Introduction
In modern data engineering, managing data movement manually is no longer sustainable. Organizations handle massive volumes of data arriving from applications, IoT devices, third-party APIs, and databases. To transform this raw data into actionable insights, data teams rely on complex sequences of ingestion, transformation, validation, and delivery. When these steps are executed manually, pipelines become fragile, errors multiply, and decision-making slows down.
For beginners entering the technology space, learning automated analytics workflows provides a major professional advantage. The industry is rapidly moving away from static database management toward dynamic cloud-native data platforms. Understanding how to orchestrate, test, deploy, and monitor data applications programmatically makes you an invaluable asset to any modern enterprise. To gain a deep, structured understanding of these operational methodologies and hands-on skills, exploring the comprehensive curriculum offered by DataOpsSchool is an excellent way to start your journey.
What Is Automation in DataOps Pipelines?
Automation in DataOps pipelines represents the systematic application of software engineering practices to the collection, transformation, validation, and distribution of data. It converts the entire data lifecycle into a continuous, self-correcting machine. Rather than treating data processing as a series of isolated, manual tasks performed by separate database administrators, automation unites these steps into a unified code-driven framework.
The Evolution of Data Engineering Automation
To truly understand modern DataOps automation, we must look at how data management has evolved:
- The Manual & Scripted Era: Decades ago, data moving was handled by custom, hard-coded bash scripts or cron jobs running on local servers. If a server went offline, or a source table changed its format, the script simply failed silently, causing corrupted reporting the next day.
- The Visual ETL Era: Enterprises transitioned to heavy, GUI-based Extraction, Transformation, and Loading (ETL) tools. While this made pipeline creation visual, these tools operated like black boxes. Version controlling changes, testing logic before deployment, and collaborating across large teams remained incredibly difficult.
- The Modern DataOps Era: Today, pipelines are treated exactly like software applications. Infrastructure is defined as code, data transformations are written in structured software languages or version-controlled SQL, and testing is automated at every stage.
The Relationship Between DataOps and DevOps
DataOps is not an entirely separate philosophy; it is an evolution of DevOps tailored for data ecosystems. While DevOps focuses on automating the software development lifecycle (building, testing, and deploying application code), DataOps focuses on automating both the code development lifecycle and the continuous flow of data through that code.
| Aspect | DevOps | DataOps |
| Primary Focus | Application code, binaries, and microservices. | Data quality, data pipelines, and analytical models. |
| The Variable Element | The code changes; the environment is kept stable. | Both the code changes and the incoming data changes constantly. |
| Core Goal | High deployment frequency with low failure rates. | High data reliability and fast insights delivery. |
Traditional Data Processing vs. Automated Pipelines
Traditional data processing relies on scheduled batches that run blindly, assuming everything in the environment is perfect. If an input file is missing a column, a traditional pipeline often processes it anyway, pushing corrupted data directly to executive dashboards.
Automated DataOps pipelines operate with built-in intelligence. They verify data integrity prior to processing, dynamically provision cloud computing power based on the volume of incoming data, route failures to isolated quarantine zones, and automatically notify engineering teams with precise debugging logs.
Why Enterprises Need Workflow Automation
Enterprises operate in highly competitive environments where data decay happens rapidly. Information lose its strategic value the longer it sits unprocessed. Manual intervention creates a structural bottleneck that prevents companies from being truly data-driven. Workflow automation guarantees that data moves through the organization at maximum velocity, keeping security policies, compliance rules, and quality standards strictly enforced without human overhead.
The Core Philosophy of Agile Analytics Operations
The underlying philosophy of agile analytics is simple: Build small, test constantly, automate everything, and iterate quickly. Data pipelines should not be monolithic, fragile structures that everyone is afraid to touch. By modularizing pipelines into automated components, teams can safely deploy updates to transformation logic, introduce new data sources, and scale operations without disrupting business continuity.
Why Automation Matters in DataOps Pipelines
[Raw Data Sources] ──> [Automated Ingestion] ──> [Automated Validation]
│
[Business Dashboards] <── [Automated Loading] <── [Automated Transformation]
Implementing automation across data systems yields immediate, measurable improvements in enterprise performance. It directly affects operational efficiency, product quality, and organizational agility.
Faster Analytics Delivery
When pipelines run automatically based on events or precise schedules, the time between data creation and insight generation drops from days to seconds. Marketing teams can analyze campaign performance in real-time, financial teams can monitor expenditure lines instantly, and operations teams can detect system anomalies before they impact customers.
Reduced Manual Errors
Human beings are poorly suited for repetitive, high-volume validation tasks. A tired engineer missing a configuration line or running a legacy migration script out of order can compromise data lakes. Automation executes tasks exactly as written every single time, ensuring absolute predictability.
