systems to index the state of all data physical properties. This metadata records exactly who modified a dataset, what transformations occurred, and which systems consumed the output, providing comprehensive operational visibility.
Data Lineage Tracking
Data lineage tracking generates an explicit visual map detailing the journey of data from source application logs to final executive scorecards. When a business analyst spots an anomaly on a dashboard, lineage charts allow engineers to trace the issue back through the exact sequence of transformation nodes to find the root cause.
In Simple Terms
Implementing these core DataOps practices is like giving your data team a time machine, an automated security guard, and an interactive digital blueprint. The version control system works like a time machine to undo mistakes, automated testing acts like a guard blocking bad files at the entrance, and data lineage functions as an interactive map tracking every step your data takes.
Real-World Example
An enterprise financial services provider integrated continuous data lineage tracking and CI/CD validation across its credit risk analytical pipeline. When an automated update to their customer valuation engine produced an unexpected spike in high-risk classifications, the debugging team used the interactive data lineage graph to instantly isolate the error to a misconfigured rounding function inside a specific dbt transformation step. This allowed them to fix the bug and redeploy within fifteen minutes.
Common Mistake
Failing to test data transformation logic with realistic edge-case datasets during continuous integration. Testing code only against perfect, hand-crafted mock data ensures your pipelines will fail when confronted with real-world production data anomalies.
Key Takeaways
- Treating pipeline configurations as versioned code allows engineering teams to easily roll back infrastructure changes when bugs appear.
- Continuous monitoring tracks operational metadata, isolating incoming file failures before they corrupt historical target data.
- Comprehensive data lineage maps reduce root-cause analysis times from days to minutes, maximizing engineering efficiency.
Data Quality Lifecycle in DataOps
Managing data quality requires targeted verification steps at every phase of the operational lifecycle. The diagram below illustrates how raw source records are systematically transformed into verified enterprise insights.
[Data Collection] ──► [Data Ingestion] ──► [Data Transformation] ──► [Data Storage] ──► [Data Consumption]
│ │ │ │ │
(Source Validation) (Schema Checks) (Business Assertions) (Drift Checks) (Lineage Tracking)
End-to-End Operational Lifecycle Framework
| Stage | Stage Purpose | Embedded Quality Controls | Intended Business Outcome |
| Data Collection | Captures raw interaction signals and core database state events directly at the source boundary. | Source schema verification, strict API authentication contracts, and client-side payload validation. | Minimizes the capture of malformed or corrupt transactional records before they enter the data ecosystem. |
| Data Ingestion | Moves raw records from source streams and third-party APIs into the central landing zones. | Row count validation, file formatting checks, and automated isolation of malformed payloads. | Prevents broken source files from stalling primary processing queues or corrupting storage layers. |
| Data Transformation | Cleanses, joins, and aggregates raw data into structured enterprise business models. | Primary key uniqueness assertions, referential integrity tests, and column value distribution audits. | Delivers reliable data structures that accurately map to documented business rules and logic. |
| Data Storage | Organizes and preserves analytical data models within cloud warehouses, lakes, or meshes. | Historical schema drift monitoring, access control audits, and data retention enforcement. | Maintains long-term data consistency and performance while protecting data privacy across storage. |
| Data Consumption | Distributes analytical assets directly to BI dashboards, operational applications, and ML models. | Freshness verification checks, anomaly detection alerts, and complete end-to-end lineage mapping. | Empowers business users and automated applications to make fast decisions based on trusted data. |
In Simple Terms
Think of the data quality lifecycle like a modern water treatment network. Water is validated at the reservoir (Collection), checked for chemical balances as it enters processing facilities (Ingestion), filtered and treated to meet strict safety standards (Transformation), safely preserved in clean reservoirs (Storage), and verified safe right as it flows out of a kitchen faucet (Consumption).
Real-World Example
A digital streaming platform processes billions of user viewing events every day. By enforcing row-count validations and schema checks at the Data Ingestion stage, their system automatically flags and isolates a corrupted mobile app log batch generated by an unpatched legacy Android version. This isolated cleanup prevented downstream Reporting and Analytics dashboards from reporting false drops in user engagement metrics.
Common Mistake
Focusing all testing and validation efforts exclusively on the Data Ingestion stage while ignoring the Data Transformation and Data Storage phases. Sophisticated analytical transformations can easily introduce data corruption through unintended cross-joins or incorrect null value filtering, even when working with perfectly clean incoming raw data.
Key Takeaways
- Data quality assurance must be embedded at every stage of the pipeline lifecycle rather than treated as a single checkpoint.
- Isolating corrupt data payloads into dedicated quarantine folders ensures primary orchestration tracks keep running smoothly.
- Verifying data freshness right at the consumption layer prevents business stakeholders from building tactical plans around outdated operational metrics.
Data Validation Techniques in DataOps
Automated validation protects production data environments from structural degradation. Implementing these core techniques helps ensure incoming records adhere to structural and contextual standards.
Schema Validation
Schema validation verifies that incoming data matches exactly with target database structures. This process checks that all required columns exist, column names are spelled correctly, and fields use the correct structural data types (such as FLOAT, INT, or VARCHAR).
SQL
-- Conceptual Example: Programmatic Ingestion Schema Verification Assertions
SELECT
CASE
WHEN TYPEOF(transaction_id) != 'integer' THEN 'FAIL: Schema Invalid Type'
WHEN TYPEOF(user_email) != 'text' THEN 'FAIL: Schema Invalid Type'
ELSE 'PASS: Schema Verified'
END AS schema_status
FROM raw_stage.incoming_transactions;
Range Validation
Range validation prevents unrealistic numerical data points from corrupting calculations by ensuring values fall within realistic parameters. For example, a retail transaction discount rate should never sit below 0% or cross above 100%.
Format Validation
Format validation checks that text records match specific structural patterns, typically leveraging regular expressions (Regex). Common applications include checking email addresses for standard @ domains, validating phone number structures, and ensuring postal codes match regional standards.
Code snippet
-- Standard structural evaluation regex pattern for Global Postal Code compliance checking
^[0-9]{5}(?:-[0-9]{4})?$
Null Checks
Null checks scan non-nullable columns to verify that mandatory operational fields contain valid data. This ensures critical attributes like customer_id or total_amount are never missing from incoming transactional records.
Duplicate Detection
Duplicate detection identifies and flags redundant data sub-missions. This step verifies that a unique event identifier only appears once within a target table, preventing artificial inflation of transactional volume metrics.
