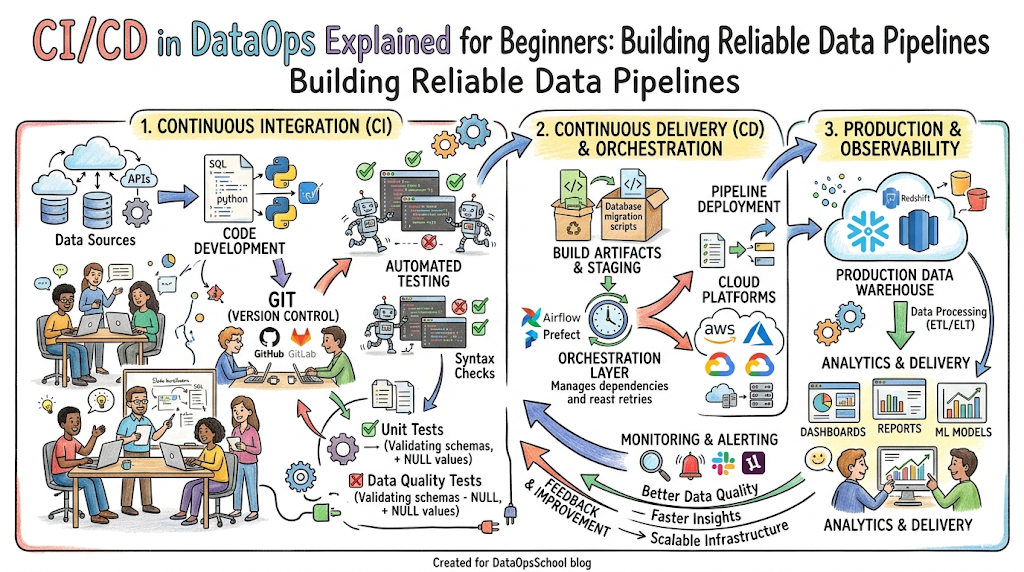
Introduction
In modern enterprise environments, data is no longer a static asset tucked away in a backup server. It is a live, rapidly flowing resource that fuels real-time dashboards, predictive algorithms, and critical corporate decisions. However, getting data from its raw origin to a clean, usable format requires a complex network of code, queries, and transformations. For years, managing this network was a slow, manual process prone to human error. A single misplaced column name or an untested SQL query could break a reporting dashboard, sending data engineers into a late-night debugging frenzy.
This is why agile analytics workflows are so important. They break down the barriers between data producers and data consumers, ensuring that infrastructure changes adapt smoothly to evolving business requirements. For anyone entering the data ecosystem, learning these automation methodologies is a major competitive advantage. Understanding how code moves automatically from a local computer to a cloud data platform opens up elite career paths. To help aspiring data professionals master these automated workflows, specialized training programs like DataOpsSchool provide comprehensive, hands-on learning paths designed to bridge the gap between traditional data engineering and modern automated operations.
What Is CI/CD in DataOps?
To truly grasp CI/CD in DataOps, it helps to break down what the individual pieces mean within a data environment.
Continuous Integration (CI) for Data Pipelines
Continuous Integration means that whenever a data engineer changes a pipeline script, updates a transformation model, or alters an orchestration workflow, those modifications are immediately integrated into a shared code repository. The moment the code is saved, automated systems take over. They spin up a temporary environment, validate the code structure, run linting checks to ensure code quality, and execute unit tests. In data pipelines, CI ensures that your SQL queries do not contain syntax errors and that your Python ingestion code can successfully connect to sample data sources before it ever touches your production databases.
Continuous Delivery (CD) for Analytics Workflows
Continuous Delivery takes those successfully integrated updates and safely prepares them for deployment to production. In an analytics workflow, this means your updated data models, newly created database tables, and modified reporting views are automatically packaged and staged. If all automated tests pass, the system can deploy the changes to the production live environment automatically, or present them as a reliable, single-click update for the operations team.
DevOps CI/CD vs. DataOps CI/CD
While DataOps borrows heavily from DevOps principles, there is a fundamental difference in what they manage:
- DevOps CI/CD focuses strictly on compiling code, running software application tests, and deploying functional software binaries or microservices. The underlying logic is stateless; code goes in, software comes out.
