Introduction
In modern data engineering, building a data pipeline is only half the battle. The real challenge lies in ensuring that the data flowing through these pipelines is accurate, complete, and delivered on time. When bad data slips into a production environment, it breaks dashboards, compromises machine learning models, and leads to costly business decisions based on faulty insights. As data ecosystems grow in scale and complexity, manual validation becomes a massive bottleneck. Data teams can no longer afford to write one-off SQL queries to spot-check millions of rows of data. This operational bottleneck is exactly why data engineering has adopted DevOps principles, creating the discipline known as DataOps. At the heart of any successful DataOps strategy is Automation Testing in DataOps. By embedding automated checks directly into data workflows, organizations can catch anomalies, schema changes, and logic errors before they impact downstream users. To help data teams navigate this shift, educational platforms like DataOpsSchool.com provide structured learning paths to master these critical engineering skills.
What Is Automation Testing in DataOps?
Featured Snippet Definition:
Automation Testing in DataOps is the practice of programmatically validating data quality, schema integrity, transformation logic, and pipeline performance at every stage of the data lifecycle without human intervention.
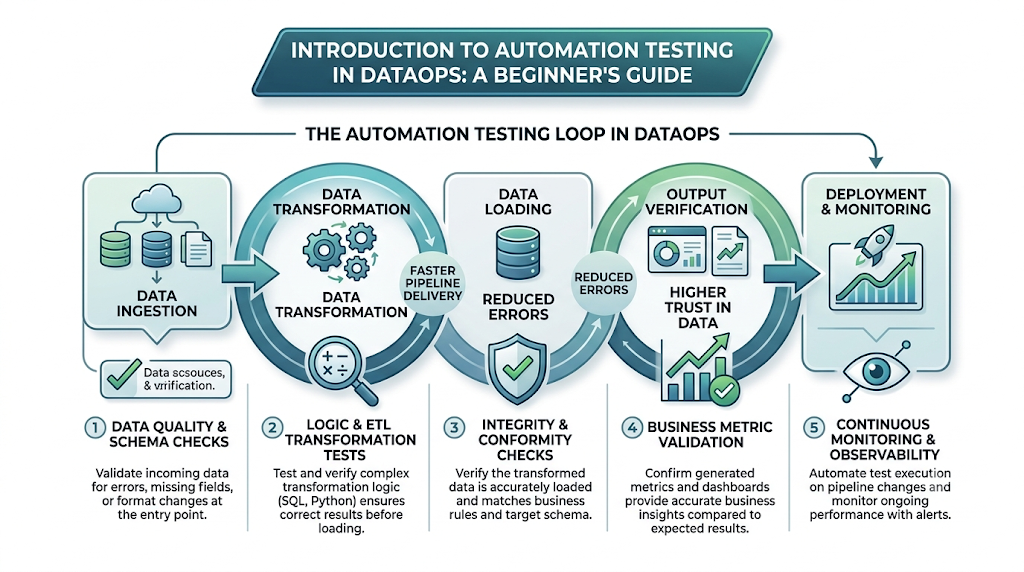
Unlike traditional software testing—which focuses on compiled code behavior—automated data testing evaluates both the code that processes the data and the data running through it. It treats data pipelines as manufacturing lines, placing digital “sensors” or test gates at ingestion, transformation, and delivery points.
[Data Sources] ──> (Test Gate 1) ──> [Ingestion] ──> (Test Gate 2) ──> [Transformation] ──> (Test Gate 3) ──> [BI / Analytics]
In modern data environments, data is highly dynamic. A third-party API might change its date format overnight, or an upstream database migration might drop a critical column. DataOps automation testing acts as an automated safety net, ensuring that any deviation from expected data states triggers an alert or halts the pipeline immediately.