Referential Integrity Validation
Referential integrity validation ensures that relationships between separate data tables remain logically consistent. For instance, an order record containing a specific store_id will trigger an alert if that identifier does not exist within the primary master store directory table.
Business Rule Validation
Business rule validation confirms that data records match complex internal organizational policies. A common example is verifying that a financial system transaction’s shipping_date never occurs chronologically before its corresponding order_date.
Data Validation Techniques Reference
| Technique | Validation Target | Example Scenario |
| Schema Validation | Structural and type alignment. | Verifies that incoming user_id records are strictly integers. |
| Range Validation | Numerical boundary compliance. | Confirms that operational asset purity_percentage values fall between 0.00 and 100.00. |
| Format Validation | Text pattern structures. | Evaluates text strings via Regex to ensure email fields contain valid characters. |
| Null Checks | Essential data presence. | Rejects incoming rows where a required invoice_number field arrives blank. |
| Duplicate Detection | Record uniqueness. | Scans tables to catch and remove identical copies of the same transaction. |
| Referential Integrity | Cross-table alignment. | Confirms that a transaction’s product_id matches an active item in the main catalog. |
| Business Rule Validation | Internal organizational logic. | Verifies that a vehicle’s return_timestamp always occurs after its pickup_timestamp. |
In Simple Terms
Data validation techniques are like the automated screening gates at an express train station. The gates check if your ticket is the right size (Schema), make sure you didn’t buy a negative number of tickets (Range), check that your scan code matches standard layouts (Format), ensure you actually have a ticket (Null check), and confirm the ticket hasn’t been scanned already (Duplicate detection).
Real-World Example
An international vehicle rental company uses automated Business Rule Validation across its telemetry processing pipelines. If a vehicle sensor sends a GPS payload showing a current_speed of 150 MPH while the vehicle status is marked as parked, the validation system instantly catches the logical contradiction, flags the sensor data as an anomaly, and alerts the fleet maintenance team to check for a malfunctioning telemetry module.
Common Mistake
Hardcoding rigid validation parameters directly into your core pipeline transformation scripts. When business guidelines shift, engineers must manually comb through complex transformation files to update values, creating operational bottlenecks and code management issues.
Key Takeaways
- Schema validation blocks malformed source payloads from triggering system crashes in downstream database engines.
- Combining Regex pattern matching with structured null checks ensures text fields align with enterprise reporting standards.
- Decoupling business rules from pipeline code allows organizations to update validation boundaries without refactoring infrastructure.
Data Testing in DataOps
┌────────────────────────────────────────────────────────────────┐
│ Pyramid of Data Testing Rigor │
├────────────────────────────────────────────────────────────────┤
│ [ End-to-End Testing ] │
│ [ Data Reconciliation Tests ] │
│ [ Integration & Regression Tests ] │
│ [ Unit Testing Models ] │
└────────────────────────────────────────────────────────────────┘
Data testing requires a comprehensive framework that evaluates both individual code units and entire pipeline architectures.
Unit Testing
Unit testing focuses on isolated code components, evaluating individual SQL macros, Python transformation scripts, or custom data extraction functions independently from external infrastructure.
- Objectives: Confirm specific transformation formulas produce exact mathematical outputs when given controlled mock input data.
- Benefits: Catches syntax errors, logical bugs, and calculation flaws early during local engineering development cycles.
- Scenario: Testing a custom currency conversion function to ensure it correctly returns a rounded four-decimal float when converting Euros to US Dollars.
Integration Testing
Integration testing evaluates how separate data processing steps interact with each other, testing the flow between storage nodes, transformation models, and staging areas.
- Objectives: Verify that separate processing stages pass data smoothly without causing communication timeouts or schema failures.
- Benefits: Confirms that distinct staging areas, orchestration jobs, and database views function correctly together as a unified network.
- Scenario: Verifying that a Kafka streaming topic successfully delivers payloads to an intermediate Snowflake landing variant table without losing records.
Regression Testing
Regression testing ensures that new updates, optimizations, or schema additions do not break existing downstream transformation logic or reporting models.
- Objectives: Guard historical reporting models against unexpected side effects caused by code updates.
- Benefits: Allows engineering teams to continuously deploy pipeline enhancements without risking production stability.
- Scenario: Deploying a new customer segmentation variable while running regression tests to verify that historical sales metrics remain unchanged.
Data Reconciliation Testing
Data reconciliation testing compares records across different systems to verify that data remains consistent during migrations and movements.
- Objectives: Ensure that row counts, financial balances, and core metrics match exactly between source and target databases.
- Benefits: Catches data dropping or truncation errors caused by network issues or incorrect filtering logic.
- Scenario: Validating that an overnight migration from an on-premise database to a cloud data warehouse moved every record down to the exact penny.
End-to-End Pipeline Testing
End-to-End pipeline testing evaluates the entire data journey, tracking everything from raw source extraction points to final analytical outputs.
- Objectives: Validate performance, data integrity, and operational orchestration across the complete data lifecycle.
- Benefits: Provides full confidence that the entire data delivery ecosystem is functioning smoothly and reliably.
- Scenario: Triggering a simulated user registration event and verifying its accurate appearance on executive dashboards within designated service level agreements (SLAs).
In Simple Terms
Testing is like validating a performance vehicle before a race. Unit testing checks if individual spark plugs function. Integration testing ensures the engine connects properly to the transmission. Regression testing confirms adding a new spoiler didn’t slow the car down. Reconciliation testing checks that fuel into the tank matches fuel burned, and End-to-End testing runs the car around the track to ensure everything works together perfectly.
Real-World Example
An online banking platform migrated its historical transactional archive from an old infrastructure stack to a modern cloud-native storage architecture. By leveraging automated Data Reconciliation Testing, their engineers compared row hashes and financial totals across both systems. The framework flagged a minor rounding variance affecting only 0.01% of legacy accounts, allowing the engineering team to correct the migration script before launching the new platform.
Common Mistake
Running data validation tests exclusively on scheduling intervals (e.g., every night at midnight) rather than triggering them as automated safety gates within your continuous integration deployment framework. Testing on a schedule means bugs are caught after they have already broken production systems.
Key Takeaways
- Unit tests validate individual transformation modules locally before code is pushed to production branches.
- Data reconciliation tests match source and target balances to prevent silent data loss during system migrations.
- End-to-end pipeline testing evaluates operational performance across the entire data lifecycle to ensure team SLAs are met.
Monitoring and Observability for Data Quality
Modern DataOps relies on comprehensive observability frameworks that collect and analyze system metadata to proactively flag anomalies.