- DataOps CI/CD must manage code plus data and state. Data is constantly shifting, changing schemas, and growing in volume. Therefore, DataOps CI/CD must not only test if the transformation code runs, but also check if the data flowing through that code complies with quality thresholds, schema definitions, and privacy laws.
The table below highlights how these two disciplines diverge across key execution areas:
| Operational Focus | DevOps Framework | DataOps Framework |
| Primary Artifact | Software application code, binaries, containers | Transformation code, database schemas, data assets |
| Environment State | Typically stateless or strictly controlled | State-dependent, constantly dealing with historical data |
| Testing Scope | Code logic, unit testing, system integration | Code logic PLUS data quality, null checks, schema drifts |
| Success Metric | App availability, low latency, bug-free features | Data accuracy, pipeline uptime, fast time-to-insight |
The Evolution of Agile Data Operations
Historically, data teams operated in silos. Database administrators managed storage, ETL developers built isolated data movement paths, and business analysts waited at the very end of the chain. This fractured setup made rapid changes impossible. As cloud data storage costs dropped and data volumes exploded, businesses demanded real-time analytics. This demand drove the evolution of agile data operations. By unifying development teams, operations specialists, and data consumers under a shared automated framework, organizations transitioned from rigid, slow release patterns to continuous, automated updates.
Why CI/CD Matters in Modern DataOps
Implementing automated pipelines is not just a technical preference; it is a core business necessity. Here is why automated workflows are critical for modern enterprises:
Faster Pipeline Deployment
When an analytics team needs a new data source integrated to track a sudden market trend, manual creation can take weeks. With a standardized DataOps CI/CD setup, an engineer can write the new ingestion script, submit it to the repository, and let automated validation pipelines push it to production in minutes.
Automated Testing and Better Data Quality
Data quality issues ruin organizational trust. If a broken pipeline injects duplicate transactions or null values into an executive dashboard, decision-making stalls. Automated testing stages within the CI/CD pipeline catch these errors immediately. For instance, a test can automatically verify that an incoming customer ID column contains no null values before updating production tables.
Reduced Operational Errors
Human intervention is the leading cause of production downtime. Manual database migrations, copy-pasting connection string variables, and running manual terminal commands often lead to mistakes. Automation eliminates these human touchpoints, ensuring that updates follow an identical, repeatable path every time.
Continuous Analytics Delivery and Scalable Infrastructure
As businesses scale, the number of reports, machine learning models, and dashboards grows exponentially. DataOps CI/CD relies on code-driven infrastructure templates. This allows teams to spin up computing resources on demand to process massive data loads, and shut them down automatically when the tasks finish, optimizing operational budgets.
Core Concepts of DataOps CI/CD
To build an efficient automated data ecosystem, you need to understand its ten fundamental pillars.
1. Continuous Integration
Continuous Integration ensures that individual code contributions are frequently combined into a master branch. For data teams, this involves setting up automatic triggers in repositories like Git. The moment an engineer pushes a new SQL transformation script, the CI tool runs a linting check to verify style guide alignment and executes dry-run queries against a non-production database.
2. Continuous Delivery
Continuous Delivery ensures that validated code is always in a state ready to go live. It creates automated build artifacts, registers database migration scripts, and stages updates in a pre-production testing environment that mirrors production data behaviors.
3. Continuous Deployment
While Continuous Delivery prepares code for production, Continuous Deployment takes the next step by pushing those updates live to production automatically without human intervention, provided all upstream testing steps pass. This keeps pipeline states completely synchronized with the latest codebase.
4. ETL & ELT Automation
Traditional data engineering relied on scheduled, manual cron jobs to move data. Modern DataOps automates the execution of Extract, Transform, Load (ETL) or Extract, Load, Transform (ELT) routines. These processes run based on event triggers, such as the arrival of a new data file in a cloud storage bucket.
5. Pipeline Orchestration
Data pipelines consist of interdependent tasks; for example, you cannot aggregate daily sales data until the raw transaction tables are fully updated. Pipeline orchestration tools manage these dependencies by creating direct execution graphs. This guarantees tasks run in the correct order, handles errors automatically, and sends alerts if a step stalls.