Improved Scalability
During peak demand periods—such as end-of-quarter financial processing or global shopping events—data volumes can spike by 10x or 100x. Manual systems buckle under this pressure. Automated pipelines leverage cloud-native elastic scaling, instantly spinning up processing clusters to handle heavy loads and spinning them down afterward to control costs.
Real-Time Data Processing
Modern businesses cannot wait for nightly batch windows to make decisions. Automation enables event-driven architectures where the arrival of a single data point triggers immediate streaming processing, enrichment, and analytical availability.
Better Collaboration
By defining data pipelines as code, data engineers, analytics engineers, data scientists, and business analysts can collaborate using shared repositories. Changes to data models are proposed, reviewed, tested, and deployed through transparent, automated mechanisms, eliminating communication silos.
Governance Automation
Compliance with global data protection laws (such as GDPR or CCPA) cannot be left to manual verification. Automation ensures that data masking, PII encryption, lineage tracking, and access control policies are applied uniformly to every piece of information traversing the pipeline.
Workflow Consistency
Automation guarantees that every single run of a data pipeline adheres to the exact same validation, cleaning, and optimization rules. This consistency establishes a baseline of trust across the organization, as business units know that data definitions remain uniform across all reports.
Faster Decision-Making
When data delivery is fully automated, executives and operational managers no longer waste time debating whether a dashboard’s metrics are up to date or accurate. They shift their focus entirely toward interpreting the data and making rapid decisions to outmaneuver competitors.
Core Concepts of DataOps Automation
To construct a high-performing automated data infrastructure, you must understand its foundational pillars. Each pillar addresses a specific segment of the data lifecycle.
ETL & ELT Automation
The process of Extraction, Transformation, and Loading (ETL), or its modern cloud variant Extraction, Loading, and Transformation (ELT), forms the core of data engineering.
- Extraction Automation: Automated connectors tap into APIs, application databases, and object stores to pull new data without manual query generation.
- Loading Automation: Data is continuously piped into central data warehouses or data lakes, adjusting automatically to shifting ingestion speeds.
- Transformation Automation: Raw structural data is converted into clean business schemas. Tools like dbt (data build tool) allow engineers to write transformations in SQL, which are then compiled, executed, and automated across target environments.
Workflow Orchestration
Data pipelines consist of numerous interdependent steps. For instance, you cannot transform a table until the extraction phase completes successfully. Workflow orchestration acts as the conductor of this orchestra.
Orchestration platforms manage the complex dependencies of these tasks, establishing directed acyclic graphs (DAGs) to define the exact sequence of events. If a task fails, the orchestration engine manages retries, redirects workloads, logs errors, and alerts the engineering team.
CI/CD for Data Pipelines
Continuous Integration and Continuous Deployment (CI/CD) brings classic software development rigor to data workflows.
- Continuous Integration (CI): When an engineer alters a data pipeline script or SQL model, the changes are pushed to a central repository. Automated tests run instantly to check for syntax errors, structural regressions, and logic flaws before the code is merged.
- Continuous Deployment (CD): Once the code passes all checks, automated deployment systems push the updated pipeline configuration into staging and production environments seamlessly, eliminating manual server updates.
Data Validation Automation
Processing bad data wastes money and destroys business trust. Automated data validation acts as a quality checkpoint within the pipeline. Using data quality frameworks, pipelines programmatically verify that incoming data adheres to strict structural constraints—such as checking that phone numbers match expected formats, crucial IDs are never null, and financial figures fall within sensible boundaries—before letting it move downstream.
Monitoring & Observability
You cannot fix what you cannot see. Data observability automation continuously tracks the health of both the infrastructure and the data moving inside it. Automated observability tools track freshness (is the data arriving on time?), volume (did we suddenly ingest zero rows instead of millions?), schema changes (did an application developer change a column name without telling us?), and system metrics (CPU, memory, and database storage utilization).
Infrastructure Automation
Modern data engineering relies heavily on Cloud Infrastructure as Code (IaC). Instead of manually clicking buttons in cloud consoles to provision servers, storage buckets, and data warehouses, teams use tool configurations to define their entire analytics ecosystem. This ensures that staging and production environments are identical, easily reproducible, and completely automated.
Governance Automation
Automated governance removes human guesswork from compliance and data security. As data flows through a pipeline, automated systems automatically tag sensitive classification items, mask personal information, generate comprehensive data lineage graphs, and enforce strict identity and access management (IAM) permissions based on predefined organizational rules.
Real-Time Analytics
Real-time analytics automation enables continuous data streaming and immediate processing. It utilizes specialized distributed messaging systems and streaming engines to clean, aggregate, and analyze data on the fly. This architecture allows companies to run immediate fraud detection routines or dynamically update ride-sharing wait times.
Cloud-Native Pipelines
Cloud-native design focuses on decoupling storage and compute resources, allowing each layer to scale independently. Automation engines utilize these characteristics by programmatically requesting resources from the cloud provider during heavy processing phases and releasing them immediately after completion, keeping operational costs highly optimized.