┌────────────────────────┐
│ Data Pipeline Activity │
└───────────┬────────────┘
│
┌──────────────┴──────────────┐
▼ ▼
[Data Freshness Checks] [Statistical Volume Analysis]
│ │
└──────────────┬──────────────┘
▼
┌─────────────────────────────┐
│ Anomaly Engine Evaluation│
└──────────────┬──────────────┘
│ (If Out of Bounds)
▼
┌─────────────────────────────┐
│ Slack / PagerDuty Alerting │
└─────────────────────────────┘
Real-Time Monitoring
Real-time monitoring tracks active data pipelines as jobs execute. It continuously monitors streaming volumes, system memory utilization, and network queue depths to provide immediate visibility into pipeline health.
Data Freshness Monitoring
Freshness monitoring tracks the age of your data assets. It records the time elapsed since the last database write operation, raising alerts if a table falls behind its designated update schedule.
Data Drift Detection
Data drift occurs when the statistical properties of incoming data shift over time, often degrading the accuracy of downstream machine learning models. Observability tools continuously evaluate value distributions to spot these structural trends.
Anomaly Detection
Advanced DataOps platforms employ automated anomaly detection engines. By analyzing historical pipeline behavior, these engines learn expected file sizes, row counts, and arrival times, automatically flagging unexpected deviations without requiring manual thresholds.
Alerting and Notifications
When a monitor identifies a failure, routing mechanisms deliver alerts to communication channels like Slack, Microsoft Teams, or PagerDuty, ensuring the right engineering team receives actionable incident context immediately.
Incident Response
When an alert fires, teams follow an established incident response playbook. This workflow involves isolating the failing pipeline node, routing bad data to a quarantine zone, analyzing lineage to assess downstream impact, and reprocessing the data once the bug is resolved.
In Simple Terms
Monitoring and observability function like a smart home security system. Instead of walking around checking doors manually, sensors continuously track entry points (Real-time monitoring), alert you if the mail is late (Freshness), flag if a strange package arrives (Drift), learn your typical routine to spot unusual activity (Anomaly detection), and text you immediately if a window opens unexpectedly (Alerting).
Real-World Example
A global ride-sharing application tracks driver GPS signal metrics. Their DataOps observability platform detected an unexpected drop in incoming telemetry payload volumes from a specific European metropolitan area. The automated anomaly detection engine identified the variance, isolated it from global metrics, and notified the mobile infrastructure team within three minutes, tracing the issue to a bug in a newly released regional app update.
Common Mistake
Configuring uncalibrated, generic alerting rules across all data tables. Bombarding engineering teams with constant, non-critical Slack notifications leads to alert fatigue, causing engineers to overlook critical pipeline failure alerts when major systems break.
Key Takeaways
- Data freshness tracking ensures business users make tactical decisions based on current, up-to-date information.
- Machine-learning-driven anomaly detection identifies unexpected data variances without requiring teams to manually maintain thousands of hardcoded validation rules.
- Standardized incident response workflows prevent minor pipeline bugs from escalating into major system outages.
Tools Used for Data Quality in DataOps
Modern DataOps architectures leverage specialized open-source and commercial tools to automate validation, testing, and observability across enterprise data platforms.
Great Expectations
An open-source data validation framework that treats data quality profiles as code-driven assertions called “Expectations.”
- Key Features: Automated data profiling, programmatic assertions, and human-readable HTML documentation sites.
- Strengths: Highly customizable, integrates natively with Python and Spark pipelines, and provides clear visual documentation.
- Limitations: Features a steep learning curve for non-technical users and requires significant initial setup effort.
- Best Use Cases: Inline data validation within programmatic Python ingestion paths and pre-warehouse data testing.
- Learning Curve: Moderate to Advanced.
Soda
A data quality platform that combines an open-source YAML-driven evaluation syntax (Soda Core) with a cloud-based management platform (Soda Cloud).
- Key Features: Readable YAML configuration files, continuous data monitoring, and cross-team anomaly collaboration dashboards.
- Strengths: Accessible syntax makes it easy for data analysts to write quality checks; integrates smoothly with modern orchestration engines.
- Limitations: Advanced enterprise collaboration features require a paid commercial license.
- Best Use Cases: Implementing cross-functional data testing frameworks that involve both technical engineers and business analysts.
- Learning Curve: Low to Moderate.
Monte Carlo
An enterprise data observability platform that provides automated end-to-end monitoring across data warehouses, lakes, and BI tools.
- Key Features: Automated data profiling, machine-learning-driven anomaly detection, and automated data lineage mapping.
- Strengths: Requires minimal initial configuration; provides end-to-end visibility from ingestion sources down to BI dashboards.
- Limitations: Closed-source commercial software with pricing models designed primarily for enterprise budgets.
- Best Use Cases: Full-stack data observability, rapid root-cause analysis, and cross-platform lineage mapping.
- Learning Curve: Low.
Datafold
A specialized data testing platform designed to automate regression testing and track data modifications through visual diffs.
- Key Features: Visual data diffing, automated CI/CD regression testing, and value-level column replication validation.
- Strengths: Simplifies code deployment validation by showing engineers the exact row-level impact of their SQL changes before merging.
- Limitations: Focused on regression testing rather than real-time data streaming monitoring.
- Best Use Cases: Automating database migration validations and running regression tests during continuous integration workflows.
- Learning Curve: Low to Moderate.
dbt (Data Build Tool)
A data transformation framework that allows engineering teams to build, document, and test modular SQL models within cloud data warehouses.
- Key Features: Built-in schema testing, dependency management, automated documentation, and model optimization frameworks.
- Strengths: Excellent code modularization capabilities; simplifies key constraint and referential integrity testing directly in SQL.
- Limitations: Primarily restricted to data warehouse transformation operations, offering limited coverage for pre-ingestion or streaming layers.
- Best Use Cases: Managing and testing modular transformation layers within cloud data warehouses like Snowflake, BigQuery, or Databricks.
- Learning Curve: Low for SQL users.
OpenMetadata
An open-source metadata management platform that provides centralized data discovery, governance, and quality tracking.
- Key Features: Unified metadata repository, data lineage mapping, and built-in data quality profiling dashboards.
- Strengths: Provides a single interface for data discovery, clear lineage tracking, and cross-team collaboration.
- Limitations: Requires dedicated team resources to host, scale, and maintain the open-source infrastructure.
- Best Use Cases: Centralizing enterprise data governance, data cataloging, and quality tracking under a unified open platform.
- Learning Curve: Moderate.
Apache Airflow
An open-source workflow orchestration platform used to programmatically author, schedule, and monitor complex data pipelines.