Understanding the Role of Testing in DataOps
To appreciate automated data testing, it helps to examine its specific roles within a healthy data ecosystem:
Data Quality Validation
Automated tests continuously audit the health of your datasets. They check for null values in primary keys, verify that numeric values fall within logical ranges, and ensure string fields match required patterns (such as email structures or country codes).
Pipeline Reliability
Data pipelines are complex networks of storage layers, compute engines, and orchestrators. Testing ensures that infrastructure components interact correctly, data latencies remain low, and jobs complete successfully within their scheduled windows.
Continuous Delivery of Data
Just as software developers use CI/CD pipelines to ship code multiple times a day, analytics engineers use a DataOps testing framework to deploy new data models rapidly. Automated tests run on pull requests, ensuring new SQL transformations do not accidentally break existing reporting tables.
Operational Efficiency
Manual testing drains engineering resources. Automating routine checks frees data engineers from tedious debugging tasks, allowing them to focus on building new features, optimizing storage, and scaling infrastructure.
Risk Reduction
Faulty data can lead to compliance violations, incorrect financial reporting, and flawed customer interactions. Automated testing minimizes these risks by acting as a strict quality governance layer.
Why Automation Testing Is Essential in Modern DataOps
The shift from manual data auditing to automated pipeline validation is driven by five critical business and technical needs:
Faster Data Validation
Modern enterprises ingest terabytes of streaming and batch data daily. Automated data quality testing can evaluate millions of records in seconds, processing validations concurrently with ingestion tasks.
Reduced Human Errors
Manual spot-checking is inherently flawed. An engineer might forget to check for duplicate records or miss a subtle drift in data distribution. Code-driven tests run identically every single time, eliminating human oversight.
Improved Data Consistency
When data testing is automated across dev, staging, and production environments, data structures remain uniform. This consistency prevents situations where a data model works perfectly in a local environment but fails in production.
Continuous Monitoring
Data quality is not a one-time event. Continuous testing in DataOps ensures that pipelines are monitored 24/7. If anomalous data enters the system at 3:00 AM, automated systems detect it, isolate the bad data, and alert the on-call engineer.
Better Business Trust
When business stakeholders frequently encounter broken dashboards, they lose confidence in the data team. Regular, automated verification ensures that the data driving executive decisions is dependable, fostering a data-driven corporate culture.
Types of Automation Testing in DataOps
A comprehensive testing strategy employs several distinct test categories, each targeting a specific vulnerability in the pipeline:
- Data Quality Testing: Evaluates the internal validity of the data records. This includes checking for completeness (no missing values), uniqueness (no duplicate IDs), and conformity to business rules.
- ETL Testing Automation: Focuses on the transformation logic. It extracts sample data, runs it through transformation scripts (like dbt or Spark jobs), and verifies that the loaded output matches expected mathematical or structural results.
- Schema Validation Testing: Monitors the structure of data tables. It flags instances where upstream systems add new columns, alter data types (e.g., converting an integer to a string), or delete fields completely.
- Data Reconciliation Testing: Compares source data against target data after migrations or complex pipeline runs to ensure that row counts, sums, and balances match perfectly across systems.
- Performance Testing: Measures pipeline execution speeds, resource utilization (CPU/Memory), and data throughput to identify bottlenecks before they delay business reporting.
- Regression Testing: Runs a suite of historical test cases against updated pipeline code to ensure that optimization updates or bug fixes did not introduce new, unexpected errors.
How Automation Testing Works in a DataOps Pipeline
Implementing automated tests requires placing validation checkpoints across the entire lifecycle of a data pipeline. Let us look at how this functions at each stage:
[Ingestion Stage] ──> Test: Check API response schema & row counts
│
[Transformation Stage] ──> Test: Verify join logic, check for unexpected nulls
│
[Output Stage] ──> Test: Confirm business metrics match historical ranges
│
[Continuous Observability] ──> Monitor: Track pipeline execution times & volume drift
Data Ingestion Validation
The moment data arrives from an external source (such as a third-party CRM or an application database), an automated check triggers.
