Introduction
Data has become the primary infrastructure driving enterprise decision-making, product development, and machine learning models. However, managing this asset effectively requires more than just extracting and loading files. As data volumes explode and business requirements change by the hour, organizations face a critical structural decision: stick with traditional data engineering practices or transition to a modern DataOps framework. When pipeline failures happen behind the scenes, business users lose trust in dashboards, and projects stall. Companies frequently compare these two approaches because traditional engineering methods struggle under the weight of real-time cloud data ecosystems. To bridge this gap, learning programs like DataOpsSchool.com help teams shift from rigid, fragile systems to agile, automated workflows.
Understanding DataOps
Definition
DataOps (Data Operations) is an automated, process-oriented methodology used by data teams to improve the quality and reduce the cycle time of data analytics. It brings the rigor of software engineering—specifically DevOps, continuous integration, and continuous delivery—to data pipeline development.
Core Principles
- Continuous Automation: Every manual process, from environment provisioning to testing, should be automated.
- Data Quality as Code: Quality checks run automatically at every stage of the pipeline lifecycle, rather than as an afterthought.
- Reproducibility: Code, configuration, and environment definitions are versioned together to ensure consistent results.
- Process Observability: Teams actively monitor pipeline health, processing speed, and data drift using real-time metrics.
Origins and Evolution
DataOps emerged in the mid-2010s to address a glaring issue: data pipelines were constantly breaking, and fixing them took weeks. While software engineers had solved deployment friction using DevOps, data teams were still building pipelines manually, leading to data silos, dropped tables, and missing reports.
Relationship with Agile and DevOps
DataOps is not an entirely new philosophy; it is a specialized evolution. It combines three distinct frameworks to create agile data management:
[Agile Development] + [DevOps Engineering] + [Statistical Process Control] = DataOps
Agile keeps development iterative and focused on user feedback. DevOps introduces automated testing and continuous deployment ($CI/CD$). Statistical Process Control ($SPC$) monitors data flowing through the pipeline, ensuring that quality remains high even when the source data changes.
Business Value
For businesses, DataOps translates directly to speed and reliability. It shortens the time it takes to turn a raw data source into a production-ready dashboard from months to hours. By catching errors before they reach downstream reports, it restores executive confidence in analytics.
Understanding Traditional Data Engineering
Definition
Traditional data engineering focuses on the design, construction, and maintenance of data architectures, specifically data warehouses and Extract, Transform, Load ($ETL$) systems. It is primarily concerned with data movement, structural transformations, and storage design.
Historical Approach
Historically, data engineering relied heavily on centralized, on-premises databases and scheduled nightly batch jobs. Pipelines were built using visual GUI-based ETL tools or long, complex SQL scripts that ran sequentially over several hours.
Typical Workflows
A standard workflow follows a linear path: a business analyst submits a data requirement, a data architect designs the schema, and a data engineer writes the ETL code to pull data from a transactional database into a data warehouse.
[Business Requirement] ➔ [Schema Design] ➔ [Manual ETL Code] ➔ [Nightly Batch Run] ➔ [Static Report]
Strengths and Limitations
- Strengths: Highly reliable for predictable, slow-moving structures like quarterly financial reports. It operates well within closed environments with well-defined source schemas.
- Limitations: Highly fragile when exposed to modern, volatile data sources (like SaaS APIs or web clickstreams). It lacks automated verification, leading to silent failures where corrupted data populates production tables unnoticed.