6. Data Validation & Testing
Unlike standard software development, data testing happens across two distinct layers:
- Logic Testing: Checking that code calculations work as intended.
- Data Testing: Validating the actual data values flowing through the pipeline. This includes automated verification of primary keys, value distributions, column data types, and row count variances.
7. Monitoring & Observability
Data systems require deep visibility into pipeline operations. Observability platforms monitor processing durations, data volumes, memory usage, and execution failures. If an automated transformation job suddenly processes half the usual amount of data, observability systems flag this structural anomaly before downstream users notice.
8. Version Control for Data Pipelines
Every line of SQL, Python script, infrastructure template, and orchestration definition must live inside a version control system like Git. This creates an auditable history of changes, allows multiple developers to work together on the same pipeline without overwriting code, and enables instant rollbacks if a deployment causes errors.
9. Infrastructure Automation
Modern data architectures rely on Infrastructure as Code (IaC). Instead of manually configuring cloud data warehouses, databases, and firewall settings through a web portal, teams define these resources in text configuration files. The CI/CD system reads these files to create, update, or tear down environments reliably.
10. Workflow Automation
Workflow automation connects technical data processing with business operations. It coordinates tasks across separate tools, ensuring that when an enterprise data pipeline finishes updating, it automatically clears downstream application caches, refreshes reporting dashboards, and notifies data consumers.
DataOps CI/CD Architecture & Workflow
A production-grade DataOps architecture functions like an automated assembly line, moving data from raw sources to final insights securely.
End-to-End Execution Flow
- Source Data Integration: Raw information is continuously collected from external applications, transactional databases, and third-party APIs.
- Data Ingestion Systems: Ingestion microservices pick up this raw data and drop it into centralized landing zones, like cloud storage buckets or real-time streaming queues.
- Automated Transformation Pipelines: The CI/CD engine validates any pending code modifications and deploys them to the processing layer. The orchestration engine then runs these scripts, converting disorganized data into structured, highly optimized tables.
- CI/CD Orchestration Layer: This central controller supervises code integration, runs data quality checks, manages database migrations, and coordinates production releases based on verified test results.
- Cloud-Native Data Architecture: Storage and computing tasks are offloaded to modern cloud data warehouses. These systems dynamically adjust processing resources to complete large transformations quickly without slowing down business applications.
- Analytics Delivery Workflows: Cleaned and structured data is pushed directly to reporting tools, business intelligence portals, and data science environments, ensuring teams always work with reliable information.
- Monitoring Systems: Automated checkers continuously watch the entire pipeline, logging run statuses and alerting engineers via chat applications or incident response tools if a step fails.
CI/CD Lifecycle in DataOps
The operational journey of a data pipeline change follows a structured sequence of lifecycle stages. Each step includes specialized technologies to deliver a specific operational result.
| Stage | Purpose | Technologies Used | Real-World Outcome |
| Source Integration | Track and store pipeline scripts, schemas, and configurations. | Git, GitHub, GitLab, Bitbucket | A clear, auditable history of code modifications with simple rollbacks. |
| Data Ingestion | Bring raw data into the staging layers of the cloud data platform. | Apache Kafka, AWS Kinesis, Fivetran | Structured raw files ready for processing without manual work. |
| Pipeline Development | Create and refine data transformation queries and data flows. | Python, SQL, dbt (Data Build Tool) | Organized, parameterized scripts that handle dynamic processing workloads easily. |
| Automated Testing | Verify code logic accuracy and run data quality checks. | Great Expectations, pytest, dbt test | Faulty code changes and bad data files are blocked before reaching production. |
| Continuous Integration | Compile code, run test suites, and generate deployable packages. | Jenkins, GitHub Actions, GitLab CI | A verified, ready-to-use software build package for production servers. |
| Deployment | Apply database schema changes and update live production pipelines. | Ansible, Terraform, Liquibase | Seamless pipeline upgrades with zero downtime or manual database entry errors. |
| Monitoring | Watch pipeline runtimes, execution errors, and data trends over time. | Prometheus, Grafana, Datadog | Real-time alerts that let engineering teams patch pipeline issues quickly. |
| Continuous Optimization | Review system metadata to reduce processing costs and pick up speed. | Monte Carlo, Snowflake Insights | Efficient query execution and clear cost controls across cloud systems. |
Popular CI/CD & DataOps Tools
Building a reliable DataOps environment requires choosing the right tools across several operational layers.