- Example: A retail pipeline imports a daily CSV file containing sales transactions. The automated test verifies that the file size is greater than zero, the date column contains today’s date, and the column delimiters are correct before allowing the file to load into the raw landing zone of the data lake.
Transformation Testing
As data moves from raw storage to clean, modeled tables, transformation engines apply business logic.
- Example: A SQL script aggregates hourly sales into daily totals. The test framework creates a small, mock dataset, runs the SQL script against it, and asserts that a customer with two distinct $50 purchases yields a single row with a total of $100.
Data Integrity Checks
This stage evaluates relationships between different tables and datasets within the data warehouse.
- Example: When loading an orders table, an automated check verifies that every
customer_idin the orders table exists inside the primarycustomersdimension table, preventing orphaned records.
Output Verification
Before data is exposed to production Business Intelligence (BI) dashboards, final checks ensure the data looks reasonable.
- Example: An automated test compares today’s total revenue against a moving average of the last 30 days. If today’s revenue is 90% lower or 500% higher than normal, the test fails, indicating a potential upstream processing issue.
Continuous Monitoring
Once data sits in production tables, background processes continually scan for data drift or latency problems.
- Example: An automated monitoring system checks a streaming dashboard table every 5 minutes to verify that the maximum timestamp of the data is less than 10 minutes old, ensuring the data stream has not stalled.
Core Components of a DataOps Testing Framework
To build an institutional grade testing architecture, your framework must include five foundational components:
- Test Cases: The concrete assertions written by engineers (e.g.,
expect_column_values_to_not_be_null("user_id")). These represent the rules that your data must follow. - Validation Rules: Declarative logic patterns or thresholds that separate acceptable data variations from outright failures. This includes setting tolerances, such as allowing up to 1% of a non-critical column to contain null values before failing a build.
- Monitoring Systems: The engine that runs the tests. This component integrates with orchestrators (like Apache Airflow or Prefect) to execute test suites automatically on fixed schedules or event triggers.
- Reporting Mechanisms: Centralized dashboards or logs that compile test results over time. This gives data leadership a clear view of overall data health trends across the organization.
- Automated Alerts: Communication integrations that route test failures to the right people instantly. This typically means pushing error logs to communication channels like Slack or Microsoft Teams, or opening high-priority tickets in incident management platforms like PagerDuty or Jira.
Popular Tools Used for Automation Testing in DataOps
The DataOps market features a variety of open-source libraries and enterprise platforms designed to automate data validation. Choosing the right tool depends on your underlying stack and technical maturity.
| Tool Category | Primary Purpose | Key Benefit | Typical Usage |
| Data Quality Platforms | Python-based assertion testing | Broad library of pre-built data quality tests | Great Expectations, Soda Core |
| In-Pipeline Validation | Testing SQL models during transformation | Compiles testing and documentation together | dbt (data build tool) tests |
| Data Observability | ML-driven anomaly detection | Catches unexpected bugs without manual test writing | Monte Carlo, Acceldata |
| CI/CD & Orchestration | Automating test execution workflows | Ensures tests run on every code change or pipeline step | GitHub Actions, Apache Airflow |
Benefits of Automation Testing in DataOps
Investing time into building automated testing yields measurable long-term engineering and operational returns:
Improved Data Reliability
By weeding out anomalies early, the data entering production data warehouses stays clean. Business users can trust that their metrics will not radically change due to hidden pipeline calculation bugs.
Faster Issue Detection
Instead of waiting for an executive to spot a broken chart, automated alerts flag errors within minutes of data ingestion. This drastically minimizes the blast radius of bad data.
Reduced Operational Costs
Debugging data issues retroactively is incredibly expensive. Finding an error three weeks after it occurred requires rebuilding historical tables and correcting old reports. Catching it at ingestion costs almost nothing.