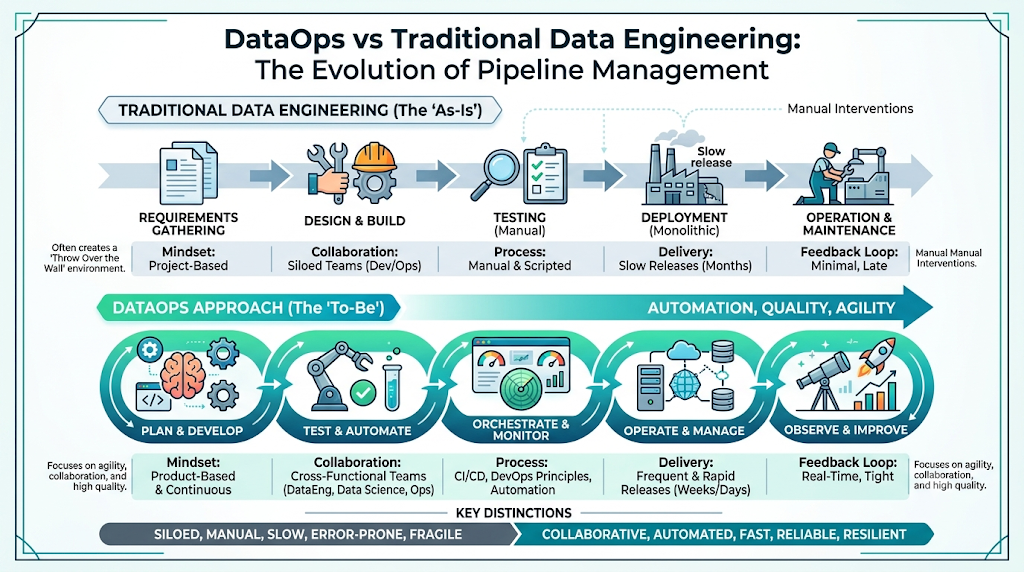
DataOps vs Traditional Data Engineering: Quick Overview
High-Level Comparison
The primary difference is that traditional data engineering focuses on building the artifact (the pipeline or table), whereas DataOps focuses on building and running the manufacturing process that generates the artifact safely, reliably, and repeatedly.
Core Philosophy Differences
Traditional data engineering treats data infrastructure as a custom construction project; each pipeline is built brick-by-brick. DataOps treats data infrastructure as a factory assembly line, where automated quality gates monitor every step of the process.
Summary Comparison Table
| Feature / Dimension | Traditional Data Engineering | DataOps Methodology |
| Primary Focus | Pipeline design, database construction | Pipeline automation, cycle time reduction |
| Testing | Manual or end-of-funnel verification | Continuous, automated testing at every layer |
| Deployment | Scheduled release windows, manual pushes | Automated $CI/CD$ pipelines, Git-driven |
| Quality Control | Reactive (fixing after user reports an error) | Proactive (alerts trigger before data enters warehouse) |
| Collaboration | Isolated, siloed data engineering teams | Cross-functional (Engineers, Analysts, Ops) |
| Environment Setup | Shared, static staging servers | Ephemeral, infrastructure-as-code environments |
Core Differences Between DataOps and Traditional Data Engineering
Development Approach
In traditional data engineering, development follows a linear waterfall pattern. Engineers build pipelines directly on shared development or staging servers. If two engineers modify the same stored procedure simultaneously, they overwrite each other’s work.
DataOps adopts an agile data management strategy. Development occurs in isolated, local branch environments created via code definitions. Code is checked into Git repositories, and changes are merged iteratively using pull requests.
Real-World Example: An e-commerce company updates its customer attribution model. In the traditional approach, engineers modify the production SQL script live over the weekend. In DataOps, the engineer builds a new feature branch, tests it against anonymized production data, and merges it into production via Git without service interruption.
Automation Strategy
Traditional methods rely on basic cron schedulers or orchestration engines to trigger jobs at specific times (e.g., midnight). If an upstream database fails to update on time, the downstream job runs anyway, processing stale or empty data.
DataOps prioritizes data pipeline automation. Automation goes beyond job scheduling to encompass system environment configuration, automated regressions, container scaling, and code compilation.
Real-World Example: A logistics firm tracks package delivery. Instead of a batch job waiting until 2:00 AM to pull delivery logs, an automated DataOps workflow spins up serverless compute resources the moment a log file lands in an S3 bucket, validates its structure, processes it, and shuts the infrastructure back down.
Collaboration Model
Traditional data engineering teams often function as a black-box service bureau. Business analysts drop tickets into a queue, and engineers build the requests in isolation. This separation causes communication issues regarding column meanings and metrics definitions.
DataOps breaks down these structural walls by introducing cross-functional squads. Data engineers, analytics engineers, and business stakeholders work together, sharing a common catalog and standardized semantic layers.
Real-World Example: When launching a new marketing campaign, a DataOps analytics squad includes both a marketing analyst and a data platform engineer. They collaboratively design the tracking pipeline, ensuring the business logic matches the database schema from day one.