Automated Testing
Data testing covers two core areas: testing the underlying pipeline logic (unit testing code blocks) and testing the actual data flowing through that logic. Automated systems run these validation checks continuously during both development cycles and active production execution, stopping data issues directly at the source.
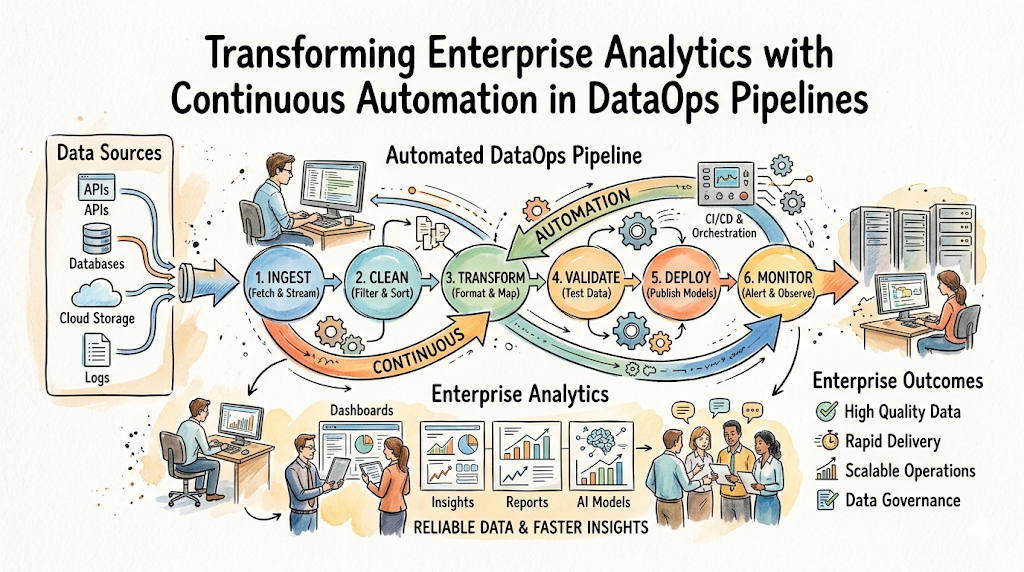
DataOps Automation Architecture & Workflow
A resilient, scalable DataOps automation architecture functions as an assembly line where raw materials are systematically processed into refined products. Let us walk through the functional sequence of an enterprise-grade automated pipeline.
[Applications & APIs] ──> Ingestion Layer (Kafka / Airbyte)
│
▼
Storage Layer (S3 / Cloud Data Lake)
│
▼
Orchestration & Validation (Airflow / Great Expectations)
│
▼
Transformation Layer (dbt / Snowflake)
│
▼
Governance & Observability (DataDoc / OpenLineage)
│
▼
Consumption Layer (BI Dashboards / AI Models)
1. The Data Ingestion Layer
The process begins at the edge of the enterprise ecosystem. Automated connectors monitor external production databases, application logs, SaaS platforms, and third-party APIs. As soon as new application events occur, ingestion tools capture and transmit them into a central landing zone without human oversight.
2. The Data Storage & Landing Zone
Raw data lands securely within an enterprise data lake or cloud object storage container. The arrival of these files triggers an automated event notification, signaling to the next phase of the architecture that fresh processing components have arrived.
3. The Orchestration & Validation Gate
The workflow orchestration engine detects the incoming data event or reaches its scheduled execution window. It starts the pipeline run by first triggering data validation routines. These automated checks analyze the schema structure, confirming that no columns have been corrupted or dropped during transit.
4. The Transformation & Enrichment Layer
Once validated, the raw files move to the compute layer—such as a cloud data warehouse or a distributed processing cluster. The orchestration engine calls transformation models to run heavy-duty cleaning operations, strip out duplications, resolve formatting discrepancies, join disparate tables, and calculate complex business aggregates.
5. The Monitoring, Lineage, and Observability Layer
Simultaneously, an observability layer tracks every single step of the transformation journey. It logs execution runtimes, counts processed rows, documents exact data lineage maps, and validates that performance metrics sit well within typical operational limits.
6. The Consumption & Analytics Delivery Layer
The finalized, cleaned, and optimized tables are automatically written to production business intelligence schemas. Downstream business dashboards, machine learning frameworks, and predictive enterprise models refresh their interfaces immediately, delivering clean, trustworthy metrics straight to business users.