CI/CD Platforms
These tools serve as the core execution engine for automation. They watch your code repositories for modifications, trigger testing suites, and run the deployment steps required to push changes to your infrastructure.
Workflow Orchestration Tools
Orchestration engines manage your pipeline dependencies. They model complex data workflows, handle retry attempts for transient network failures, and ensure data flows smoothly across different cloud tools.
ETL & ELT Platforms
These frameworks handle the actual extraction, loading, and transformation steps. They convert raw source data into highly polished tables optimized for business reports.
Data Observability & Monitoring Tools
Observability tools look beyond basic system uptime to monitor the actual health of the data inside your tables. They track volume changes, flag unexpected null values, and map data lineage across systems.
The table below compares these prominent tools across different functional layers:
| Tool | Purpose | Difficulty | Enterprise Usage |
| GitHub Actions | CI/CD Automation Engine | Medium | Automates code testing, builds packages, and manages multi-environment releases. |
| Apache Airflow | Workflow Orchestration | High | Coordinates enterprise data workflows using Python-based execution graphs. |
| dbt (Data Build Tool) | Data Transformation & Testing | Low | Enables data analysts to write production-grade transformation models using SQL. |
| Monte Carlo | Data Observability & Quality | Medium | Automatically maps data lineage and flags anomalous data drifts. |
| Snowflake | Cloud Data Warehousing | Low | Serves as a highly scalable cloud repository for enterprise analytical data. |
| Terraform | Infrastructure as Code | High | Provisions cloud servers, storage setups, and network firewalls through configuration files. |
Real-World Use Cases of CI/CD in DataOps
Banking Analytics
Modern financial institutions process millions of global transactions every minute. To detect fraudulent behavior effectively, fraud detection models require clean data fed on a continuous basis. By implementing a DataOps CI/CD pipeline, banks can introduce updated risk assessment variables to live streaming pipelines securely. Automated tests verify that schema changes comply with financial industry standards, preventing dashboard downtime and keeping risk evaluations accurate.
Healthcare Data Systems
Healthcare providers rely on distributed networks to consolidate patient records, lab findings, and pharmacy orders across multiple regional clinics. Manual data updates risk corrupting critical patient data. A standardized DataOps architecture automates these integration pipelines, validating that incoming records conform to strict medical formatting standards. If a database update fails a validation rule, the CI/CD environment halts the migration automatically, protecting patient record availability.
E-Commerce Platforms
E-commerce companies experience massive traffic shifts during promotional holiday sales events. These events require real-time pricing updates and instant inventory management adjustments. DataOps automation handles these fluctuating workloads by scaling computing resources automatically. When data engineers update predictive demand models, the CI/CD pipeline tests the changes using sandbox data and deploys them to production without interrupting the customer checkout experience.
SaaS Analytics
Software-as-a-Service companies collect continuous clickstream data from millions of active users to power product engagement dashboards. Product managers need these metrics to analyze feature adoption trends. With automated CI/CD pipelines, analytics engineers can iterate on user behavior tracking models daily. The automation suite validates data structures, processes aggregations, and delivers refreshed analytical models directly to dashboards without requiring manual database engineering work.
Benefits of CI/CD in DataOps
- Faster Deployments: Automation cuts deployment cycles from weeks to minutes, allowing data engineering teams to respond to business requests almost instantly.
- Better Data Reliability: Moving validation testing to the pre-production stage catches broken code and corrupted records early, keeping bad data out of final dashboards.
- Improved Collaboration: Standardizing development through centralized Git repositories eliminates siloed workflows, helping data engineers, analytics professionals, and administrators collaborate smoothly.
- Reduced Downtime: Automated rollbacks and systematic test environments isolate operational errors, preventing bad updates from breaking critical live systems.
- Automation Efficiency: Shifting from manual data management to code-driven deployment structures frees engineers up from repetitive tasks, allowing them to focus on building new features.
- Scalable Infrastructure: Using Infrastructure as Code principles allows data architectures to scale compute capacity up or down automatically based on data volume demands, controlling cloud costs.