Data Quality Management
Quality control in traditional engineering is largely reactive. Problems are discovered when an executive opens a morning dashboard and notices that sales dropped to zero because a column header format changed at the source.
DataOps applies Statistical Process Control ($SPC$) directly to data quality management. Data is continuously validated as it passes through the pipeline using automated assertions (checking for null values, schema drift, and unexpected value distributions).
[Raw Source] ➔ [Automated Schema Check] ➔ [Transform] ➔ [Row-Count Validation] ➔ [Production Warehouse]
Real-World Example: A fintech company processes thousands of loan applications. A DataOps pipeline monitors the incoming average loan amount. If the average suddenly spikes by 400% (indicating a typo or API bug), the pipeline automatically quarantines those records and alerts the team before the bad data impacts risk assessment algorithms.
Deployment Process
Deploying changes in traditional data engineering is a manual, high-stress event. Engineers copy SQL scripts into production, manually rename older tables for safety, and run scripts in a specific order, often during late-night maintenance windows.
DataOps relies on automated $CI/CD$ pipelines. When code passes local automated tests, a deployment server packages the pipeline components, verifies dependencies, and deploys them to production automatically or with a single approval click.
Real-World Example: A media streaming service deploys a new user-recommendation data model. Using a DataOps framework, the update is pushed to production at 2:00 PM on a Tuesday. The system automatically routes 10% of traffic to the new pipeline to verify stability before completing the rollout.
Monitoring and Observability
Traditional monitoring tells you if a server is running or if a cron job succeeded (returned exit code 0). It does not tell you if the data written to the database is accurate or structurally sound.
DataOps implements modern data engineering practices focused on complete data observability. It tracks data health across four key pillars: freshness, distribution, volume, and lineage.
Data Observability = Freshness Tracking + Volume Metrics + Distribution Analysis + Lineage Mapping
Real-World Example: In a healthcare analytics environment, a DataOps observability tool monitors a hospital admission pipeline. It notices that while the pipeline job completed successfully, it processed 40% fewer rows than the historical weekly average, instantly flagging an anomaly for review.
Testing Methodology
Testing in traditional setups is often performed manually on an ad-hoc basis. An engineer runs a few SELECT COUNT(*) queries after a migration to see if the totals look reasonable.
DataOps uses automated testing frameworks that run systematically during both development and production. Every code change triggers unit tests on code logic and integration tests on sample datasets.
Real-World Example: A travel booking platform writes a rule to calculate cancellation refunds. The DataOps system automatically runs a test suite containing dozens of historical edge-case scenarios against the code before it can be merged into the master repository.
Scalability Approach
Traditional systems scale vertically (adding more CPU or RAM to a centralized database server) or require complex, manual partitioning of tables when data volumes grow too large.
DataOps architectures leverage cloud-native, distributed compute engines and infrastructure-as-code ($IaC$). When data volumes spike, the platform automatically scales compute clusters horizontally across multiple nodes.
Real-World Example: During a Black Friday retail event, a DataOps platform automatically scales an underlying Snowflake or Databricks cluster up to 10x its normal capacity to handle streaming transaction volumes, then scales back down as traffic normalizes.
Governance and Compliance
Traditional data governance involves writing static Word documents that detail data policies, which are manually audited every few quarters. This approach often slows down engineering speed.
DataOps integrates compliance directly into the automated pipeline. Masking sensitive data ($PII$), managing access controls, and tracking column-level lineage are handled programmatically through code declarations.
Real-World Example: To comply with GDPR data access rules, a DataOps framework tags columns containing emails or phone numbers at the ingestion layer, ensuring they are automatically anonymized before entering downstream analytics areas.
Feedback Loops
Feedback loops in traditional engineering cycles are slow and painful. It can take several weeks for data consumers to communicate errors back to the engineering team, leading to long bug-fix cycles.
DataOps creates rapid, automated feedback loops. Software version control, error tracing tools, and automated notifications ensure that errors are logged, assigned, and resolved quickly.
Real-World Example: If a data transformation step fails in a DataOps environment, the system posts the exact compilation error, impacted tables, and code blame history directly to a dedicated developer Slack channel within seconds.