Automated DataOps Pipeline Lifecycle
To implement automation effectively, data engineers must map out each phase of the data lifecycle alongside its operational purpose and toolsets.
| Stage | Purpose | Technologies Used | Real-World Outcome |
| Data Collection | Capture raw telemetry and system logs from distributed application endpoints. | Apache Kafka, AWS Kinesis, Fluentd | Continuous, uninhibited streams of raw system events gathered instantly. |
| Data Ingestion | Transfer raw data from collection endpoints to centralized enterprise storage pools. | Airbyte, Fivedran, Apache NiFi | Centralized, durable raw repositories ready for downstream processing. |
| Transformation | Standardize schemas, clean formatting, resolve duplicate records, and apply business logic. | dbt, Apache Spark, Databricks | Structured, high-value relational tables optimized for analytical query execution. |
| Validation & Testing | Confirm data accuracy, structural schema alignment, and business metric integrity. | Great Expectations, Soda, pytest | Complete elimination of corrupted data or missing records reaching production. |
| Workflow Automation | Manage multi-tier task dependencies, handle job retries, and coordinate operational tasks. | Apache Airflow, Prefect, Dagster | End-to-end hands-off execution of interconnected corporate data jobs. |
| Analytics Processing | Compute complex business metrics, aggregate historic tables, and generate reporting files. | Snowflake, Google BigQuery, AWS Redshift | Fast performance for corporate analytics dashboards and reporting suites. |
| Monitoring | Track systemic resource usage, performance anomalies, pipeline latency, and process halts. | Datadog, Prometheus, Grafana | Instant system alerts sent directly to engineers before errors impact users. |
| Continuous Optimization | Analyze pipeline performance data to tune compute allocations and control cloud costs. | Cloud Spend APIs, custom tracking scripts | Low operational overhead paired with resource scaling. |
Popular DataOps Automation Tools
Building a modern DataOps framework requires selecting the right tools for your operational requirements. Let us evaluate the leading industry platforms across the core categories of data automation.
Workflow Orchestration Tools
Orchestration engines serve as the central control room for enterprise data pipelines, managing task sequencing and systemic error recovery.
- Apache Airflow: The open-source industry standard. It defines workflows as Python code, offering deep flexibility and an extensive ecosystem of community integrations.
- Prefect: A modern, developer-centric orchestrator designed to handle dynamic, real-time workflows easily with low operational overhead.
- Dagster: An orchestration engine focused heavily on data assets, local development testing capabilities, and deep data lineage tracking.
| Tool | Purpose | Difficulty | Enterprise Usage |
| Apache Airflow | Complex, multi-system enterprise scheduling. | Advanced | High; widely adopted across global fortune 500 tech stacks. |
| Prefect | Developer-friendly, dynamic pipeline workflows. | Intermediate | Growing rapidly within agile, cloud-native tech companies. |
| Dagster | Asset-oriented pipelines with built-in data tracking. | Intermediate | Adopted by data teams focused heavily on software engineering practices. |
ETL & ELT Platforms
These platforms automate extracting data from various sources and moving it safely into central analytical environments.
- dbt (data build tool): Focuses entirely on the transformation layer inside data warehouses, allowing teams to manage data models using SQL combined with software best practices.
- Fivetran: A fully managed, zero-maintenance data ingestion service that provides automated connectors for hundreds of data sources.
- Airbyte: A powerful open-source data integration platform that enables teams to deploy custom and pre-built ingestion connectors flexibly.
| Tool | Purpose | Difficulty | Enterprise Usage |
| dbt | Transforming raw warehouse data into clean tables. | Beginner | Massive; standard tool for modern analytics engineering teams. |
| Fivetran | Hands-off cloud data ingestion. | Beginner | High among enterprise teams prioritizing minimal maintenance. |
| Airbyte | Open-source, flexible data integration. | Intermediate | Growing fast for companies seeking open-source data control. |
CI/CD Tools
CI/CD tools run automated tests and handle application deployments every time a data team updates code.
- GitHub Actions: Automates workflows right inside your GitHub repositories, making it simple to test data models and run linters on every commit.
- GitLab CI/CD: A robust enterprise platform that provides built-in container registries and advanced pipeline tracking for data engineering teams.
- Jenkins: A classic, highly customizable automation server frequently used to orchestrate complex on-premises testing and deployment tasks.
| Tool | Purpose | Difficulty | Enterprise Usage |
| GitHub Actions | Git-integrated automated testing and deployment. | Beginner | High; standard for teams hosting repositories on GitHub. |
| GitLab CI/CD | Enterprise-grade dev workflows and security scanning. | Intermediate | Dominant in large corporate environments with unified compliance rules. |
| Jenkins | Legacy and highly custom private deployments. | Advanced | Standard in traditional enterprises running hybrid or on-prem hardware. |
Cloud Data Platforms
Cloud platforms provide the scalable computing power and storage required to process large amounts of data.
- Snowflake: A cloud-native data platform featuring instantly adjustable compute resources, seamless data sharing, and zero infrastructure management overhead.
- Google BigQuery: A serverless, highly scalable cloud data warehouse designed to analyze petabytes of data using fast SQL queries.