Enhanced Scalability
As an enterprise adds dozens of new data sources, manual QA teams cannot scale effectively. Automated testing frameworks handle growing data volumes and new data sources seamlessly without requiring a proportional increase in headcount.
Better Compliance and Governance
For regulated industries like finance and healthcare, maintaining proof of data integrity is legally required. Automated test logs serve as immutable audit trails proving that data transformations comply with internal governance policies.
Common Challenges in Automation Testing
Transitioning to an automated framework is not without friction. Understanding common pitfalls allows teams to build more resilient testing systems.
Complex Data Sources
- The Challenge: Data arrives in various shapes—structured SQL tables, semi-structured JSON strings, uncompressed log files, and streaming event buses. Writing custom validation logic for every format is difficult.
- The Solution: Standardize your ingestion layer. Land all data into a raw data lake format first, then apply unified schema and structural validations using flexible abstraction engines like Apache Spark or Great Expectations.
Frequent Schema Changes
- The Challenge: Upstream application developers frequently update database schemas, changing column names or data types without warning the data team, which causes downstream tests to fail.
- The Solution: Implement a schema registry or establish data contracts between application developers and data engineering teams. Treat schema changes as breaking API modifications that must be communicated beforehand.
Large Data Volumes
- The Challenge: Running heavy validation queries over multi-terabyte tables slows down pipelines and drives up compute costs in cloud warehouses like Snowflake or BigQuery.
- The Solution: Avoid scanning entire tables for every test. Run validations incrementally on incoming data batches using delta tracking, or use statistical sampling methods to check data health without reading every single row.
Integration Difficulties
- The Challenge: Coupling data quality tools with disparate legacy orchestration engines, transformation frameworks, and reporting portals can be tricky.
- The Solution: Choose open-source tools with robust APIs and native plugins for popular orchestrators. Ensure your testing framework can be driven programmatically via a Command Line Interface (CLI).
Maintaining Test Coverage
- The Challenge: As data environments expand, engineers sometimes forget to write tests for new tables, creating gaps in data quality coverage.
- The Solution: Integrate test creation into your definition of done. Use frameworks like dbt where basic testing configs (like uniqueness and null checks) are specified in the same YAML files used to build data models.
Best Practices for Implementing Automation Testing
To get the most out of your DataOps testing initiatives, follow these core principles:
- Test Early and Continuously: Shift your testing as far left as possible. Do not wait until data reaches your presentation layer to check its quality. Validate it at the ingestion step, after every major join, and right before final delivery.
- Automate Repetitive Validations: Do not write custom code for basic assertions. Standardize core validations like null checks, string patterns, string lengths, and range constraints across your organization using reusable macros or functions.
- Monitor Data Quality Metrics: Track metrics such as the percentage of successful test runs, test execution durations, and historical failure frequencies to optimize your pipeline schedules.
- Maintain Reusable Test Libraries: Centralize test logic. If you write a custom function to validate specific regional tax identifiers, package it so that multiple business units can reference the exact same logic.
- Integrate Testing into CI/CD Workflows: Never allow an engineer to merge a code change into a production data pipeline without running regression tests against a staging environment first.
Real-World Use Cases
Automated testing looks different depending on the business context. Let us look at five common industry scenarios:
Financial Data Pipelines
A retail bank aggregates transaction records across global branches. Automated data reconciliation testing ensures that the sum of all debits matches the sum of all credits at the end of each hourly batch run. Any discrepancy halts the ledger compilation pipeline instantly to prevent incorrect account balances.
E-Commerce Analytics
An online retail platform tracks real-time clickstream data to recommend products. Automated schema validation testing monitors the web event payload. If an app update modifies the structure of the “add-to-cart” event token, the system catches the mismatch immediately, routing the raw payloads to a dead-letter queue for isolation without breaking the downstream recommendation engines.