Workflow Comparison
To see these differences in action, let’s compare how a standard pipeline lifecycle operates under both paradigms when an upstream database table receives a new text column.
Traditional Data Pipeline Lifecycle
- Request: The business team asks to include a new “Customer Segment” column in their primary dashboard.
- Analysis: A data engineer reads the request and schedules a meeting to understand the source table changes.
- Manual Coding: The engineer logs onto the shared development server and rewrites the core ETL script to include the new field.
- Manual Validation: The engineer runs the script against a few rows to confirm it populates without errors.
- Scheduled Release: The script is uploaded to production during the next weekly scheduled maintenance window.
- Failure Recovery: If the script breaks production due to a missing dependency, the engineer must manually roll back the script using backup files.
DataOps Pipeline Lifecycle
- Branch Creation: The engineer opens a new Git branch directly from their terminal, auto-generating an isolated development environment.
- Code Implementation: The engineer updates the declarative pipeline files to pull the new column.
- Automated Testing: The engineer pushes the branch to Git, triggering a $CI/CD$ pipeline that runs regression tests to ensure existing transformations do not break.
- Peer Review: A senior engineer reviews the automated test results and code changes, approving the pull request.
- Automated Deployment: The code merges into the production branch, and the system deploys it to production with zero downtime.
- Continuous Monitoring: Observability tools track the new column for schema compatibility and value distribution anomalies in real time.
Benefits of DataOps
[DataOps Framework] ➔ Faster Delivery + Higher Quality + Lower Risk = High-Trust Data Culture
- Faster Delivery: Eliminating manual deployment steps cuts the time to deliver new data products down significantly.
- Improved Data Quality: Continuous automated validation catches bad data early, keeping corrupted records out of production warehouses.
- Better Collaboration: Shared version repositories and agile practices bring engineers, data scientists, and analysts into alignment.
- Reduced Operational Risk: Automated rollbacks and immutable infrastructure definitions make it easy to quickly recover from pipeline failures.
- Greater Scalability: Decoupling compute from storage using cloud architectures allows engineering teams to scale workloads without increasing administrative overhead.
Situations Where Traditional Data Engineering Still Makes Sense
While DataOps offers clear advantages for modern applications, traditional data engineering practices remain perfectly practical in certain environments:
- Small, Stable Teams: A lone data engineer managing a simple pipeline for a single database can often coordinate changes effectively without complex $CI/CD$ infrastructure.
- Legacy Mainframe Architectures: Older, on-premises systems sometimes lack the APIs, containerization support, or command-line interfaces required to build automated DataOps workflows.
- Fixed, Static Environments: If an organization’s data structures rarely change (e.g., standard monthly regulatory reporting with rigid schemas), the upfront cost of building a DataOps framework may outweigh the ongoing maintenance savings.
Real-World Use Cases
Enterprise Analytics
Large enterprise organizations rely on DataOps to coordinate analytics across multiple business divisions. Instead of relying on a single, overwhelmed data engineering team, individual business units use federated data products built on a shared platform, maintaining data security while accelerating development.
Cloud Data Platforms
Organizations migrating from on-premises data warehouses to cloud modern data stacks use DataOps to manage cloud compute expenses. Automated environment provisioning ensures development environments spin down when not in use, preventing unexpected cloud costs.
Financial Services
In banking and financial markets, DataOps tools audit data lineage continuously. When a regulatory body requests a compliance report, the organization can automatically trace every financial figure back to its raw transactional source code, ensuring clear accountability.
Healthcare Analytics
Healthcare organizations use DataOps to process real-time patient data and electronic health records safely. Automated pipeline quality gates instantly flag and mask sensitive healthcare information ($PHI$), ensuring HIPAA compliance while delivering clean datasets to research teams.
E-commerce Data Operations
High-volume online retail platforms run continuous DataOps workflows to manage clickstream analytics, pricing optimization engine pipelines, and inventory management tracking systems simultaneously without interrupting consumer-facing apps.
Business Intelligence Systems
Traditional BI architectures frequently suffer from stale dashboards. Implementing a DataOps approach ensures that underlying extraction models refresh predictably, giving executive leadership access to reliable daily operational metrics.
