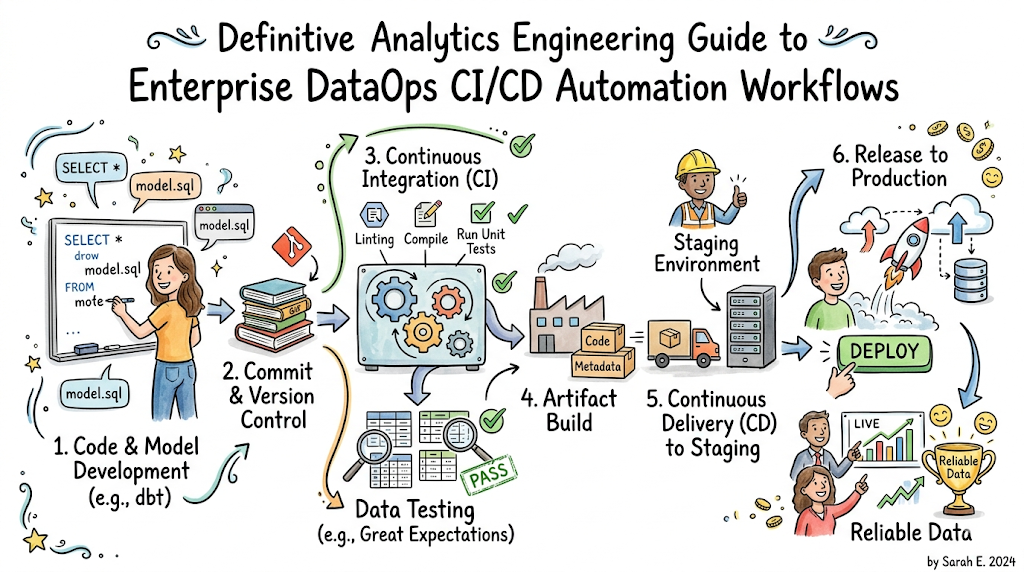
Introduction
Modern data engineering has undergone a structural paradigm shift. Gone are the days when data teams consisted of a lone analyst executing manual SQL scripts against a local database or running custom Python scripts via cron jobs on an unmonitored server. Today, organizations run highly complex, distributed data networks processing terabytes or petabytes of diverse data daily. These pipelines fuel real-time dashboards, financial reporting mechanisms, machine learning models, and executive decision-making engines.
As complexity grows, manual approaches become dangerous liability vectors. In data engineering, a tiny change can have catastrophic consequences. Imagine an analytics engineer optimizing a dbt (data build tool) transformation script to change a column’s data type from a floating-point number to an integer. Without automated safety nets, this script is pushed directly to production. To explore more comprehensive foundational frameworks and kickstart your data automation journey, check out the specialized training courses and educational resources available at DataOpsSchool.
2. Understanding DataOps
What Is DataOps?
DataOps is an agile, orchestrational methodology that unites data creators, data consumers, and operations teams. It applies the core philosophies of DevOps, Agile development, and statistical process control to the end-to-end data lifecycle.
Rather than viewing data engineering as a series of ad-hoc projects, DataOps treats the acquisition, transformation, storage, and presentation of data as a continuous, high-quality manufacturing process.
Why Automation Matters in DataOps
Data is inherently volatile. Unlike static software code, data changes unpredictably in schema, volume, and velocity. Manual validation is impossible at modern scale. Automation forms the bedrock of DataOps because it removes human error from repetitive tasks.
Automating data operations ensures that code changes are verified, data schemas are kept intact, and deployments are executed identically across development, staging, and production environments.
The Evolution: Manual Data Operations to Automated Pipelines
Historically, data movement relied on rigid, legacy ETL (Extract, Transform, Load) suites managed by specialized database administrators. Changes required manual change requests, lengthy documentation forms, and scheduled maintenance windows where systems were taken offline.
The rise of cloud data warehouses like Snowflake, BigQuery, and Databricks catalyzed the transition to ELT (Extract, Load, Transform), making agile, code-driven architectures possible. This shift necessitated moving toward automated pipelines where data environments can be spun up, validated, and torn down entirely through automated scripts.
[Legacy Manual Era] [Modern DataOps Era]
Manual SQL Scripts ───► Version-Controlled Infrastructure (IaC)
Scheduled Downtime ───► Blue/Green Continuous Deployments
Human Data Audits ───► Automated Declarative Testing (Great Expectations)
The Relationship Between DevOps and DataOps
While DataOps borrows heavily from DevOps, it is not just “DevOps for data.” DevOps focuses on aligning code development with IT infrastructure operations to manage software releases. DataOps extends this by introducing a highly complex secondary dimension: the data state.
In DevOps, compiling a clean code binary means your application is generally ready to test. In DataOps, code interacts with ever-changing third-party data inputs, dynamic database schemas, data quality anomalies, and historical states. Thus, DataOps requires distinct methodologies to test both code changes and the actual data flowing through that code.
3. Understanding Continuous Integration (CI)
Definition of Continuous Integration
Continuous Integration (CI) in DataOps is the automated practice of regularly integrating code changes from multiple developers into a single, shared version-controlled code repository (typically via Git). Every pull request triggers an automated process that builds, compiles, and tests the code to catch errors before integration.
Goals of CI in DataOps
The primary objective of CI is to isolate code or logic errors early in the development lifecycle. In DataOps, CI ensures that any modification to a transformation script, orchestration DAG (Directed Acyclic Graph), or data extraction tool does not break downstream data dependencies, violate business logic rules, or corrupt target environments.