- Databricks: A unified analytics platform built on Apache Spark, combining data lakes and data warehouses into a high-performance lakehouse architecture.
| Tool | Purpose | Difficulty | Enterprise Usage |
| Snowflake | Multi-cloud data warehousing and sharing. | Beginner | Massive adoption across enterprises seeking simple SQL scalability. |
| Google BigQuery | Serverless big data analytics and machine learning. | Beginner | Dominant among organizations using Google Cloud and marketing analytics. |
| Databricks | Advanced big data processing and machine learning models. | Advanced | Standard for enterprise teams processing complex data science workloads. |
Monitoring & Observability Tools
Observability tools give teams full visibility into pipeline health and data quality, catching issues before they impact business decisions.
- Datadog: A monitoring platform that tracks infrastructure performance, system metrics, and logs across data ecosystems.
- Monte Carlo: An enterprise data observability platform that automatically detects data anomalies, lineage bugs, and broken pipelines.
- Great Expectations: An open-source data validation framework that lets teams explicitly define exactly what clean data should look like.
| Tool | Purpose | Difficulty | Enterprise Usage |
| Datadog | Monitoring infrastructure health and system logs. | Intermediate | High; widely used to monitor complete corporate application stacks. |
| Monte Carlo | End-to-end data quality and anomaly detection. | Intermediate | Adopted by companies managing mission-critical analytics pipelines. |
| Great Expectations | Writing automated data validation tests. | Intermediate | High; used by engineers to assert data quality within processing steps. |
Governance & Security Platforms
Governance platforms automate security policies, access controls, and compliance tracking across data assets.
- Apache Atlas: Provides open-source data governance, asset cataloging, and lineage tracking capabilities for enterprise data ecosystems.
- Collibra: A data intelligence platform that automates data governance, cataloging, and policy enforcement across large organizations.
- Immuta: Automates data security, access control, and privacy enforcement, ensuring sensitive information stays safe across cloud platforms.
| Tool | Purpose | Difficulty | Enterprise Usage |
| Apache Atlas | Open-source data governance and lineage maps. | Advanced | Used by enterprise teams managing large, open-source data infrastructure. |
| Collibra | Data cataloging and corporate compliance tracking. | Intermediate | Dominant across banking, healthcare, and heavily regulated sectors. |
| Immuta | Automated cloud data access control and masking. | Intermediate | High for enterprise teams handling highly sensitive or restricted data. |
Real-World Use Cases of DataOps Automation
Let us look at how different industries leverage automated DataOps architectures to solve complex operational challenges.
Banking & Finance
Financial institutions use automated pipelines to process millions of transactions per second. In credit card processing, automated ingestion pipelines feed real-time streaming tools that evaluate risk metrics within milliseconds. If a transaction looks anomalous, it is instantly flagged for review. Automation also generates audit logs automatically, keeping the institution compliant with financial regulations without manual effort.
Healthcare Analytics
Hospitals and research institutions utilize automated pipelines to integrate patient data from electronic health records, wearable devices, and lab systems. These automated pipelines clean and mask protected health information (PII) before feeding the data into analytics dashboards. This lets care providers monitor patient outcomes and track hospital capacity in real time while maintaining strict regulatory compliance.
E-Commerce Platforms
Online retailers rely heavily on automated workflows to manage dynamic pricing and inventory tracking. As users browse and purchase products, transaction data flows into real-time pipelines that update inventory systems and adjust pricing algorithms instantly. This keeps product availability accurate across the platform and optimizes profit margins automatically during high-volume sales events.
SaaS Applications
Software-as-a-service providers use automated pipelines to deliver product usage insights to customer success and product teams. User interaction logs flow continuously into data warehouses, where automated models calculate engagement metrics and churn risks daily. These insights are routed directly into customer relationship tools, giving teams the data they need to improve user retention.
Telecom Systems
Telecommunications networks generate massive volumes of call detail records and network performance telemetry. Automated DataOps pipelines ingest these streams continuously to monitor network health and detect dropped connections or service degradation instantly. Automated systems route workloads away from failing equipment, keeping network uptime high without needing immediate manual intervention.
Manufacturing Analytics
Smart factories use IoT sensors on assembly lines to track equipment performance in real time. Automated pipelines process these sensor streams continuously to calculate machine degradation metrics. When a component shows signs of wear, the system automatically triggers a maintenance ticket, preventing unexpected breakdowns and costly assembly line stops.
Marketing Analytics
Modern digital marketing campaigns generate vast amounts of performance data across social media platforms, search engines, and programmatic ad networks. Automated pipelines gather these fragmented data points hourly, standardizing conversion values and spending metrics into a single dashboard. This allows marketing teams to optimize their ad spend and shift budgets toward high-performing campaigns instantly.
Enterprise Reporting Systems
Large global enterprises often have data scattered across separate business units, geographies, and legacy applications. Automated DataOps pipelines bridge these gaps by extracting data from disparate systems nightly, transforming it into a single corporate schema, and generating unified financial and operational reports. This ensures executive leadership bases strategic decisions on a single, trusted source of truth.