Common Challenges in DataOps Adoption
- Cultural Resistance: DataOps is as much about shifting mindsets as it is about software. Transitioning away from siloed work habits requires shifting developer focus toward shared ownership and automation.
- Tool Complexity: The modern data stack includes many specialized tools. Selecting, integrating, and maintaining these components can cause integration fatigue if not managed carefully by platform engineers.
- Skills Gaps: Traditional data engineers who are highly skilled in writing raw SQL or managing on-premises databases may need training to learn software engineering skills like Git workflows, Docker containerization, and $CI/CD$ pipeline construction.
- Governance Concerns: Opening data access via self-service architectures can cause concern for security and compliance teams if automated row-level access controls are not integrated early into the platform design.
- Legacy Integration Challenges: Legacy architectures often lack the programmatic access points needed for automated testing, making it difficult to establish end-to-end observability without replacing core components.
Best Practices for Implementing DataOps
If you are transitioning your team away from legacy engineering practices toward a modern DataOps framework, focus on these five core strategies:
- Adopt an Automation-First Mindset: Whenever you write a piece of code or clean a dataset manually, ask yourself how to automate it for future runs.
- Implement Continuous Testing: Start by adding simple row-count and null-value assertions to your core ingestion pipelines, then gradually build out comprehensive test suites over time.
- Prioritize Data Observability: Invest in end-to-end lineage tracing and anomaly detection systems so you can identify and resolve pipeline failures before your downstream business users notice them.
- Foster Cross-Functional Collaboration: Bring data engineers, analytics engineers, and data consumers together into collaborative product teams instead of keeping them in isolated departments.
- Create Feedback Loops: Establish clear notification channels to route pipeline alerts to code owners immediately, keeping resolution times short.
Tools Commonly Used in DataOps
Modern DataOps relies on a modular architecture of specialized components that manage distinct parts of the pipeline lifecycle:
[Ingestion: Fivetran/Airbyte] ➔ [Transformation: dbt] ➔ [Orchestration: Airflow/Prefect] ➔ [Observability: Monte Carlo]
- Data Integration and Ingestion: Tools like Fivetran, Airbyte, and Apache Kafka handle extraction and ingestion, moving data from production sources into centralized storage layers automatically.
- Transformation and Modeling: Open-source frameworks like dbt (data build tool) allow engineers to write transformations in modular SQL while managing version control and documentation automatically.
- Orchestration Platforms: Modern orchestrators like Apache Airflow, Prefect, and Dagster manage complex workflow dependencies, scheduling tasks dynamically based on event triggers rather than simple timestamps.
- Data Quality and Observability: Platforms such as Monte Carlo, Great Expectations, and Soda continuously scan data collections for schema variations, anomalies, and volume fluctuations.
- Collaboration and Version Control: Git platforms (GitHub, GitLab) serve as the single source of truth for all code, configurations, and deployment logic.
Future of DataOps and Data Engineering
AI-Driven Data Operations
Artificial intelligence is changing how pipelines are monitored. Machine learning models can analyze historical data patterns to set dynamic observability thresholds, predicting and preventing infrastructure bottlenecks before they cause downtime.
Data Observability Growth
Observability is shifting from basic error logging to deep architectural insights. Future data platforms will automatically track the cost-per-query of running data pipelines alongside data quality metrics, helping engineers optimize both performance and cloud spend.
Cloud-Native Architectures
The distinction between compute layers and engineering frameworks continues to blur. Modern serverless data platforms handle physical infrastructure scaling automatically, allowing engineers to focus entirely on code and data logic.
Self-Service Analytics
DataOps platforms will make it easier for business units to safely build their own data products. By using pre-approved, automated pipeline templates, business analysts can ingest new sources without waiting on central engineering queues.
Automation Trends
The industry is moving toward fully declarative data pipelines. Instead of writing long procedural code to explain how to move data, engineers simply describe the desired end state of the data, and the automation layer handles the underlying execution safely.
Career Opportunities
The shift toward modern data operations has created several distinct roles within engineering organizations:
- DataOps Engineer: A specialized professional focused on building infrastructure, setting up $CI/CD$ pipelines, and ensuring data team development environments remain stable and automated.
- Data Engineer: A developer responsible for building core data architectures, optimization models, robust ingestion layers, and physical database schemas.