Key Components of CI
Version Control
The fundamental prerequisite for CI. All data structures, orchestration configurations, and analytical transformation scripts must be stored as code in repositories like GitHub, GitLab, or Bitbucket.
Automated Testing
Every time code shifts, automated suites validate the syntax of SQL/Python scripts, perform unit tests on custom data functions, and run integration tests to verify that components interact correctly.
Data Validation
CI frameworks run schema validation tests to ensure that incoming changes do not violate column constraints, primary key uniqueness, nullability rules, or data type structures.
Build Automation
Compiling assets into predictable artifacts. In modern data frameworks, this includes linting SQL code, compiling dbt projects to check for circular dependencies, and building Docker images for orchestration engines.
Collaboration Workflows
CI establishes standard branch protection mechanisms. Developers work on separate feature branches and must pass all automated status checks before their work can be merged into the main development branch.
Deep Dive: Section Insights
In Simple Terms
Think of Continuous Integration like an automated editor for a collaborative textbook. If ten authors are writing different chapters simultaneously, they don’t just dump their text into the final book. Instead, an automated system checks their grammar, ensures their formatting matches the template, verifies that their page numbers don’t conflict, and checks that they aren’t using banned words—all before allowing their text into the master copy.
Real-World Example
A data engineer creates a pull request to modify an Airflow DAG that orchestrates an e-commerce ingestion pipeline. The engineer introduces a new upstream task to pull data from a marketing API.
When the pull request opens, a GitHub Actions workflow automatically runs SQLFluff to lint the code, triggers pytest to run unit tests on the API ingestion logic, and compiles the Airflow DAG to ensure there are no syntax errors or cyclic dependency loops.
Common Mistake
The Mock Data Trap: Data teams often construct CI testing processes that execute against completely static, outdated mock datasets that do not resemble production conditions. When the code passes CI and encounters real-world data with missing values or altered schemas, the pipeline immediately crashes.
Key Takeaways
- CI validates code correctness and structural schema integrity before merging.
- Version control is the absolute prerequisite for any functional CI architecture.
- Automated testing must catch breaking changes before they reach main development branches.
4. Understanding Continuous Delivery (CD)
Definition of Continuous Delivery
Continuous Delivery (CD) in DataOps is the automated practice of taking code, schemas, and infrastructure artifacts that have successfully passed the CI stage and preparing them for deployment to staging, pre-production, or production environments.
Under Continuous Delivery, every successful build is automatically deployed to a non-production testing or staging environment, with the final push to production being a controlled, low-risk decision.
Goals of CD in DataOps
The ultimate goal of CD is to ensure that deployments are repeatable, predictable, and routine events. It seeks to minimize the lead time between writing a new data transformation or reporting feature and making that live data accessible to business stakeholders, all while maintaining absolute platform stability.
Automated Deployment Workflows
CD removes manual command-line deployments. Artifacts are automatically packaged and moved across environments using deployment runners. For example, when a branch is merged, the CD pipeline automatically copies updated dbt models into a production Snowflake environment or updates an Airflow deployment hosted on Kubernetes.
Data Pipeline Release Management
Release management in DataOps involves coordinating code updates alongside data migrations. If a change requires modifying a production database table structure, the CD pipeline handles the orchestration of the schema migration script, ensuring no loss of historical target data occurs during the transition.
Deployment Validation
Once a deployment script executes, the CD engine does not simply close the session. It runs post-deployment smoke tests. These tests query the live target environment to verify that services are reachable, schemas were updated properly, and permissions are correctly configured.
Deep Dive: Section Insights
In Simple Terms
Imagine you run a automated printing press. Once the editor (CI) approves the text formatting, the printing press (CD) automatically prints a proof copy, sets up the physical paper trays, configures the ink levels, loads the distribution trucks, and drives them to the warehouse door. The system is completely ready to distribute the new edition immediately, needing nothing more than a final approval click.
Real-World Example
An analytics engineering team merges an optimized dbt model into their main repository branch. The CD tool (such as GitLab CI/CD) senses the merge event, authenticates with the production Google BigQuery data warehouse using secure service account tokens, creates a temporary shadow schema, executes the new data models, verifies data quality metrics, and seamlessly swaps the production views to point to the newly updated tables.
Common Mistake
Hardcoding Environment Variables: Hardcoding database credentials, API endpoints, or cloud bucket locations directly inside deployment scripts is a widespread anti-pattern. This often leads to development runs accidentally overwriting or deleting active production tables.
Key Takeaways
- CD automates the safe transition of validated assets across multiple isolated environments.
- Every successful merge should produce an artifact that is ready for zero-downtime production deployment.
- Post-deployment validations ensure the destination platform is healthy and operational.
5. Continuous Integration vs Continuous Delivery in DataOps
While CI and CD form an intertwined pipeline paradigm, they serve fundamentally distinct purposes and operate at different boundaries of the engineering lifecycle.