- Key Features: Directed Acyclic Graph (DAG) code structures, extensible plugin ecosystems, and programmatic task retries.
- Strengths: Extremely flexible open-source framework capable of managing complex, multi-system processing dependencies.
- Limitations: Requires dedicated infrastructure management and does not include out-of-the-box data-level validation checks.
- Best Use Cases: Orchestrating complex enterprise ETL pipelines and triggering external data testing tools.
- Learning Curve: Moderate to Advanced.
Databand
An enterprise observability platform from IBM tailored for tracking data pipeline execution, performance, and operational health.
- Key Features: Pipeline runtime tracking, processing runtime alerts, and data-level metadata collection.
- Strengths: Deep integrations with orchestration tools like Airflow; simplifies tracking of runtime performance regressions.
- Limitations: Commercial enterprise platform requiring specific licensing integration configurations.
- Best Use Cases: Optimizing complex Airflow orchestrations and diagnosing pipeline performance bottlenecks.
- Learning Curve: Moderate.
Data Quality Tools Comparison Matrix
| Tool Name | Inline Validation | Automated Monitoring | Data Lineage | Ease of Use | Delivery Model | Best For |
| Great Expectations | Comprehensive | Manual Setup | No | Moderate | Open Source | Programmatic Python validation assertions. |
| Soda | Strong | Continuous | No | High | Hybrid Open Source | Multi-functional team validation checks. |
| Monte Carlo | Limited | Fully Automated | Full Stack | High | Commercial | End-to-end data lake and BI observability. |
| Datafold | Regression Only | No | Column-Level | High | Commercial | CI/CD database change regression testing. |
| dbt | Transformation | Basic | DAG Level | High | Hybrid Open Source | Warehouse transformation and testing. |
| OpenMetadata | Basic | Moderate | Enterprise | High | Open Source | Unified governance and discovery. |
| Apache Airflow | No | Runtime Only | Basic | Moderate | Open Source | Orchestrating end-to-end processing tasks. |
| Databand | No | Performance | Pipeline Level | Moderate | Commercial | Monitoring runtime orchestration metrics. |
In Simple Terms
Selecting tools is like building a restaurant kitchen team. dbt is your line chef organizing raw ingredients inside the main kitchen. Great Expectations and Soda are quality inspectors checking shipments at the loading dock. Monte Carlo is the manager monitoring the entire dining room, and Apache Airflow is the expeditor controlling the timing of every dish.
Real-World Example
An enterprise insurance provider migrated its data operations to a modern cloud data warehouse. They selected dbt to modularize and test daily SQL transformation models, integrated Soda to allow business analysts to configure custom data validation rules via YAML, and deployed Monte Carlo to provide automated observability across their business intelligence reporting layer. This combined stack cut their production data incidents by 70% within six months.
Common Mistake
Deploying a highly complex orchestration engine like Apache Airflow without embedding independent validation checkpoints between tasks. Running an orchestrator without inline data quality tests means your system will simply automate the propagation of corrupted data at scale.
Key Takeaways
- Great Expectations provides strong, code-driven validation for engineering teams working directly within programmatic ingestion paths.
- Monte Carlo delivers automated, machine-learning-driven observability across complex enterprise data landscapes with minimal manual setup.
- dbt remains the industry standard for managing, documenting, and testing transformation layers inside cloud data warehouses.
Data Governance and Data Quality
Data quality and data governance are deeply interconnected disciplines. While DataOps provides the automated tools and pipelines to validate and move data, governance provides the operational policies, definitions, and boundaries that dictate how those tools should be configured.
┌────────────────────────────────────────────────────────┐
│ Data Governance Framework │
├───────────────────────────┬────────────────────────────┤
│ Data Ownership │ Data Stewardship │
├───────────────────────────┼────────────────────────────┤
│ Compliance Controls │ Data Security Policies │
└───────────────────────────┴────────────────────────────┘
- Data Ownership: Data ownership assigns clear accountability for specific datasets to business leaders. Owners define the access controls, usage allowances, and business definitions for their domains, ensuring data assets align with organizational needs.
- Data Stewardship: Data stewards act as the operational bridge between policy and execution. They turn high-level governance guidelines into concrete validation rules, ensuring data assets remain clean, documented, and compliant.
- Data Policies: Data policies establish the mandatory rules for data handling across the enterprise. These guidelines define data retention schedules, masking standards for sensitive information, and minimum quality thresholds for production tables.
- Compliance Requirements: Modern data platforms must adhere to strict regulatory standards like GDPR, CCPA, and HIPAA. Governance frameworks ensure pipelines include automated auditing, data deletion paths, and sensitive field masking to meet these compliance needs.
- Data Security Controls: Security controls protect sensitive information from unauthorized access throughout the data lifecycle. These measures include Role-Based Access Control (RBAC), column-level encryption, and automated data masking in non-production testing environments.
In Simple Terms
Data governance is like the legislative branch of a government that writes the laws, safety codes, and structural guidelines. DataOps is the engineering and construction crew that builds the infrastructure and installs automated safety systems to enforce those laws across the city.
Real-World Example
A global financial technology company implemented an integrated governance and DataOps strategy to comply with open banking regulations. Their Data Governance committee defined clear rules around masking personally identifiable information (PII). The DataOps team then translated these rules into automated pipeline configurations, ensuring that any newly discovered customer field matching a social security number pattern was automatically encrypted at the ingestion layer before reaching analytical environments.
Common Mistake
Treating data governance as a static, document-only framework that lives in spreadsheets and slide decks. If your data governance policies are not translated into automated tests and code-driven validation rules within your data pipelines, they cannot protect your production data quality.
Key Takeaways
- Data governance provides the organizational policies and definitions that guide your automated DataOps quality checks.
- Assigning clear data ownership ensures technical engineering validations match real-world business requirements.
- Automated data masking and access controls must be integrated directly into ingestion paths to maintain compliance without slowing down delivery teams.
Role of Automation in Data Quality
Manual inspection cannot scale with modern enterprise data volumes. Automation replaces human gatekeepers with programmatic systems, driving consistency and speed across data operations.
Automated Quality Checks
Automated quality checks run inline validation rules against every batch and stream. By programmatically evaluating data structures and values as they move through the pipeline, these checks eliminate the risk of human oversight.
Automated Alerts
When an inline validation check fails or an observability engine detects an anomaly, automated alert routing systems send immediate notifications to the appropriate on-call engineering teams, providing them with critical context for rapid debugging.