Benefits of Automation in DataOps Pipelines
[ Manual Workflows ] ──> High Errors ──> Days to Deploy ──> High Costs
[ Automated DataOps] ──> Low Errors ──> Mins to Deploy ──> Optimized Costs
- Faster Pipeline Deployment: Data teams can ship updates to production in minutes rather than weeks by using automated testing and CI/CD pipelines instead of manual configuration checklists.
- Better Data Reliability: Automated validation tests inspect data at every step, preventing bad or corrupted data from reaching business dashboards and undermining executive trust.
- Improved Analytics Efficiency: Automating repetitive data cleaning and aggregation tasks lets data professionals focus on building innovative features rather than fixing broken processes.
- Reduced Operational Costs: Cloud-native automation handles infrastructure dynamically, scaling computing resources up during heavy processing loads and shutting them down immediately after to eliminate wasted spend.
- Real-Time Analytics Capabilities: Event-driven automation eliminates artificial batch delays, enabling businesses to capture and analyze data the moment it is generated.
- Better Collaboration: Treating pipelines as code allows engineering, analytics, and business teams to work together out of shared repositories using clear, auditable processes.
- Improved Governance: Automated data masking, access control, and lineage tracking ensure continuous compliance with global data protection standards without manual overhead.
- Automation Scalability: Automated pipelines handle sudden spikes in data volume smoothly, utilizing cloud resource allocation to maintain consistent performance without system crashes.
Challenges & Limitations
While the benefits are significant, implementing enterprise-wide DataOps automation comes with its own set of challenges. Understanding these challenges helps teams avoid common implementation pitfalls.
Workflow Complexity
As an organization grows, its data pipeline network can become highly complex, consisting of hundreds of interconnected tasks and dependencies. If these dependencies are designed poorly, a single failure can trigger a cascade of issues across multiple downstream business units.
Solution: Use clear modular design patterns when building your workflows. Break complex, monolithic processes down into smaller, self-contained data assets that are easier to test, monitor, and maintain.
Tool Integration Challenges
The modern data landscape is full of specialized tools for ingestion, transformation, orchestration, and observability. Making these diverse platforms work together smoothly often requires writing significant amounts of custom integration code and configuration scripts.
Solution: Build your data stack around open standards and modern tools that offer native APIs and pre-built integration modules, minimizing the need for custom glue code.
Infrastructure Costs
Cloud computing platforms provide great elasticity, but automated pipelines that trigger unoptimized queries or process massive volumes of data inefficiently can quickly run up large cloud infrastructure bills.
Solution: Implement strict timeouts, resource caps, and automated alerts to track and manage cloud compute spend. Optimize your data models by using partitioning and efficient indexing strategies.
Governance Issues
When data flows automatically across multiple systems, warehouses, and storage buckets, maintaining strict control over data privacy, access permissions, and regulatory compliance becomes challenging without centralized systems.
Solution: Use automated governance tools to enforce security policies directly within your processing code, ensuring data masking and access controls apply uniformly everywhere.
Security Concerns
Automated pipelines require access credentials, API keys, and connection strings to interact with various source databases and cloud platforms. Managing these sensitive keys securely becomes a priority as your data ecosystem grows.
Solution: Never hardcode credentials into your data scripts or code repositories. Use secure, dedicated secret management services to inject credentials into your pipelines safely at runtime.
Monitoring Blind Spots
Setting up basic infrastructure alerts is simple, but pipelines can still experience quiet failures—such as a process completing successfully but delivering empty rows or corrupted metrics that slip past basic infrastructure checks.
Solution: Implement comprehensive data observability that monitors data health metrics like volume variations, data freshness, and schema changes, rather than tracking system uptime alone.
Skill Shortages
Building and maintaining advanced automated data systems requires a deep blend of skills across software engineering, data management, cloud computing, and DevOps practices, which can make finding qualified engineers difficult.
Solution: Invest in training your current engineering team on modern data practices, establish clear internal design standards, and focus on using clear, user-friendly tooling.
Scalability Limitations
While cloud systems scale well, legacy on-premises databases or external third-party APIs can struggle to handle the high volume of parallel requests generated by modern automated data pipelines.
Solution: Implement rate-limiting, queuing mechanisms, and staging buffers within your ingestion layer to protect legacy source systems from being overwhelmed by automated requests.
Career Opportunities in DataOps Automation
The rapid shift toward automated data ecosystems has created significant industry demand for skilled professionals who understand how to design, build, and maintain these automated systems.
- DataOps Engineer: Bridges the gap between traditional operations and data engineering. They design CI/CD deployment pipelines, manage secret infrastructure, and optimize the overall runtime environment for data jobs.
- Analytics Engineer: Works at the intersection of data engineering and business analysis. They write clean, version-controlled transformation code using tools like dbt to convert raw data into structured schemas for analysis.