CI vs CD Comparison Manual
| Functional Category | Continuous Integration (CI) | Continuous Delivery (CD) |
| Primary Objective | Validate code correctness, logic accuracy, and structural cleanliness before merging. | Ensure safe, predictable, and repeatable code and data deployments across all environments. |
| Focus Area | Developer workflows, code compilation, syntax linting, unit testing, and schema validation. | Release orchestration, environment synchronization, schema migrations, and deployment smoke tests. |
| Automation Scope | Triggers automatically on pull requests, commits, and branch creation events. | Triggers automatically upon code merges, tag creations, or formal release approvals. |
| Testing Approach | Executes syntax linters, isolated unit tests, and structural validation against mock or staging environments. | Executes integration tests, post-deployment data quality audits, and endpoint availability checks. |
| Deployment Strategy | Deploys code to isolated ephemeral review environments or temporary shadow schemas. | Deploys validated code to long-lived staging, pre-production, and production infrastructure. |
| Primary Benefits | Isolates code regressions early, improves code hygiene, and streamlines developer collaboration. | Drastically reduces time-to-market, eliminates human deployment errors, and stabilizes environments. |
| Inherent Risks | Insufficient test coverage allows logic bugs to pass silently into the main branch. | Faulty deployment logic or wrong environment variables can corrupt live production systems. |
| Team Responsibilities | Individual data engineers, analytics engineers, and data scientists writing code changes. | DataOps engineers, platform engineers, and release managers overseeing operational stability. |
6. How CI and CD Work Together in DataOps
The End-to-End Integrated Workflow
CI and CD are not disconnected silos; they are the left and right gears of a single machine. The workflow begins when an engineer commits code. CI kicks off immediately to build and test the changes. If those tests pass, the code is merged. This merge automatically triggers the CD engine, which takes over to push those updates through staging and into production.
[Developer Workspace] ──(Commit)──► [CI Engine: Lint/Test/Validate]
│
(Passes Test)
▼
[Production Platform] ◄──(Deploy)── [CD Engine: Stage/Migrate/Swap]
Continuous Feedback Loops
A properly tuned CI/CD pipeline acts as a constant communication channel for engineering teams. If a code push fails a linting check or breaks an integration rule during the CI phase, the engine instantly alerts the developer via communication platforms like Slack or Teams. This tight feedback loop prevents broken code from turning into buried technical debt.
Automated Quality Gates
Quality gates are automated validation checkpoints built between the stages of your pipeline. For example, a CD pipeline may successfully deploy updated transformation logic to a staging database.
However, before it is permitted to push those changes to production, it must clear an automated quality gate run by a tool like Great Expectations. If data profile validations fail, the gate closes, stops the deployment, and preserves the clean production state.
Faster Release Cycles
By removing manual intervention from testing and deployment, the time required to roll out a new data feature drops from weeks to minutes. Data teams can ship small, incremental updates multiple times a day. This approach is far safer than grouping hundreds of changes into risky, massive monthly releases.
Improved Collaboration Across Multi-Disciplinary Teams
CI/CD creates a clear contract between data engineers, analytics professionals, and data scientists. Because the rules of acceptance are codified into automated tests, subjective code review debates are replaced by objective green checkmarks. This clear structure gives teams the confidence to collaborate inside a shared codebase without worrying about stepping on each other’s toes.
7. CI/CD Pipeline Architecture for DataOps
Building a reliable DataOps pipeline requires breaking the architecture down into modular, functional layers. Each layer has a specific job to do as code and data move through the system.
┌─────────────────────────────────────────────────────────────┐
│ 1. Source Control Layer (Git / Branching Strategy) │
└──────────────┬──────────────────────────────────────────────┘
▼
┌─────────────────────────────────────────────────────────────┐
│ 2. Build & Validation Layer (Linting / SQL Compile / Docker)│
└──────────────┬──────────────────────────────────────────────┘
▼
┌─────────────────────────────────────────────────────────────┐
│ 3. Testing Layer (Unit Tests / Schema Checks / Mock Runs) │
└──────────────┬──────────────────────────────────────────────┘
▼
┌─────────────────────────────────────────────────────────────┐
│ 4. Deployment Layer (Blue-Green / Environments / Blueprints)│
└──────────────┬──────────────────────────────────────────────┘
▼
┌─────────────────────────────────────────────────────────────┐
│ 5. Monitoring & Feedback Layer (Alerts / Observability) │
└─────────────────────────────────────────────────────────────┘
1. Source Control Layer
This layer handles the management of code state across the team. It uses Git workflows (like GitHub Flow or Trunk-Based Development) to establish a clear branching strategy. Engineers write features in isolated branches (feature/add-revenue-metric) and use pull requests to propose changes to the master branch.
2. Build and Validation Layer
The entry point of the automated pipeline. This layer runs syntax checkers (linters) to enforce formatting standards, compiles declarative models (like dbt or Terraform configurations) to spot circular dependency flaws, and builds isolated software execution environments (such as Docker containers).
3. Testing Layer
The core safety mechanism of the pipeline. It is split into two validation stages:
- Code Validation: Runs unit tests via frameworks like pytest to check the math and logic of custom transformation functions.
- Data Validation: Connects to isolated databases or temporary data clones to run schema structure audits, null-value checks, and business logic validations.
4. Deployment Layer
This layer manages the physical rollout of approved code into live environments. It uses Infrastructure as Code (IaC) tools like Terraform to safely modify target infrastructure, and handles blue/green deployment strategies (such as deploying to a shadow schema before swapping aliases) to achieve zero-downtime releases.
5. Monitoring and Observability Layer
Once code goes live, this layer tracks its health in production. It uses logging libraries, data observability frameworks, and system performance monitors to keep tabs on pipeline execution times, compute costs, error rates, and fresh data delivery metrics.
6. Feedback Layer
The communication hub of the pipeline. It hooks into messaging applications (Slack, PagerDuty, or Microsoft Teams) to provide real-time updates on pipeline failures, deployment successes, or data quality warnings, ensuring the right engineer can jump on issues immediately.