[Incoming Data Batch] ──► [Automated Check Engine]
│
(If Validation Fails)
▼
[Automated Alert Routed] ──► [Slack / PagerDuty]
Automated Remediation
Advanced DataOps frameworks leverage automated remediation to handle common, predictable data errors. If an ingestion task encounters a minor formatting variance or a transient network timeout, the system can automatically rerun the task, apply standardization macros, or isolate anomalous rows into quarantine without requiring human intervention.
Continuous Quality Monitoring
Continuous monitoring provides real-time visibility into the performance, freshness, and structural health of all production data assets, ensuring pipeline issues are surfaced before they impact downstream business decisions.
Measurable Benefits of Automation
- 90% Reduction in MTTR: Automated alerts and data lineage mapping allow engineering teams to isolate and fix data incidents in minutes rather than days.
- Elimination of Operational Silos: Code-driven validation contracts establish a clear, shared standard of data quality across engineering, product, and analyst teams.
- Guaranteed SLA Compliance: Automated processing retries and circuit breakers keep critical production pipelines moving, ensuring reliable delivery of business data.
In Simple Terms
Relying on manual data checks is like having a human security guard inspect every single box on a massive shipping container ship using a clipboard. Automation is like installing high-speed X-ray scanners over the crane rails; it checks every item instantly, flags defects, routes bad items to a holding area, and keeps the shipping line moving without delays.
Real-World Example
A global enterprise software provider automated its data warehouse validation using custom dbt testing extensions. When a product analytics table failed a primary key uniqueness test during an overnight processing run, the automated framework triggered a pipeline circuit breaker, quarantined the duplicate records to a staging table, sent a high-severity alert to the on-call engineer’s PagerDuty app, and kept downstream financial reports running smoothly using the last verified stable data slice.
Common Mistake
Attempting to automate complex data cleanups without logging the remediation steps. If your automated scripts silently modify data values behind the scenes without creating clear audit trails, they can mask systemic bugs in upstream applications and complicate future data investigations.
Key Takeaways
- Automation scales data quality management across high-volume pipelines where manual inspection is impossible.
- Automated circuit breakers protect production environments by isolating corrupt data before it contaminates clean historical tables.
- Programmatic data checks provide clear, objective logs that simplify regulatory audits and support compliance tracking.
Real-World Industry Use Cases
Implementing DataOps practices addresses unique data quality and accuracy challenges across various industry sectors.
Banking and Financial Services
- Challenge: Reconciling millions of transactional ledger records spread across legacy mainframe environments and modern mobile applications while ensuring zero reporting discrepancies for compliance audits.
- Solution: Engineers deployed automated data reconciliation checks and continuous pipeline observability engines across all ledger integration paths.
- Results: Achieved a 99.999% reduction in transactional ledger reconciliation variances while shortening audit reporting cycles from weeks to hours.
- Lessons Learned: Financial pipelines require end-to-end reconciliation testing at the row-hash level to catch silent processing errors before data reaches regulatory reporting systems.
Healthcare
- Challenge: Unifying patient diagnostics, lab reports, and prescription histories from fragmented regional clinic networks while ensuring absolute data formatting accuracy for clinical teams.
- Solution: Implemented rigid schema validation, automated format checks, and centralized metadata tracking across all clinical ingestion paths.
- Results: Eliminated patient identification formatting errors across unified health networks, improving operational efficiency for clinical staff.
- Lessons Learned: Patient safety requires strict validation controls directly at the ingestion boundary to stop malformed records from reaching downstream clinical tracking systems.
E-Commerce
- Challenge: Managing real-time pricing configurations, inventory availability updates, and product descriptions across thousands of third-party marketplace vendors without displaying incorrect details to shoppers.
- Solution: Integrated automated range checking, format validation, and pipeline anomaly detection across all supplier inventory ingest arrays.
- Results: Cut online product catalog pricing anomalies by 85%, reducing abandoned shopping carts and improving customer conversion rates.
- Lessons Learned: High-volume digital storefronts need real-time data freshness monitoring alongside automated validation to protect the customer transaction experience.
Telecommunications
- Challenge: Processing billions of daily network call data records (CDRs) while maintaining accurate usage analytics to drive automated customer billing engines.
- Solution: Deployed distributed stream validation testing alongside automated data drift monitors across their network event queues.
- Results: Dropped monthly customer billing variance inquiries by 75% while protecting revenue streams from uncaptured network usage events.
- Lessons Learned: High-throughput streaming data requires lightweight, continuous inline validation checks to catch processing drops without impacting pipeline delivery speed.
Manufacturing
- Challenge: Aggregating industrial internet-of-things (IIOT) sensor streams across global assembly plants to power predictive machine maintenance algorithms.
- Solution: Implemented automated range validation, missing value remediation filters, and anomaly detection engines across all factory telemetry paths.
- Results: Prevented unplanned factory floor equipment breakdowns by delivering high-fidelity sensor data to predictive engineering models.
- Lessons Learned: Industrial sensor networks require automated missing-value remediation to preserve data continuity despite common, real-world factory wireless interference.
SaaS Companies
- Challenge: Consolidating multi-tenant application events, subscription statuses, and customer support metrics into a unified view to calculate accurate Net Revenue Retention (NRR).
- Solution: Integrated automated dbt schema testing, visual data diffing via Datafold, and end-to-end data lineage tracking within their cloud data warehouse.
- Results: Cut executive dashboard financial metrics discrepancies to zero, giving leadership a clear, trusted view of business health.
- Lessons Learned: Rapidly changing software platforms need automated regression testing in their CI/CD loops to keep application updates from breaking down business analytics.
Benefits of DataOps for Data Quality
Adopting DataOps methodologies delivers significant operational and strategic advantages, elevating data infrastructure from a source of frustration into a trusted competitive asset.
┌────────────────────────────────────────────────────────┐
│ DataOps Value Multiplication │
├───────────────────────────┬────────────────────────────┤
│ 90% Faster Detection Time │ 60% Lower Debugging Costs │
├───────────────────────────┼────────────────────────────┤
│ Maximized SLA Performance │ Unified Cross-Team Trust │
└───────────────────────────┴────────────────────────────┘
- Higher Accuracy: Automated validation checks eliminate human processing errors, ensuring production tables provide a precise reflection of real-world business activities.
- Faster Problem Detection: Continuous observability tools surface data anomalies within minutes of arrival, allowing engineers to isolate failures before they disrupt downstream business operations.
- Reduced Operational Costs: Catching data bugs early via automated CI/CD safety gates is significantly less expensive than attempting to rebuild corrupted production databases after a failure.
- Improved Analytics Reliability: Clean data pipelines deliver consistent updates, empowering analytics teams to provide dependable dashboards that business stakeholders can trust.