Challenges & Limitations (With Solutions)
Pipeline Complexity
As data ecosystems expand, managing dependencies across hundreds of independent tables, orchestration charts, and cloud environments becomes difficult.
Solution: Use modular design principles. Break complex pipelines down into smaller, self-contained data models using tools like dbt, and map dependencies clearly within a central orchestration system.
Data Quality Issues
Automated code execution does not guarantee the underlying data values are accurate. Bad source data can easily flow through clean code and corrupt downstream tables.
Solution: Build explicit data validation gates directly into your CI/CD workflows. Use testing frameworks to check your data at ingestion points before running downstream transformations.
Integration Challenges
Connecting legacy database infrastructure with modern cloud-native deployment engines often reveals deep system incompatibilities.
Solution: Use containerization technologies like Docker to bundle legacy dependencies into predictable environments, or run lightweight API gateway utilities to bridge legacy systems and cloud environments.
Monitoring Gaps
As pipeline deployment speeds increase, traditional infrastructure logging tools often fail to flag data-specific transformation anomalies.
Solution: Implement dedicated data observability systems alongside standard platform monitoring to track data health metrics like volume shifts, null counts, and schema modifications.
DataOps Career Opportunities
The global push toward automated cloud systems has created a surge in demand for engineering professionals who know how to manage automated data operations.
High-Demand Industry Roles
- DataOps Engineer: Focuses on building, optimizing, and maintaining the CI/CD tools, testing platforms, and cloud infrastructure used by data teams.
- Data Engineer: Designs core data collection paths, configures production storage solutions, and builds scalable data transformation architectures.
- Analytics Engineer: Bridges data engineering and business analysis, using tools like dbt to transform raw data into well-tested, ready-to-use analytical models.
- Cloud Data Engineer: Specializes in cloud infrastructure administration, configuring secure storage, scalable compute layers, and networking for data pipelines.
Professional Skills Profile & Salary Outlook
To excel in this competitive market, professionals need a balanced mix of fundamental data skills and automation capabilities:
- Core Skills: Advanced SQL optimization, programmatic scripting with Python, hands-on Linux system management, and comprehensive Git version control workflows.
- Core Responsibilities: Building automated data pathways, enforcing data quality rules, configuring orchestration routines, and ensuring system security compliance.
- Salary Trends: Due to the specialized skill set required, DataOps professionals command premium salaries globally and across major tech hubs in India, often outpacing traditional database administrators.
- Career Roadmap: Aspiring candidates typically master fundamental SQL and database design, transition into data pipeline development, and then advance to managing multi-environment cloud automation systems.
Beginner Roadmap for Learning DataOps CI/CD
If you are starting from scratch, trying to learn every tool at once can feel overwhelming. Follow this structured learning sequence to build your skills step-by-step:
Step 1: SQL Fundamentals
Master the language of data. Learn how to write complex joins, filter datasets efficiently, use window functions, and optimize query execution plans across relational tables.
Step 2: Python Basics
Learn programming fundamentals. Focus on data handling libraries like Pandas, understand how to work with JSON formats, and practice connecting to external APIs to pull data programmatically.
Step 3: Linux Operating System
Get comfortable with the command line interface. Practice navigating file structures, modifying file permissions, creating basic shell scripts, and handling environmental configuration variables.
Step 4: Git & Version Control
Learn how to track changes to your code. Practice initializing code repositories, managing staging areas, resolving merge conflicts, and using branch workflows for group projects.
Step 5: ETL & ELT Concepts
Understand the theory and practice of moving data. Learn how to extract information cleanly, implement incremental loading strategies to save resources, and design efficient star-schema database designs.
Step 6: CI/CD Fundamentals
Explore the basics of automation. Practice building automated tasks using tools like GitHub Actions, configure simple automated tests, and learn how to manage application release phases.
Step 7: Cloud Data Platforms
Learn your way around modern cloud architectures. Create sandboxes on platforms like AWS or Google Cloud, set up cloud storage buckets, and practice loading datasets into a cloud data warehouse like Snowflake.
Step 8: Workflow Orchestration
Bring your individual tasks together into automated streams. Learn how to build basic execution sequences using tools like Apache Airflow, handle task retries, and set up automated error alerts.