8. Key Benefits of CI in DataOps
- Early Error Detection: Finding a typo or logic flaw while code sits in a pull request is simple and costs very little. Catching that same bug after it has corrupted production tables requires hours of expensive cleanup.
- Improved Code Quality: Automated linting and mandatory code testing establish clear formatting rules. This prevents sloppy code from slipping in, keeping the entire codebase readable and maintainable over time.
- Better Team Collaboration: Since the CI pipeline handles routine code testing and verification automatically, human code reviews can focus on what matters most: architecture, design patterns, and business logic.
- Faster Development Cycles: Engineers can confidently write and commit code changes without fear of accidentally breaking downstream dependencies, which speeds up overall development velocity.
- Reduced Integration Problems: Merging small code changes multiple times a day keeps branches from drifting too far apart, eliminating painful merge conflicts down the road.
9. Key Benefits of CD in DataOps
- Faster Deployments: Automated deployment paths cut delivery times down from days to minutes. This allows data teams to ship value to business stakeholders quickly and efficiently.
- Reduced Manual Errors: Eliminating manual copy-pasting of SQL code or command-line scripts removes human error from the deployment process, making releases highly predictable.
- Consistent Releases across Environments: CD ensures that development, staging, and production environments are identical, preventing the classic “it worked on my machine” problem.
- Improved System Reliability: With robust rollbacks, blue/green deployments, and post-deployment validation steps, updates can be rolled out with minimal risk of production downtime.
- Greater Business Agility: Business leaders can pivot strategies quickly when they know their data platform can safely implement, test, and deliver new analytics features in real time.
10. Essential CI/CD Tools for DataOps
Choosing the right toolchain is key to building a highly reliable, automated data platform. Let’s break down the core technologies used across modern DataOps pipelines.
Version Control Tools
- Git: The open-source standard for tracking code changes. It acts as the foundational ledger for all pipeline code, data models, and infrastructure blueprints.
- GitHub / GitLab / Bitbucket: Cloud hosting platforms built around Git. They provide the core web-based workspaces for code storage, team code reviews, pull request workflows, and identity management.
CI Platforms (Automation Runners)
- GitHub Actions: A highly popular automation runner built right into GitHub. It uses simple YAML configurations to easily trigger test workflows based on code commits or pull requests.
- GitLab CI/CD: A mature, built-in automation platform with native support for complex pipeline stages, secure environment variables, and integrated container registries.
- Jenkins: An open-source automation server known for its massive plugin ecosystem. While highly customizable, it requires regular manual infrastructure management and tuning.
- Azure DevOps: A comprehensive enterprise suite that pairs nicely with Microsoft Azure cloud environments, offering robust release management and code integration tools.
Data Testing and Validation Tools
- Great Expectations: An open-source Python framework used to profile, test, and document data. It acts as a safety gate by checking data properties against a declared set of rules (expectations).
- Soda: A lightweight data quality platform that uses simple, human-readable configuration files to scan data structures and alert teams to quality anomalies.
- dbt Tests: Built-in testing tools within the dbt ecosystem. They provide a simple way to run uniqueness, nullability, and referential integrity tests against data models directly during execution.
- Deequ: An open-source tool built on top of Apache Spark by Amazon. It is designed to scale, making it a great option for profiling and testing massive multi-terabyte datasets.
Orchestration Engines
- Apache Airflow: The industry-standard tool for orchestration, using Python code to define workflows as Directed Acyclic Graphs (DAGs). It features a deep plugin ecosystem, but requires dedicated infrastructure management.
- Prefect: A modern orchestrator built to handle dynamic, real-time workflows easily. It minimizes boilerplate code and offers excellent support for cloud-native data patterns.
- Dagster: An asset-centric orchestrator designed specifically for DataOps workflows. It focuses on tracking data assets and data lineage rather than just scheduling tasks, making pipeline testing highly natural.
CI/CD Tools Matrix
| Tool Name | Tool Category | Primary Technical Strength | Ideal DataOps Target Use Case | Learning Curve |
| GitHub Actions | CI/CD Engine | Native integration with GitHub repositories; simple YAML setups. | Cloud-native, lightweight data pipeline testing and automated delivery. | Beginner to Intermediate |
| Jenkins | CI/CD Engine | Deep customization options through a massive plugin ecosystem. | Legacy, on-premise, or highly complex multi-cloud enterprise frameworks. | Advanced |
| Great Expectations | Data Testing | Rich, declarative rules engine that doubles as automated documentation. | Strict pre-production and production data quality validation gates. | Intermediate |
| dbt Tests | Data Testing | Simple inline SQL assertions built directly into transformation workflows. | Analytics engineering models running inside modern cloud data warehouses. | Beginner |
| Apache Airflow | Orchestration | Python-native workflow creation with excellent scheduling flexibility. | Complex, multi-system enterprise ETL/ELT pipeline automation. | Intermediate to Advanced |
| Dagster | Orchestration | Native tracking of data assets, dependencies, and execution states. | Modern DataOps setups focused on software-defined data assets. | Intermediate |
11. Real-World DataOps CI/CD Use Cases
Data Warehouse Deployments
Challenge
An enterprise retail company needs to roll out structural modifications to its core revenue tables inside Snowflake. These tables are constantly queried by hundreds of looker dashboards and business users, making any downtime or schema breakage unacceptable.