- Better Business Decisions: Reliable data feeds eliminate guesswork, allowing executive leadership to make strategic decisions backed by high-fidelity business intelligence.
- Enhanced Customer Trust: Delivering accurate, timely data across customer-facing portals and billing systems builds long-term brand loyalty and protects user retention.
Common Challenges in Maintaining Data Quality
Modern data architectures present unique operational challenges that can complicate data quality management if teams fail to plan ahead.
Rapid Data Growth
As enterprise data volumes scale exponentially from terabytes to petabytes, traditional validation techniques stall. High-volume data environments require distributed testing frameworks that scale alongside expanding storage architectures.
- Practical Solution: Transition from monolithic validation scripts to distributed validation tools that run checks directly within scalable cloud data lakes.
Multiple Data Sources
Modern enterprises pull data from a complex mix of internal operational databases, streaming event buses, third-party marketing APIs, and flat-file storage arrays. Each source brings its own formatting logic and structural definitions.
- Practical Solution: Deploy a unified validation layer that enforces standardized schema definitions across all ingestion paths.
Legacy Systems
Older mainframe platforms and legacy databases often lack modern API access, generate inconsistent file formats, and run without structured schema documentation, making integration difficult.
- Practical Solution: Use containerized ingestion microservices to wrap legacy outputs in modern data formats before passing them to primary ingestion queues.
Tool Fragmentation
Deploying an uncoordinated mix of isolated testing scripts, distinct monitoring alerts, and disconnected cataloging applications creates visibility gaps that hide systemic data issues.
- Practical Solution: Standardize your data quality strategy around a unified DataOps platform that integrates validation, observability, and lineage.
Lack of Ownership
When data assets lack clear business and technical owners, data quality issues are often ignored, leading to broken pipelines and finger-pointing when systems fail.
- Practical Solution: Implement a data mesh architecture that assigns clear data ownership to the specific business domains generating the assets.
Skill Gaps
Modern DataOps practices require a strong mix of data engineering skills, software development best practices (like Git and CI/CD), and data governance expertise, which can be difficult to find within traditional analytics teams.
- Practical Solution: Provide structured technical training programs through platforms like DataOpsSchool to upskill existing data teams in modern automation design pattern frameworks.
Common Mistakes Organizations Make
Avoid these common operational pitfalls when implementing data quality management strategies within your engineering teams.
- Focusing Only on Data Collection: Spending significant resources optimizing raw ingestion volume while ignoring the data validation checks needed to ensure those records are accurate.
- Prevention Strategy: Budget engineering hours equally between data extraction development and inline validation script creation.
- Ignoring Data Validation: Allowing raw data files to flow directly into primary production environments without running schema, null, or range checks.
- Prevention Strategy: Install automated pipeline circuit breakers at the entrance of your data warehouse staging layer.
- Lack of Monitoring: Running complex data transformation pipelines without continuous observability tools to track data freshness, volume changes, or drift.
- Prevention Strategy: Deploy machine-learning-driven observability tools across all production data warehouse tables.
- Poor Documentation: Maintaining critical column definitions, validation rules, and data lineage maps inside outdated spreadsheets or internal wikis.
- Prevention Strategy: Use tools like dbt to generate automated, code-linked documentation that updates with every pipeline deployment.
- Delayed Incident Response: Operating without clear on-call engineering rotations or established incident response playbooks when pipelines fail.
- Prevention Strategy: Integrate your pipeline alerting systems directly with team routing platforms like PagerDuty or Opsgenie.
- No Quality Metrics: Failing to track key performance indicators like pipeline downtime, incident volumes, and data freshness metrics.
- Prevention Strategy: Build an internal data quality KPI dashboard to track operational health and platform reliability trends over time.
Best Practices for DataOps Data Quality
Follow these core engineering recommendations to build resilient, self-healing data delivery pipelines.
┌───────────────────────────────┐
│ 1. Define Quality Standards │
└──────────────┬────────────────┘
▼
┌───────────────────────────────┐
│ 2. Implement CI/CD Testing │
└──────────────┬────────────────┘
▼
┌───────────────────────────────┐
│ 3. Monitor Pipeline Metrics │
└──────────────┬────────────────┘
▼
┌───────────────────────────────┐
│ 4. Track Full Data Lineage │
└───────────────────────────────┘
- Define Quality Standards: Collaborate across engineering, analytics, and business units to establish clear, objective data quality standards before writing pipeline code.
- Implement Automated Testing: Enforce mandatory automated tests within your continuous integration and deployment loops, validating every code change against representative mock datasets.
- Monitor Continuously: Use automated observability tools to continuously track data freshness, volume changes, and distribution patterns across your entire data landscape.
- Track Data Lineage: Maintain complete, end-to-end data lineage maps to simplify root-cause analysis and clearly understand how upstream pipeline updates affect downstream business dashboards.
- Establish Ownership: Assign clear accountability for data assets to the specific business domains that generate them, making data creators responsible for the quality of their outputs.
- Review Quality Metrics Regularly: Host monthly engineering reviews to analyze data incident trends, pipeline runtime performance, and SLA compliance logs to drive continuous system improvements.
Skills Needed to Manage Data Quality
Building and maintaining modern DataOps data quality architectures requires a well-rounded set of technical capabilities and operational disciplines.
┌────────────────────────────────────────────────────────┐
│ The DataOps Professional Skillset │
├───────────────────────────┬────────────────────────────┤
│ Advanced SQL Engineering │ Python Pipeline Automation │
├───────────────────────────┼────────────────────────────┤
│ Modern CI/CD Systems │ Data Observability Tools │
├───────────────────────────┼────────────────────────────┤
│ Cloud Storage Management │ Data Governance Frameworks │
└───────────────────────────┴────────────────────────────┘
- SQL: Mastery of advanced SQL dialect operations, window transformations, and query optimization patterns is essential for building and testing robust data warehouse models.
- Data Engineering Fundamentals: A deep understanding of distributed storage systems, partitioning strategies, file serialization formats (like Parquet and Apache Iceberg), and pipeline orchestration techniques.
- Data Governance: The ability to translate high-level business policies, privacy rules, and compliance mandates into clean, programmatic validation logic within production data paths.
- Data Testing: Practical experience writing modular unit tests, integration tests, and regression assertions using modern data testing frameworks.
- Monitoring and Observability: Skill in configuring automated monitoring alerts, tuning anomaly detection thresholds, and reading data lineage maps to accelerate troubleshooting.