Healthcare Reporting Systems
A hospital network aggregates patient metrics for regulatory dashboards. Because patient privacy and data accuracy are paramount, strict data quality testing checks ensure that critical identifiers like birth dates and medical codes contain no null values and fall within valid medical classification standards.
Customer Data Platforms
A marketing team consolidates customer interactions from email, web, and mobile channels. Data integrity checks run continuously to verify that newly matched customer profiles map correctly to a single master identity record, preventing duplicate messaging or fragmented customer insights.
Enterprise Business Intelligence
A multinational enterprise runs an executive dashboard tracking global supply chain efficiency. Output verification tests confirm that inventory quantities match up with physical warehouse limitations, preventing broken formulas or extreme anomalies from displaying during strategic board meetings.
Automation Testing vs. Manual Testing in DataOps
While manual spot-checking has a small role during initial ad-hoc exploratory analysis, it cannot sustain enterprise operations.
| Feature | Automation Testing | Manual Testing |
| Execution Speed | Extremely fast; handles millions of records per second | Slow; limited to individual SQL queries or sample batches |
| Consistency | High; follows exact code-defined logic every single run | Low; prone to human oversight and fatigue |
| Scalability | High; scales effortlessly with expanding cloud infrastructure | Low; requires adding more engineers as data volumes grow |
| Cost over Time | High initial setup cost; very low maintenance cost per run | Low initial setup cost; high recurring cost in engineering hours |
| System Integration | Plugs directly into CI/CD workflows and orchestrators | Requires human isolation and manual intervention |
Key Metrics for Measuring Testing Success
You cannot improve what you do not measure. Monitor these operational metrics to gauge the health of your DataOps validation practices:
- Test Coverage: The percentage of production tables and columns protected by at least one automated data quality test. Aim for high coverage on core dimension and fact tables.
- Defect Detection Rate: The ratio of data anomalies caught by your automated tests versus bugs reported by end business users. A healthy framework catches the vast majority of errors internally.
- Data Accuracy: The percentage of data payloads that completely satisfy all defined business rules and validation thresholds over a given operational period.
- Pipeline Success Rate: The proportion of total pipeline runs that execute successfully from end-to-end without failing tests or crashing due to unexpected data errors.
- Mean Time to Resolution (MTTR): The average time it takes for your data engineering team to resolve a data issue once an automated alert triggers. Efficient alerting pipelines help lower MTTR significantly.
Future of Automation Testing in DataOps
As data architectures evolve, automated data testing is moving toward more autonomous, intelligent systems:
AI-Assisted Testing
Modern frameworks leverage generative AI to write test suites. By reading table documentation and schemas, AI assistants can automatically generate comprehensive test assertions, cutting down manual setup times.
Intelligent Data Validation
Instead of manually configuring static thresholds (e.g., checking if a value drops below 10), future validation engines use machine learning to establish dynamic baselines that automatically adapt to seasonal business trends or monthly volume spikes.
Self-Healing Pipelines
When an automated test catches a non-fatal schema error or missing value, self-healing architectures can automatically fix the data inline—such as applying default parameters or casting safe data types—allowing pipelines to continue processing while logging the issue for audit.
Predictive Quality Monitoring
By tracking data patterns over time, observability systems can flag anomaly risks before data completely breaks downstream pipelines, detecting subtle statistical drifts across early staging environments.
Advanced Observability
The lines between testing, tracing, and logging are blurring. Future platforms will offer unified lineage graphs showing how individual test failures ripple across upstream models all the way down to specific BI charts.
Career Opportunities
Mastering automated data testing opens doors to specialized, high-growth engineering roles within modern technology organizations:
- DataOps Engineer: Focuses on pipeline infrastructure, CI/CD integrations, orchestrators, and ensuring testing frameworks run seamlessly across all cloud environments.
- Data Quality Engineer: Specializes in writing data quality tests, defining data validation standards, and collaborating with business teams to translate corporate policies into programmatic rules.