CI/CD Implementation
The data team sets up a CI/CD pipeline using GitHub Actions and Terraform. When an engineer proposes a schema change via a pull request, the CI step spins up a temporary, isolated Snowflake schema clone using Snowflake’s Zero-Copy Clone feature.
The pipeline applies the proposed schema alterations to this clone and runs a suite of data quality tests. Once approved and merged, the CD pipeline applies the changes to production, running data validation tests before swapping production views to point to the new tables.
[Main Production Schema] ──(Zero-Copy Clone)──► [Temporary Testing Schema]
│
(Run CI Validation)
│
(Passes)
▼
[Main Production Schema] ◄────(Zero-Copy Swap)──── [Updated Testing Schema]
Business Outcome
The company achieves zero-downtime database updates, completely eliminating breaking schema changes and ensuring business analysts have continuous, uninterrupted access to clean reporting data.
ETL/ELT Pipeline Updates
Challenge
A financial tech company needs to regularly update the data logic inside its daily ingestion pipelines without disrupting upstream API sources or corrupting downstream historical data lakes.
CI/CD Implementation
The team sets up an automated pipeline using GitLab CI/CD and Apache Airflow. Pipeline code updates are packaged into Docker images and deployed to an isolated staging Airflow environment.
The staging system processes a small slice of real-world production data, and a suite of Great Expectations tests runs to verify that output values fall within expected bounds. Once validated, the CD runner updates the production Airflow instance with the new Docker image container.
Business Outcome
The pipeline update lifecycle is fully automated, reducing deployment times from days to minutes while preventing corrupted financial metrics from ever hitting production systems.
Analytics Engineering Workflows
Challenge
A rapidly growing data team is experiencing frequent merge conflicts and broken models within their massive, shared dbt core analytics repository.
CI/CD Implementation
The team introduces dbt Cloud integrated directly with GitHub. Every pull request triggers an automated sub-production run (dbt build) inside a unique, temporary schema context.
The pipeline compiles the SQL code, checks for circular model dependencies, runs data freshness evaluations, and executes custom data quality checks on the output metrics before allowing the code to be merged.
Business Outcome
Data engineers can collaborate within a shared repository safely, catching model breakages during the pull request stage and ensuring downstream BI dashboards remain completely stable.
Machine Learning Data Pipelines
Challenge
A healthcare data group needs to roll out updates to the feature engineering pipelines that feed predictive patient-admission machine learning models, where data drift can severely degrade model accuracy.
CI/CD Implementation
The team builds a pipeline using GitHub Actions, MLflow, and Prefect. When feature transformations are updated, the CI layer trains a shadow model on incoming data, evaluates performance metrics against the current production model, and checks for data feature drift.
If the new pipeline matches or beats production performance, the CD layer registers the new model artifact and safely updates the production inference pipeline endpoints.
Business Outcome
The team automates machine learning deployment safely, keeping model predictions accurate while eliminating the risk of deploying broken feature code to production.
Regulatory Reporting Systems
Challenge
A banking enterprise must ensure that its regulatory compliance and risk reporting pipelines strictly adhere to data governance mandates, with clear auditable records for every pipeline adjustment.
CI/CD Implementation
The enterprise builds a compliant pipeline using Azure DevOps and automated data lineage tracking. Any changes to compliance calculations require approvals from senior data architects within the code repository.
When code is integrated, the CI/CD pipeline automatically generates data lineage diagrams, logs code hashes to immutable audit trails, and runs automated compliance checks against mock data before allowing production deployments.
Business Outcome
The bank guarantees complete compliance audit logs for regulators, entirely removing manual errors from reporting pipelines while keeping their system fully auditable.
12. Common Challenges in DataOps CI/CD
Managing Data Dependencies
Data pipelines are highly interconnected networks of dependencies. Changing an upstream table structure can easily break dozens of downstream models, dashboards, and machine learning models.
- The Solution: Use orchestration and build tools that support native data lineage mapping (like dbt or Dagster). These tools allow your CI pipeline to trace dependencies and automatically test all affected downstream models before allowing a change to merge.
Testing Large Datasets
Running full pipeline compilation and data validation steps against multi-terabyte production data warehouses during every single CI run is slow, highly expensive, and completely impractical.
- The Solution: Build smart, representative data sampling workflows into your testing layers, or leverage modern cloud-native features like Snowflake’s Zero-Copy Cloning to test changes against real-world data shapes without paying massive storage and compute costs.
Environment Consistency
When development, staging, and production environments drift out of sync, code that passed all tests in development will frequently fail the moment it hits production systems.
- The Solution: Define your entire data stack using Infrastructure as Code (IaC) tools like Terraform. This allows you to manage environment configurations through code repositories, ensuring your development and production environments remain perfectly identical.
Schema Evolution
Upstream source applications frequently alter their database tracking schemas, add columns, or adjust data types without giving downstream data engineering teams any warning.
- The Solution: Implement flexible, programmatic schema parsing patterns (such as semi-structured JSON landing tables) paired with automated schema validation gates like Great Expectations at the very edge of your ingestion pipelines.
Governance and Compliance Requirements
Regulated industries need strict controls over data access, data residency, and privacy rules, making it difficult to automate workflows without risking compliance violations.
- The Solution: Build automated compliance validations into your CI/CD pipelines. Ensure data masking rules, anonymization scripts, and access controls are automatically verified as part of the standard deployment process.
Security and Isolation
Automated deployment tools need high-level access privileges to modify production data platforms, turning your CI/CD runners into prime targets for security risks.