- Cloud Data Platforms: Hands-on experience designing, scaling, and optimizing pipelines within cloud data platforms such as Snowflake, Google BigQuery, Amazon Redshift, and Databricks.
Recommended DataOps Learning Roadmap
[Level 1: Core Fundamentals] ──► [Level 2: Analytics & Testing] ──► [Level 3: Scale & Reliability]
- Linux/Shell Scripting - Advanced SQL Optimization - Distributed Computing (Spark)
- Python Programming - dbt Modeling Foundations - Machine Learning Observability
- Git Version Control - Data Validation (Soda/GE) - Autonomous Self-Healing Systems
Future of Data Quality in DataOps
As data operations continue to evolve, emerging automation capabilities are reshaping how enterprises ensure data quality and pipeline reliability.
- AI-Powered Data Quality: Next-generation validation systems use artificial intelligence to automatically scan incoming datasets, understand contextual nuances, and generate relevant testing frameworks without manual configuration.
- Predictive Data Validation: Advanced observability engines evaluate historical usage patterns to predict data anomalies and flag potential pipeline disruptions before they propagate down the data stack.
- Automated Root Cause Analysis: When a complex data failure occurs, automated systems can analyze code histories, execution patterns, and data lineage maps to instantly pinpoint the exact root cause of the incident.
- Self-Healing Data Pipelines: Future data orchestration engines will use automated remediation logic to automatically correct common data failures, update schemas safely, and process isolated data without requiring human intervention.
- Intelligent Data Governance: Automated governance platforms will continuously scan data ecosystems to automatically tag sensitive information, flag privacy risks, and update access policies based on data usage patterns.
Case Study Section
1. Banking Data Accuracy Transformation
- Problem: A multinational retail bank struggled with recurring reconciliation discrepancies between its frontend mobile payment applications and legacy backend database mainframes, leading to regulatory reporting delays and audit warnings.
- DataOps Strategy: The team implemented a programmatic data validation framework that ran continuous row-hash verification checks and automated schema tests on all transactional ingestion tracks.
- Tools Used: Apache Airflow, Great Expectations, PostgreSQL, Snowflake.
- Results: Reconciled over 50 million daily transactions with zero reporting variances, eliminating audit warnings and improving regulatory compliance.
- Lessons Learned: High-volume financial platforms require real-time, row-level validation checks embedded directly within the ingestion flow to catch processing discrepancies early.
2. Healthcare Data Reliability Program
- Challenge: A regional healthcare provider networks experienced critical patient data errors when consolidating health records from multiple legacy clinic management platforms, threatening clinical safety.
- DataOps Strategy: Engineers designed a centralized metadata management framework with rigid schema validation, automated format checks, and real-time alerts on all inbound health record paths.
- Tools Used: Soda Core, OpenMetadata, Apache Kafka, AWS Lambda.
- Results: Normalized formatting across unified patient records, reducing data errors and streamlining the clinical admissions workflow.
- Lessons Learned: Healthcare pipelines require strict formatting enforcement directly at the ingestion boundary to ensure patient details remain safe and consistent.
3. E-Commerce Product Data Quality Initiative
- Problem: An online global marketplace suffered frequent digital storefront errors, including incorrect pricing details and broken product descriptions, caused by messy third-party merchant data feeds.
- DataOps Strategy: The engineering team added automated range validation, Regex format checking, and pipeline circuit breakers to isolate anomalous supplier files before updates went live.
- Tools Used: dbt Cloud, Datafold, Google BigQuery, Fivetran.
- Results: Cut digital storefront pricing errors by 85%, reducing checkout issues and improving customer conversion rates.
- Lessons Learned: E-commerce architectures need automated pipeline circuit breakers to isolate corrupt merchant data feeds before it impacts the shopper experience.
4. SaaS Analytics Accuracy Improvement
- Challenge: A high-growth enterprise software provider faced recurring reporting discrepancies on its business leadership dashboards, as rapid application updates kept breaking downstream analytics models.
- DataOps Strategy: The team integrated mandatory visual data diffing and automated regression testing directly into their Github CI/CD workflows, verifying data model changes before production deployment.
- Tools Used: GitHub Actions, dbt, Datafold, Snowflake.
- Results: Reduced reporting discrepancies on executive dashboards to zero, giving leadership a clear, trusted view of performance metrics.
- Lessons Learned: Fast-moving software platforms must include automated regression testing within their development lifecycles to protect analytics models from upstream code changes.
5. Manufacturing Data Consistency Project
- Problem: An industrial automotive manufacturer suffered from incomplete predictive maintenance reporting because wireless network interference kept dropping packets from factory floor IoT sensors.
- DataOps Strategy: The data team deployed automated missing-value remediation filters and continuous anomaly monitors to handle transient data gaps across all factory stream points.
- Tools Used: Databand, Apache Airflow, Databricks, Apache Spark.
- Results: Maintained stable data delivery to predictive engineering models, allowing the team to prevent unplanned equipment breakdowns on the assembly floor.
- Lessons Learned: Industrial IoT data paths need automated missing-value logic to maintain reliable reporting across real-world factory wireless networks.
Data Quality Maturity Model
Organizations can evaluate the health of their data operations and plan their path forward using this five-level operational maturity framework.
┌────────────────────────────────────────────────────────┐
│ DataOps Maturity Progression │
├────────────────────────────────────────────────────────┤
│ Level 5: Autonomous Data Reliability │
│ Level 4: Proactive Data Quality Management │
│ Level 3: Automated Monitoring & Safety Gates │
│ Level 2: Basic Pipeline Validation │
│ Level 1: Reactive Troubleshooting │
└────────────────────────────────────────────────────────┘
Level 1 – Reactive Data Management
- Assessment Criteria: Data quality issues are caught exclusively by downstream business users. The engineering team has no automated testing or monitoring in place and relies on manual SQL queries to troubleshoot pipelines after a failure occurs.
Level 2 – Basic Validation
- Assessment Criteria: Engineers manually write basic null checks and key constraint validation rules within production database systems. However, pipelines lack centralized orchestration, and teams lack visibility into data lineage or freshness metrics.
Level 3 – Automated Monitoring
- Assessment Criteria: Basic data validation tests run automatically within scheduled orchestration loops. The data team uses automated alerting channels like Slack to track failures, but updates are still deployed without thorough regression testing.
Level 4 – Proactive Data Quality Management
- Assessment Criteria: Automated testing is fully integrated into the team’s CI/CD workflows, validating data models before code is merged. The platform uses data lineage mapping to track issues, and data owners are accountable for their datasets.