Step 9: Monitoring & Observability
Learn how to watch over live data pipelines. Practice writing data testing suites, learn to monitor query processing durations, and create simple alerts to flag empty tables or failed pipeline steps.
Step 10: Data Governance Basics
Understand the rules of data security and access control. Learn how to mask sensitive customer records, manage database access privileges safely, and track data history for regulatory compliance.
Certifications & Training
Earning an industry certification is a great way to validate your skills, demonstrate practical expertise to employers, and stand out in the job market.
| Certification | Level | Best For | Skills Covered |
| DataOps School Automation Specialist | Beginner | Aspiring DataOps and cloud engineers looking for structural, hands-on experience. | End-to-end CI/CD setups, real-world data pipeline construction, dbt testing, and orchestration mechanics. |
| AWS Certified Data Engineer | Intermediate | Professionals designing and managing data infrastructure on Amazon Web Services. | Cloud data storage configuration, serverless processing setups, data security, and AWS pipeline optimization. |
| Snowflake Core Certification | Beginner | Data analysts and engineers working extensively within cloud-native warehouses. | Virtual warehouse management, data clustering practices, secure data sharing, and storage scaling logic. |
| Astronomer Certified Airflow DAG Author | Intermediate | Developers managing complex, dependency-heavy enterprise orchestration models. | Advanced Python scheduling graphs, connection management, custom operator creation, and execution testing. |
Common Beginner Mistakes
- Ignoring SQL Fundamentals: Many beginners rush into learning complex orchestration engines without mastering core SQL optimization. If your underlying transformation queries are poorly written, no amount of automation will make your pipeline efficient.
- Learning Too Many Tools Together: Trying to learn Jenkins, GitLab CI, Airflow, Prefect, Snowflake, and BigQuery all at once leads to burnout. Focus on mastering one tool per operational layer before expanding your toolkit.
- Skipping Testing Practices: New engineers often focus entirely on getting data to move from point A to point B, ignoring testing steps until something breaks in production. Build testing habits early by writing data validations from day one.
- Lack of Hands-On Projects: Relying entirely on reading tutorials or watching videos won’t prepare you for real engineering challenges. You need to build actual pipelines, cause purposeful configuration failures, and learn how to debug them yourself.
- Focusing Only on Tools: Tools change and evolve constantly, but foundational concepts like version control, data quality validation, and idempotent pipeline design remain consistent across technologies.
Best Practices for DataOps CI/CD
Maintain an Automation-First Mindset
Avoid manual interventions in your production systems. If an environment variable changes or a database configuration needs an update, apply those adjustments through code templates rather than editing properties directly inside a system portal.
Run Continuous Testing Early
Implement data validation tests at the earliest point in your ingestion pipeline. Catching corrupt schema formats or malformed files right when they arrive prevents bad data from causing cascading errors in downstream analytics tables.
Enforce Strict Version Control Workflows
Ensure that every script, database migration file, and orchestration definition lives in your central Git repository. Never make quick fixes directly on a production server; all changes must pass through code review branches.
Build Comprehensive Pipeline Observability
Do not wait for users to email you about broken reports. Configure proactive monitoring setups to track pipeline execution times, row count variances, and processing errors, and pipe those alerts directly to team chat channels.
Future of CI/CD in DataOps
The DataOps field is evolving quickly, driven by new technologies that make data management more intelligent and responsive. We are moving toward autonomous analytics workflows, where systems can use historical execution patterns to self-heal minor errors, adjust query memory allocation dynamically, and optimize schedules on the fly. Real-time DataOps is also growing rapidly, shifting away from batch processing schedules toward continuous data validation loops that check live data streams without slowing down the pipeline.
Hyperautomation and intelligent orchestration tools are changing how teams manage cloud resources. Modern pipelines can automatically spin up additional processing capacity to handle large data spikes, and tear them down the moment the job finishes to control budgets. At the same time, cloud-native environments are deeply integrating data observability platforms, transforming monitoring from simple server uptime checks into automated evaluations of data quality and compliance across the enterprise.
FAQs
1. What is CI/CD in DataOps?
CI/CD in DataOps is a framework that uses automation to manage changes to data pipelines. Continuous Integration (CI) automatically checks and tests code modifications when they are saved to a shared repository. Continuous Delivery (CD) safely deploys those validated changes to production, ensuring that updates to ingestion scripts, data models, and schemas happen reliably without manual intervention.