- The Solution: Follow the principle of least privilege. Use temporary, role-based access tokens (like AWS IAM roles or Azure Service Principals) with scoped permissions, and secure your environment secrets within trusted vaults like GitHub Secrets or HashiCorp Vault.
13. Common Mistakes Teams Make
Confusing CI with CD
The Consequence: Teams often build robust testing automation (CI) but still rely on manual copy-pasting of code or ad-hoc scripts to deploy changes to production (CD), creating a dangerous operational bottleneck.
The Solution: Clearly separate the two phases within your automation design. Use CI to validate code correctness, and build explicit, separate CD workflows to handle environment rollouts.
Skipping Automated Tests
The Consequence: Skipping tests to speed up a deployment saves a few minutes upfront, but inevitably leads to silent data corruption and broken production dashboards down the line.
The Solution: Enforce strict repository protection rules that block any code from being merged into production branches unless it passes every single automated test check.
Poor Version Control Practices
The Consequence: Treating your main code branch like an unmonitored scratchpad leads to regular code overwrites, broken pipelines, and an inability to track changes over time.
The Solution: Adopt standard trunk-based development or GitHub Flow branching models. Require peer reviews and automated status checks on every pull request before code integration.
Ignoring Data Quality Validation
The Consequence: Pipelines may execute without throwing any code or syntax errors, but end up writing empty tables or completely garbled metrics to consumer-facing dashboards.
The Solution: Treat data quality testing as a mandatory part of pipeline design. Integrate validation tools like Great Expectations or Soda directly into your deployment workflows.
Overcomplicated Pipelines
The Consequence: Building an overly complex pipeline with dozens of nested scripts and fragile tool chains makes the system incredibly difficult to debug and maintain.
The Solution: Keep your pipeline architecture modular, clean, and simple. Use native tool integrations and focus your automation on the high-value areas that matter most.
14. Best Practices for DataOps CI/CD
Shift-Left Testing
The core principle of shift-left testing is simple: move your validation and testing steps as early in the development lifecycle as possible. Catch bugs while the code is still in a local branch, rather than waiting for it to reach production.
Automate Data Validation at Every Layer
Do not just test your code logic; continuously validate the data moving through it. Build data quality checks into your ingestion points, transformation steps, and final delivery tables to catch anomalies before they reach end users.
Maintain Infrastructure as Code (IaC)
Treat your entire data infrastructure—warehouses, databases, compute clusters, and storage buckets—as software code. Use tools like Terraform to version and deploy your infrastructure, making your environments completely reproducible.
Use Version Control for Everything
Every single piece of your data platform should live inside a version-controlled Git repository. This includes SQL transformations, Python scripts, orchestration DAGs, database schemas, deployment pipelines, and infrastructure definitions.
Monitor Deployments Continuously
Your job is not done once code is successfully deployed. Build continuous data observability and monitoring tools into your production environments to track pipeline health, data freshness, and performance metrics in real time.
Implement Automatic Rollback Strategies
Always prepare for things to go wrong. Design your deployment pipelines with built-in rollback paths—such as point-in-time database snapshots or blue/green view swaps—allowing you to quickly revert to a stable state if a production issue pops up.
15. Measuring CI/CD Success in DataOps
To ensure your automated pipelines are actually delivering value, you need a clear framework to measure performance and track operational improvements over time.
The DataOps KPI Tracking Framework
Speed Metrics Stability Metrics
┌───────────────────┐ ┌───────────────────┐
│ Deployment │ │ Pipeline │
│ Frequency │ │ Success Rate │
├───────────────────┤ ├───────────────────┤
│ Delivery │ │ Change │
│ Lead Time │ │ Failure Rate │
└─────────┬─────────┘ └─────────┬─────────┘
│ │
└────────────────┬────────────────┘
▼
┌──────────────────────┐
│ Mean Time to │
│ Recovery (MTTR) │
└──────────────────────┘
1. Deployment Frequency
- What It Measures: How often your team successfully rolls out code and pipeline updates to production systems.
- Why It Matters: High deployment frequency shows that your team can deliver updates in small, manageable, and low-risk increments.
2. Pipeline Success Rate
- What It Measures: The percentage of automated CI/CD pipeline runs that complete successfully without throwing errors.
- Why It Matters: A consistently low success rate points to fragile testing workflows, flaky test code, or unstable environments that need tuning.
3. Change Failure Rate
- What It Measures: The percentage of production deployments that result in pipeline downtime, data quality failures, or require manual rollbacks.
- Why It Measures: This metric tracks the actual quality of your releases, proving whether your pre-production testing suites are catching bugs effectively.
4. Mean Time to Recovery (MTTR)
- What It Measures: The average time it takes your team to restore normal service when a production pipeline fails or encounters an issue.
- Why It Matters: A low MTTR proves that your team has great pipeline monitoring, clear logging, and fast, automated rollback paths.
5. Data Quality Metrics
- What It Measures: The volume of null anomalies, schema violations, and data logic breaks that slip past your testing layers into production.
- Why It Matters: This directly tracks the health of your data assets, showing how well your automated quality gates are protecting downstream consumers.
6. Delivery Lead Time
- What It Measures: The total time it takes for a new data feature to go from initial code commit all the way to a live production release.
- Why It Matters: Shorter lead times mean your data team can stay highly responsive, delivering value to the business quickly and efficiently.