Level 5 – Autonomous Data Reliability
- Assessment Criteria: The data platform uses machine-learning-driven anomaly detection and self-healing pipelines to identify bugs, isolate corrupt files, and apply standard remediation updates automatically without requiring human intervention.
Data Quality Checklist
Use this comprehensive operational checklist to ensure your engineering pipelines align with modern DataOps quality and reliability standards.
Validation
- [ ] Schema structures are verified programmatically at the ingestion boundary.
- [ ] Essential operational metrics are protected by non-null database conditions.
- [ ] Text entries are validated using regular expressions (Regex) to ensure consistent formatting.
- [ ] Numerical metrics are evaluated against logical minimum and maximum boundaries.
Testing
- [ ] Data transformation functions undergo automated unit testing during development.
- [ ] System integration paths are validated to prevent processing timeouts or memory errors.
- [ ] Regression testing runs automatically within CI/CD pipelines before updates go live.
- [ ] Data reconciliation checks verify that record totals match exactly between source and target systems.
Monitoring
- [ ] Pipelines use continuous freshness monitors to track data update schedules.
- [ ] Volume monitoring tracks table growth rates to surface sudden, unexpected data drops.
- [ ] Observability tools evaluate data distributions to spot potential data drift issues.
- [ ] Alerting pathways route high-severity failures directly to on-call engineering tools.
Governance
- [ ] Every production dataset has an assigned business and technical owner.
- [ ] Data catalogs automatically index metadata and transformation rules.
- [ ] Automated column masking protects sensitive personal data across all environments.
- [ ] Ingestion pipelines include automated auditing trails to maintain regulatory compliance.
Documentation
- [ ] Transformation paths are documented using code-linked data catalogs.
- [ ] Data lineage maps trace assets from source systems down to business dashboards.
- [ ] On-call engineering teams have documented incident response playbooks for pipeline failures.
- [ ] Business terminology and KPI formulas are standardized across all departments.
Incident Management
- [ ] Automated circuit breakers stop corrupt files from reaching clean production tables.
- [ ] Out-of-bounds payloads are routed to isolated quarantine zones for inspection.
- [ ] Incident summaries record pipeline downtime and root causes to guide future improvements.
- [ ] Debugging teams use full-stack data lineage charts to quickly assess downstream impacts.
FAQ SECTION
- What is data quality in DataOps?
Data quality in DataOps is a continuous, automated approach to measuring and maintaining the accuracy, completeness, and reliability of data across production pipelines by treating data validation and testing as code.
- Why is data accuracy important?
Data accuracy ensures that your analytical systems provide an exact reflection of real-world business activities, giving leadership a trusted foundation for strategic decision-making.
- How does DataOps improve data quality?
DataOps improves quality by embedding automated testing, continuous observability, and strict validation checks directly into CI/CD workflows, transforming quality management from a reactive cleanup chore into a proactive engineering process.
- Which tools support data quality management?
Modern data quality architectures leverage specialized open-source and commercial tools like Great Expectations, Soda, Monte Carlo, Datafold, and dbt to automate testing and monitoring.
- What is data validation?
Data validation is the programmatic process of verifying that incoming data records match predefined structural formats, column data types, and business rules before they are committed to production storage.
- How do organizations measure data quality?
Data quality is evaluated using key operational dimensions, including accuracy, completeness, consistency, timeliness, validity, and uniqueness, which are tracked using automated monitoring tools.
- What are common data quality issues?
Common data quality issues include malformed values from manual entry errors, duplicate rows from broken integration paths, missing fields, and unannounced upstream schema updates.
- What skills are needed for DataOps?
DataOps professionals need a strong mix of advanced SQL engineering, Python pipeline development, CI/CD automation experience, cloud data platform expertise, and an understanding of data governance frameworks.
- How does monitoring help data quality?
Continuous monitoring provides real-time visibility into pipeline health, automatically alerting engineering teams to data freshness delays, unexpected volume drops, and structural anomalies before they impact business users.
- What is the future of DataOps quality management?
The future of DataOps focuses on autonomous data reliability, leveraging artificial intelligence to power automated anomaly detection, predictive validation, and self-healing pipelines that correct data issues without human intervention.
- What is a pipeline circuit breaker?
A pipeline circuit breaker is an automated safety gate that halts data processing or quarantines incoming payloads when an inline validation check fails, stopping corrupt data from polluting clean production tables.
- How does data drift impact machine learning models?
Data drift occurs when the statistical properties of incoming features shift over time, creating a mismatch with the model’s historical training data that degrades prediction accuracy.
- What is the difference between DevOps and DataOps?
While DevOps focuses on automating software development lifecycles and application deployments, DataOps applies similar automation, CI/CD, and testing principles to managing complex data pipelines and data accuracy.
- What is data lineage?
Data lineage is an interactive visual map that tracks the complete journey of data assets over time, showing every source extraction point, transformation step, and downstream consumption node.
- How often should data quality tests run?
Data quality tests should run continuously as inline validation gates with every pipeline execution, while regression tests should trigger automatically inside CI/CD workflows with every code update.
- What is regression testing in data pipelines?
Regression testing verifies that updates, performance optimizations, or schema expansions do not unintentionally break existing downstream transformation logic or historical reporting metrics.
- How do you fix duplicate records in a data warehouse?
Duplicate records are resolved by implementing strict primary key definitions, using deterministic deduplication functions within transformation models, and enforcing entity resolution rules at the ingestion layer.
- What is data governance’s role in DataOps?
Data governance provides the foundational business definitions, privacy rules, compliance mandates, and data ownership boundaries that guide your automated DataOps validation strategies.
- Can data quality automation save operational costs?
Yes, automating data quality checks reduces operational expenses by catching data bugs early within CI/CD loops, which is significantly cheaper than manually cleaning up corrupted production tables after a failure.
- How do you start implementing DataOps best practices?
Start by moving your pipeline configurations into version control systems like Git, setting up basic automated schema testing on your most critical tables, and establishing clear data ownership across your teams.
Final Summary
Maintaining reliable data requires a systematic, automated approach. Traditional manual checks can no longer keep pace with the scale and variety of modern multi-source cloud data architectures. By treating data validation, pipeline testing, and system monitoring as core engineering disciplines, DataOps transforms data quality management from a reactive debugging chore into a predictable, automated workflow.
Implementing robust techniques like schema validation, range checks, and continuous anomaly detection allows teams to protect production warehouses from incoming data corruption. Supported by modern tools like dbt, Great Expectations, and automated observability platforms, engineers can build self-healing pipelines that isolate anomalies and alert teams to issues in real time. This automated approach ensures consistent, dependable data delivery across the entire organization.