- Data Platform Engineer: Focuses entirely on building and maintaining the foundational data infrastructure, including cloud data warehouses, orchestration platforms, and large distributed processing clusters.
- Workflow Automation Engineer: Specializes in designing, scheduling, and monitoring complex task networks, ensuring data flows smoothly across different enterprise tools and business environments.
- Cloud Data Engineer: Builds scalable systems that ingest, transform, and store data within cloud environments, optimizing pipeline performance and resource use.
- BI Engineer: Connects data platforms to business users, design optimized reporting models, and building automated delivery workflows for business intelligence metrics.
- Pipeline Automation Specialist: Focuses on implementing automated quality testing, schema validation checks, and deployment systems to keep data processing fast and reliable.
Required Skills & Industry Roadmap
To succeed in these roles, professionals need a solid foundation across several key technology domains:
[SQL & Python] ──> [Linux & Cloud] ──> [ETL & Orchestration] ──> [CI/CD & Observability]
- Core Technical Skills: Proficient with SQL for data manipulation, Python for automation scripting, and Linux command-line operations.
- Cloud Platforms: Hands-on experience managing infrastructure within major cloud ecosystems like AWS, Google Cloud, or Microsoft Azure.
- Data Architecture: Deep understanding of relational data models, data lake structures, and modern ELT design patterns.
- Orchestration and Tooling: Experience building workflows in platforms like Apache Airflow, writing transformations in dbt, and managing environments with infrastructure tools.
- Daily Responsibilities: Writing clean transformation models, updating orchestration charts, building automated validation tests, and debugging performance bottlenecks.
- Salary and Demand Trends: Data automation professionals command strong compensation packages globally due to the direct impact their work has on enterprise efficiency and business intelligence accuracy.
Beginner Roadmap for Learning DataOps Automation
If you are starting from scratch, learning data automation can feel overwhelming. Following a structured, step-by-step learning roadmap helps you build your skills logically and effectively.
Step 1: Master SQL Fundamentals
SQL is the foundational language of data. Focus on learning how to query tables, filter results, perform complex joins, write subqueries, and use window functions to aggregate data effectively.
Step 2: Build Python Basics
Python is the primary language used to script and automate data workflows. Learn core programming concepts like data structures, loops, file handling, working with APIs, and manipulating data using libraries like Pandas.
Step 3: Learn Linux & Command Line Basics
Most modern data tools and pipelines run on Linux servers or inside containers. Get comfortable using the terminal to navigate filesystems, manage permissions, edit configurations, and write basic automation scripts.
Step 4: Explore Cloud Computing Basics
Modern data pipelines live in the cloud. Learn how cloud ecosystems operate, focusing on core concepts like virtual machines, cloud storage buckets, identity and access management (IAM), and basic networking.
Step 5: Understand Core Data Engineering Concepts
Learn the core theories behind data management. Study the differences between transactional databases (OLTP) and analytical data warehouses (OLAP), explore star schemas, and learn how data lakes store raw files.
Step 6: Practice ETL & ELT Workflows
Move from theory to practice by building your first pipelines. Practice extracting data from web APIs, saving it into local or cloud storage, cleaning the schemas, and loading the results into a database.
Step 7: Dive into Workflow Orchestration
Learn how to manage multi-step pipelines programmatically. Start building directed acyclic graphs (DAGs) in a tool like Apache Airflow to sequence tasks, schedule pipeline runs, and handle job errors automatically.
Step 8: Learn CI/CD Fundamentals
Apply software development best practices to your data workflows. Practice using Git for version control and build simple automation tasks with GitHub Actions to test your scripts automatically whenever you update your code.
Step 9: Implement Monitoring & Observability
Learn how to track the health of your pipelines. Practice writing validation checks to catch data errors early, look for missing values, and log execution metrics to see how your pipelines perform over time.
Step 10: Study Governance & Security Basics
Wrap up your learning by studying data security. Learn how to encrypt sensitive data at rest and in transit, practice masking personal information, and set up clear user access permissions to keep data safe.
Practical Learning Advice
The best way to learn data automation is by building real projects. Avoid the trap of simply watching tutorials without writing code. Instead, set up open-source tools locally, download public datasets, write custom transformation scripts, and build your own automated pipeline projects from scratch.
Certifications & Training
Structured training programs and professional certifications can help accelerate your learning path, validate your skills, and stand out to enterprise recruiters.
| Certification | Level | Best For | Skills Covered |
| DataOps Automation Professional | Beginner | Individuals entering data engineering and operations careers. | Core DataOps principles, pipeline design, automated testing, and basic orchestration. |
| Certified Analytics Engineering Specialist | Intermediate | Professionals transitioning from business analysis to data automation roles. | Advanced transformation engineering, SQL modeling, version control, and data validation frameworks. |
| Cloud Data Engineering Professional | Intermediate | Engineers designing scalable, cloud-native data infrastructures. | Cloud data warehousing, serverless processing, security integration, and cost optimization strategies. |
| Enterprise Workflow Orchestration Architect | Advanced | Senior engineers managing large, multi-system pipeline networks. | Designing complex workflows, custom orchestration deployments, and advanced error handling. |
Common Beginner Mistakes
- Ignoring Data Engineering Fundamentals: Jumping straight into complex automation tools without a solid understanding of basic SQL, relational databases, and clean data modeling patterns.