16. Career Skills for DataOps CI/CD Professionals
As organizations continue to scale their data infrastructure, the demand for data professionals who know how to build reliable, automated pipelines is growing rapidly. Here is a practical learning roadmap to help you build the core skills needed for a career in DataOps.
The Professional DataOps Learning Path
[Level 1: Core Foundation] ──► [Level 2: Testing & Automation] ──► [Level 3: Cloud & Observability]
SQL Mastery & Python Logic Git Workflows & CI Runners IaC Blueprints & Live Monitoring
dbt Analytics Engineering Data Validation Frameworks Cloud Warehouse Implementations
Level 1: Core Data Engineering Foundations
- SQL Mastery: Write clean, performance-optimized queries and understand advanced warehouse concepts like partitioning, clustering, and window functions.
- Python Programming: Master core software design patterns, error handling, and data structures using libraries like pandas, PySpark, and pytest.
- Analytics Engineering: Learn how to structure clean, modular transformation workflows using modern frameworks like dbt.
Level 2: Pipeline Automation & Testing
- Advanced Git Workflows: Master branching strategies, merge conflict resolution, and code repository management using platforms like GitHub or GitLab.
- CI/CD Configuration: Learn how to build automated validation and deployment pipelines using tools like GitHub Actions or GitLab CI/CD.
- Data Quality Testing: Master automated data profiling and validation tools like Great Expectations, Soda, or dbt tests.
Level 3: Enterprise Cloud Platforms & Observability
- Cloud Data Architectures: Build and manage scalable architectures within cloud warehouses like Snowflake, Google BigQuery, or Databricks.
- Infrastructure as Code (IaC): Learn how to define, version, and spin up entire data environments using infrastructure tools like Terraform.
- Data Observability: Implement proactive monitoring solutions to track data lineage, processing performance, and pipeline health in real time.
17. The Future of CI/CD in DataOps
The DataOps landscape is evolving rapidly. As data systems grow more complex, several key trends are shaping the future of automated pipeline management.
AI-Powered Pipeline Automation
Artificial intelligence is moving into the core of the development lifecycle. Future pipelines will leverage machine learning models to automatically analyze code additions, optimize SQL query performance, and write highly thorough unit test suites before an engineer even opens a pull request.
Intelligent Data Validation
Static validation rules are being replaced by adaptive, machine-learning-driven testing models. Instead of manually coding strict data thresholds, automated systems will continuously profile production data streams, dynamically adjusting validation rules to match changing business patterns and seasonal variations.
Self-Healing Data Pipelines
When a production pipeline fails due to an upstream schema change or network blip, future orchestration platforms won’t just alert an engineer—they will take action. Using intelligent routing and automated fallback logic, pipelines will automatically quarantine bad rows, adapt to schema shifts, and self-heal in real time.
Integrated Data Observability
Data quality monitoring is shifting from isolated post-run checks into a core part of the continuous integration lifecycle. Real-time data observability platforms will connect directly to your deployment pipelines, providing teams with complete visibility into data freshness, processing costs, and end-to-end data lineage across the entire enterprise.
Autonomous Data Operations
The long-term future points toward completely autonomous data environments. By pairing advanced infrastructure blueprints, AI-driven validation engines, and smart orchestrators, data platforms will largely configure, test, optimize, and scale themselves with minimal manual intervention from engineering teams.
Platform Engineering for Data Teams
Organizations are moving away from ad-hoc pipeline building toward internal data developer platforms. Dedicated platform engineering teams will deliver pre-configured, self-service infrastructure templates that include built-in version control, testing tools, and deployment paths, allowing data scientists and analysts to build pipelines safely and independently.
18. Case Study Section
Case Study 1: E-Commerce Analytics Pipeline
Problem
A fast-growing global e-commerce retailer was struggling with frequent production breakdowns in its marketing and attribution pipelines.
Every time the web development team modified the checkout app’s event schema, the downstream data pipelines would crash, blinding the marketing team to campaign performance and causing thousands of dollars in lost ad spend.
CI Implementation
The data engineering team integrated GitHub Actions with their repository. They added an automated schema validation layer using Great Expectations.
Now, whenever a pull request is opened, the pipeline automatically checks the event code against a master JSON schema file, catching any missing fields or changed data types during the development phase.
CD Implementation
The team introduced an automated deployment path using GitLab CI/CD and dbt Cloud. Once code passes all checks and merges into the main branch, the CD runner spins up a temporary shadow schema in their BigQuery data warehouse.
The pipeline runs the new transformation models against a fresh slice of production data, verifies the output metrics match historical bounds, and seamlessly updates the production environment.
Outcome
- Production pipeline crashes dropped by over 92%.
- The data engineering team completely eliminated manual deployment tasks, allowing them to shift their focus toward building new analytics features.
Lessons Learned
Catching schema changes at the very edge of your ingestion pipeline is critical. Automating your pre-deployment validations prevents upstream changes from turning into downstream business disruptions.
Case Study 2: Banking Data Warehouse Deployment
Problem
A major retail banking institution was hitting a wall with its data warehouse deployments. Due to strict financial regulations and manual database audits, rolling out even minor pipeline updates required weeks of paperwork, lengthy compliance meetings, and risky weekend maintenance windows.
CI Implementation
The bank moved its code infrastructure into Azure DevOps and implemented strict trunk-based branching rules. They wrote automated unit testing workflows using pytest to validate custom financial calculation logic, paired with automated SQL linter checks to enforce enterprise coding standards across the team.