- Analytics Engineer: A hybrid practitioner who sits between business units and core engineering, using clean, version-controlled SQL to transform raw warehouse tables into clean analytical models.
- Data Platform Engineer: An infrastructure specialist who maintains underlying engines like Snowflake, Databricks, or Kubernetes clusters to support scaled enterprise data processing.
- Data Architect: A strategic designer who maps out high-level data models, end-to-end systemic flows, security boundaries, and integration strategies across the entire enterprise ecosystem.
Common Misconceptions
DataOps Myths
A common misconception is that DataOps is simply DevOps with data files attached. While both frameworks share similar continuous integration and deployment values, DataOps faces unique challenges because it must manage code changes and fluctuating underlying data values simultaneously.
Traditional Engineering Misconceptions
Some assume traditional data engineering is completely obsolete. In reality, core data engineering skills like writing clean SQL, understanding database normalization styles, and building efficient schemas remain essential foundational pillars of any successful DataOps deployment.
Clarifying Industry Confusion
DataOps is not an out-of-the-box software tool you can buy and install overnight. It is a cultural philosophy, organizational strategy, and process methodology that combines tools, team structures, and automated workflows to build a reliable data practice.
FAQ Section
1. Is DataOps a replacement for traditional data engineering?
No, DataOps is not a replacement for data engineering. It is an operational methodology that enhances traditional practices by introducing automation, continuous integration, version control, and modern testing frameworks to make pipeline engineering faster and more reliable.
2. Can you implement DataOps without adopting cloud data platforms?
Yes, you can implement DataOps concepts on-premises using container tools like Docker and orchestration layers like Airflow. However, cloud-native storage and compute platforms make scaling workloads and managing isolated developer environments significantly easier.
3. What is the role of an Analytics Engineer in a DataOps team?
An analytics engineer writes clean, version-controlled SQL to transform raw data already loaded into data warehouses into clean, structured tables. They apply software engineering practices like testing and documentation to the modeling layer, bridging the gap between raw ingestion and business intelligence.
4. How does DataOps improve data quality compared to older validation methods?
Traditional engineering often validates data reactively after a pipeline breaks or a user reports an error. DataOps tests data continuously as it moves through the pipeline using automated assertions, catching and quarantining anomalies before they reach production tables.
5. Is dbt (data build tool) considered a DataOps tool?
Yes, dbt is a core component of many modern DataOps stacks. It allows engineers to treat transformation code as software assets, supporting version control, modular development, automated documentation generation, and integrated testing.
6. How do DevOps and DataOps differ from each other?
DevOps focuses on optimizing code deployment, infrastructure components, and release cycles for software applications. DataOps adapts these principles to handle the unique challenges of data development, managing both code changes and unexpected fluctuations in underlying data values.
7. Do small startup data teams need to implement DataOps immediately?
While startups do not need complex enterprise toolchains, adopting core DataOps habits early—such as using Git for version control, writing simple automated tests, and documenting transformations—saves significant time and technical debt as the company scales.
8. What does “Data Observability” mean in practical terms?
Data observability is the practice of continuously monitoring the operational health of your data. It goes beyond checking if a job completed to tracking metrics around data freshness, volume variations, schema drift, and end-to-end table lineage.
9. How do you handle legacy ETL tools during a transition to DataOps?
You can wrap legacy ETL workflows in modern orchestration wrappers or trigger them via programmatic APIs. Over time, core transformation logic is typically migrated out of closed GUI tools into modular, version-controlled code frameworks.
10. What is statistical process control (SPC) in the context of data pipelines?
SPC is the practice of using statistical metrics to monitor a running process. In data pipelines, it means tracking processing times, row volumes, and value distributions continuously to flag statistical anomalies before they impact downstream analytics.
Final Summary
Choosing between a traditional data engineering setup and an automated DataOps framework depends heavily on your data volatility, organization size, and delivery speed requirements. Traditional data engineering practices work fine for slow-moving, highly predictable data environments. However, for organizations scaling modern cloud analytics platforms across multiple fast-moving business units, adopting a DataOps methodology is essential to avoid constant pipeline failures. Modern data infrastructure requires an architecture that values agility, continuous automation, data observability, and collaborative ownership.