2. How is DataOps different from DevOps?
DevOps focuses on managing stateless software application code and binary releases. DataOps adapts these principles to handle both code and data. Since data schemas constantly change and historical table states must be preserved, DataOps includes specialized layers for data quality verification, schema drift tracking, and privacy governance.
3. Which tools are used in DataOps CI/CD?
The toolkit spans several layers: GitHub Actions or GitLab CI handle core automation execution; Apache Airflow or Prefect manage task orchestration; dbt processes data transformations and logic testing; and platforms like Snowflake or AWS Redshift provide scalable cloud data storage.
4. Is coding required for DataOps?
Yes, coding is a core requirement for DataOps positions. Professionals write SQL for data transformations, Python for ingestion scripts and orchestration configurations, and shell scripts for infrastructure automation tasks.
5. What is workflow orchestration?
Workflow orchestration is the centralized management of dependent tasks within a data pipeline. It ensures that data tasks run in the correct sequence, automatically retries jobs if there are temporary network drops, logs processing errors, and alerts engineering teams when a step fails.
6. Can beginners learn DataOps?
Absolutely. Beginners can enter the DataOps space by establishing a solid foundation in SQL, Python, and Git version control, and then learning how to use cloud storage platforms and pipeline automation tools through structured training programs.
7. Which cloud platform is best for DataOps?
Major cloud ecosystems like Amazon Web Services (AWS), Google Cloud Platform (GCP), and Microsoft Azure all provide excellent toolkits for DataOps. AWS is widely adopted in large enterprise settings, GCP is highly regarded for its big data analytics services, and Azure integrates cleanly with existing enterprise systems.
8. How long does it take to learn DataOps CI/CD?
For individuals who already understand database fundamentals, mastering DataOps tools and automated workflows typically takes four to six months of regular, practical practice. For complete beginners, it generally takes six to nine months to build the necessary programming and infrastructure skills.
9. Why does data quality testing matter in automation?
Automated pipelines process data at incredibly high speeds. If a pipeline does not include automated data quality checks, it can easily load corrupt or duplicate source data into production databases unnoticed, leading to inaccurate corporate reporting dashboards.
10. What is Infrastructure as Code (IaC) in data engineering?
Infrastructure as Code allows you to define your data infrastructure—such as cloud databases, storage setups, and network firewalls—using text configuration files. This lets teams launch, update, and replicate entire data environments reliably through automation.
11. What role does Git play in DataOps workflows?
Git serves as the single source of truth for all pipeline configurations. It tracks revisions to transformation code, manages database migration scripts, enables collaborative development via code branches, and allows rapid system rollbacks if an update fails.
12. How does dbt simplify data transformation testing?
dbt allows data professionals to build transformation networks using standard SQL. It simplifies testing by offering built-in validation commands to check for null values, verify unique primary keys, and ensure data integrity across related tables automatically.
13. What is schema drift?
Schema drift occurs when database structures at the source application change unexpectedly—such as a third-party API adding a new column or changing a data type—without updating the downstream pipeline, which often causes ingestion failures.
14. How do data visibility platforms prevent reporting downtime?
Data observability platforms track system metadata and historical data trends over time. If a data loading step suddenly processes far fewer rows than its historical daily average, the observability system flags this anomaly automatically so engineers can investigate before business users notice.
15. Are there entry-level opportunities in DataOps?
Yes. The rapid shift toward automated cloud platforms has created a strong market for junior engineers. Companies look for entry-level professionals who understand SQL, Python, and Git fundamentals, and know how to build basic automated pipelines.
Final Thoughts
The shift away from manual, error-prone data engineering workflows is a structural transformation sweeping through the entire enterprise landscape. As modern corporations depend on rapid, data-driven decisions, the old approach of manually moving data and fixing pipelines late at night is no longer viable. Implementing CI/CD in DataOps provides a structured way to handle complex data systems, ensuring updates are safe, repeatable, and highly reliable.
For anyone looking to build a career in data engineering, learning automation is one of the most valuable investments you can make. Tools will always change and evolve, but understanding core principles like version control, automated data quality validation, and pipeline orchestration will remain relevant throughout your career.