CD Implementation
The bank used Terraform to manage its environments and set up a blue/green deployment strategy within Azure Synapse. The automated CD pipeline builds and deploys updates to an isolated, identical “green” environment.
The system runs thorough financial balancing checks to ensure data accuracy down to the penny. Once validated, a secure network switch routes user traffic to the updated environment with zero system downtime.
Outcome
- Deployment cycles dropped from 6 weeks to under 30 minutes.
- The platform achieved a 100% success rate on compliance audits thanks to the clear, immutable history logs generated by the automated pipeline.
Lessons Learned
Strict compliance and rapid delivery can easily coexist. By embedding regulatory checks and validation rules right into your automated pipelines, you can satisfy security auditors while accelerating development velocity.
Case Study 3: Healthcare Data Integration Platform
Problem
A regional healthcare provider needed to combine patient intake records from multiple distributed hospital systems into a centralized analytics platform.
Because the incoming data formats varied wildly, manual data processing led to frequent data quality errors, delayed patient reporting, and regular compliance risks.
CI Implementation
The provider built an automated CI pipeline using GitLab CI/CD and Python. Every incoming data transformation script is automatically tested against synthetic, HIPAA-compliant patient mock datasets.
The pipeline runs strict validation checks to verify that data masking, hashing, and encryption routines work perfectly before code can be merged.
CD Implementation
The team deployed Apache Airflow running on Kubernetes clusters managed through code. When updates are merged, the CD pipeline packages the new code into secure containers and runs a rolling deployment across the cluster.
The orchestrator processes a test batch of records, checks the data formatting, and automatically rolls back to the previous stable state if any errors or data anomalies are spotted.
Outcome
- Patient data processing times dropped by 78%, giving care teams access to near-real-time reporting insights.
- The automation completely eliminated human data exposure risks, ensuring the platform remains fully compliant with privacy laws.
Lessons Learned
When dealing with highly sensitive data, security cannot be an afterthought. Automating your encryption and data masking validations within your CI/CD pipelines is the best way to guarantee continuous compliance and protect data privacy.
19. FAQ Section
- What is Continuous Integration in DataOps?
Continuous Integration (CI) in DataOps is the automated practice of regularly merging code changes into a central repository, where automated workflows build, lint, and test the updates to catch errors before integration.
2. What is Continuous Delivery in DataOps?
Continuous Delivery (CD) in DataOps is the automated practice of taking code and infrastructure updates that have passed the CI stage and safely deploying them to staging or production environments reliably and predictably.
3. What is the core difference between CI and CD?
CI focuses on code correctness, testing, and structural validation during the early development phase, while CD focuses on the safe, automated rollout of those validated changes into live production environments.
4. Why is CI/CD important for modern data teams?
CI/CD removes manual intervention from the deployment process, eliminating human errors, improving data quality, and allowing teams to deliver analytical insights to business stakeholders quickly and safely.
5. What tools are commonly used to build DataOps pipelines?
Modern DataOps pipelines use version control tools like GitHub, automation runners like GitHub Actions or GitLab CI/CD, testing tools like Great Expectations, and orchestrators like Apache Airflow or Dagster.
6. How do automated tests improve overall data quality?
Automated tests continuously audit your data structures and logic, checking for missing values, uniqueness, and schema drift, which prevents corrupted data from slipping into consumer-facing dashboards.
7. Can small data teams benefit from implementing CI/CD?
Absolutely. While setting up automation requires a small investment upfront, it saves small teams hours of manual debugging and production firefighting down the road, giving them more time to build new features.
8. What key metrics should our team track to measure success?
Teams should monitor core delivery and stability metrics, including Deployment Frequency, Pipeline Success Rate, Change Failure Rate, Mean Time to Recovery (MTTR), and Data Quality metrics.
9. How does CI/CD reduce deployment risk within a data warehouse?
By using automated testing environments, temporary schema clones, and post-deployment validation checks, teams can thoroughly verify updates before swapping them into production with zero system downtime.
10. What role does version control play within DataOps?
Version control acts as the single source of truth for your entire data platform. Storing your transformations, DAGs, and infrastructure as code makes your data systems fully trackable, auditable, and reproducible.
11. What is shift-left testing within data engineering?
Shift-left testing means moving your validation and testing steps as early in the development process as possible, allowing engineers to catch and fix bugs before code ever reaches main development branches.
12. How do you handle large production datasets during testing?
Instead of running tests against whole production databases, teams use smart data sampling strategies or leverage cloud features like zero-copy cloning to test changes against real-world data shapes cheaply and efficiently.
13. What is Infrastructure as Code (IaC) in DataOps?
Infrastructure as Code is the practice of defining your data infrastructure using configuration code (like Terraform). This allows you to deploy and manage identical, reproducible environments automatically.
14. How do you manage database schema changes within a CD pipeline?
CD pipelines use automated database migration scripts and deployment strategies (like blue/green view swaps) to apply structural updates safely without risking data loss or platform downtime.
15. How does DataOps differ from traditional software DevOps?
While DevOps focuses on managing application code and infrastructure states, DataOps introduces a complex secondary dimension: continuously managing and validating ever-changing data states, schemas, and qualities.
Final Summary
Building a modern, reliable data platform requires treating your data pipelines with the same engineering discipline used in software development. Continuous Integration (CI) guarantees that your code changes are thoroughly tested, structurally sound, and free of logic flaws before they touch your core repository branches. Continuous Delivery (CD) builds on this foundation, automating your deployment paths to ensure updates move smoothly, predictably, and safely across environments all the way to production.