- ETL Test Engineer: Evaluates the technical accuracy of complex data transformation scripts, specializing in building mock data environments to stress-test data pipelines.
- Analytics Engineer: Sits between data engineering and business teams, writing clean, tested SQL models using frameworks like dbt to keep production warehouses dependable.
- Data Platform Specialist: Standardizes enterprise data architectures, choosing the overarching tooling, observability frameworks, and storage patterns for scale.
Common Misconceptions About DataOps Testing
Let us clear up some frequent points of confusion for those new to DataOps validation methodologies:
Myth: Automated testing guarantees 100% error-free data.
- Reality: Automated tests only catch the bugs they are programmed to look for. If your business logic assumptions are incorrect, a pipeline can process invalid data successfully while satisfying all structural tests. Continuous refinement is always necessary.
Myth: Writing automated tests takes too much time and delays project delivery.
- Reality: While writing tests adds small upfront effort during initial development, it saves countless hours down the line. It prevents the massive delays associated with fixing broken production tables and debugging complex pipelines under pressure.
Myth: Data testing is the exact same thing as software testing.
- Reality: While they share principles (like CI/CD and unit tests), they tackle different dimensions. Software testing validates static code logic. Data testing must handle dynamic, volatile, and ever-changing states of raw data flowing through that code over time.
19. FAQ Section
- What is the difference between DataOps testing and DevOps testing?
DevOps testing checks application code behavior, software builds, and server deployments. DataOps testing focuses specifically on data pipeline states, schema compliance, ETL transformation math, and underlying data profile health. - Can I implement DataOps automation testing without using paid tools?
Yes. You can build a comprehensive enterprise testing suite entirely using open-source tools like Great Expectations, dbt Core, Soda Core, and Apache Airflow. - How often should my automated data tests run?
Tests should run whenever data changes or code updates. Run tests during code pull requests, immediately after ingestion batches, and alongside streaming pipelines at scheduled short intervals. - What happens to data that fails an automated test?
Depending on how you configure your pipeline, failing data can either halt the entire run to prevent contamination, or it can be routed to an isolated quarantine table for manual engineering review while safe records proceed forward. - Should we test every single column inside our data warehouse?
No. Testing every column creates high computational overhead and alert fatigue. Focus your test coverage on primary keys, foreign keys, financial metrics, and columns used in downstream BI dashboards. - What is a data contract, and how does it relate to automated testing?
A data contract is an agreement between data producers (like software developers) and consumers (like data teams) defining expected data structures. Automated schema testing verifies that incoming records comply with these contracts. - How do we prevent automated tests from driving up cloud computing costs?
Avoid full-table scans by testing data incrementally. Apply validations only to newly arrived rows using windowing functions or date partitions rather than querying historical data lakes. - Is dbt considered an automated testing tool?
Yes. While dbt is primarily a transformation tool, it features a native, built-in testing framework that allows engineers to write schema and custom data assertions directly within YAML configuration files. - What is alert fatigue, and how do DataOps teams avoid it?
Alert fatigue occurs when teams receive too many minor or false alerts, leading them to ignore critical notices. Avoid this by separating test failures into distinct severity tiers, like warnings for minor drift and critical alerts for pipeline failures. - Do data analysts need to know how to write automated data tests?
Yes. As data teams move toward analytics engineering, analysts frequently write business-level data tests in SQL to verify that metrics match up with corporate reporting standards.
Final Summary
Building dependable data pipelines requires shifting from reactive manual troubleshooting to proactive, code-driven validation. Automation testing in DataOps is the definitive methodology for scaling data operations, lowering cloud storage costs, and keeping downstream analytics reliable. By implementing structured data quality testing, schema validations, and continuous infrastructure monitoring, organizations can turn data pipelines into highly efficient, self-correcting systems. Start small by automating basic null and uniqueness checks on your most critical tables, and gradually build toward a robust, continuous validation framework.