- Learning Too Many Tools Together: Trying to master Airflow, Prefect, dbt, Spark, and Snowflake all at once, which often leads to confusion. Focus on mastering one core tool per category before expanding your stack.
- Skipping Governance Concepts: Building pipelines that ignore data security and compliance, resulting in systems that cannot be deployed in professional enterprise environments due to privacy risks.
- Lack of Hands-on Projects: Spending all your time watching video courses without writing code, configuring tools, or building real, working data pipelines yourself.
- Focusing Only on Tools: Memorizing specific tool interfaces instead of understanding the underlying engineering principles, which limits your ability to adapt as tooling evolves.
- Ignoring Monitoring and Observability: Building pipelines that run fine under perfect conditions but fail silently or provide corrupted metrics the moment real-world data format changes.
Best Practices for DataOps Automation
To build durable, scalable, and secure data pipelines, your engineering team should follow these core design principles.
- Automation-First Mindset: Design every data workflow with the assumption that it must run, scale, and recover from errors completely on its own, without needing manual human intervention.
- Continuous Monitoring: Set up detailed observability metrics that track data quality, freshness, row counts, and structural changes, so you catch data issues before they reach business users.
- Governance-First Strategy: Embed clear data validation, privacy masking, access controls, and compliance tracking directly into your pipeline configurations from day one.
- Security Integration: Manage all system credentials, connection strings, and API keys using dedicated secret management platforms, keeping passwords out of your source repositories.
- Workflow Standardization: Use clear, unified design patterns, naming conventions, and file structures across all data models and pipelines to make collaboration simple and easy.
- Comprehensive Documentation: Document your data schemas, pipeline dependencies, and business logic definitions inside automated data catalogs so the entire organization can find and understand the data.
- Cloud Optimization: Review your pipeline query patterns and compute allocations regularly to leverage cloud scaling efficiently and keep infrastructure costs under control.
- Observability Implementation: Collect deep execution logs and lineage maps for every pipeline run, making it easy to troubleshoot issues and track how data transforms across your systems.
Future of Automation in DataOps Pipelines
The landscape of data engineering continues to evolve rapidly. As enterprise data environments grow larger, the methods we use to automate and optimize pipelines are becoming increasingly intelligent.
AI-Driven Pipeline Automation
Modern pipelines are starting to move beyond rigid, pre-configured rules. Future data platforms will leverage machine learning models to analyze historical processing patterns, predict runtime bottlenecks, and automatically adjust index configurations and partitioning layouts to optimize query performance without human intervention.
Autonomous Analytics Workflows
We are moving toward self-contained systems that can detect changes in source applications automatically. When a production database adds new fields or shifts its data structure, autonomous pipelines will discover the changes, infer the appropriate data types, update downstream schemas safely, and continue processing data smoothly without crashing.
Real-Time Cloud Analytics at Scale
The line between traditional batch processing and real-time streaming will continue to blur. Future architectures will feature unified computation layers that handle both historical data analysis and real-time event processing through a single, automated interface, allowing businesses to react to new insights instantly.
Intelligent Orchestration
Orchestration engines are shifting from basic time-based schedules to dynamic, context-aware execution frameworks. Future systems will optimize task order in real time based on infrastructure costs, data urgency, system dependencies, and current cloud resource availability.
Generative AI in Analytics
Generative AI tools are changing how data teams build workflows by helping write clean SQL queries, generate pipeline code templates, and build comprehensive test suites automatically. This speeds up development cycles and allows engineers to focus on high-level architecture design rather than repetitive boilerplate coding.
Hyperautomation
Hyperautomation focuses on identifying and automating every possible data process across an organization—including ingestion setup, schema definition updates, quality monitoring, compliance auditing, and infrastructure scaling—creating a completely hands-off data ecosystem.
Cloud-Native Observability
As data environments become more distributed, observability is integrating directly into the cloud infrastructure layer. Future tools will provide deep, automated visibility into data lineages, data health metrics, and infrastructure performance out of the box, making troubleshooting simple.
Self-Optimizing Data Pipelines
Future data pipelines will behave like adaptive systems. By continuously monitoring their own execution performance, data fresh rates, and cloud resource costs, these self-optimizing networks will tune their own compute configurations in real time, delivering high performance at the lowest possible cost.
FAQs
1. What is automation in DataOps?
Automation in DataOps is the practice of using software tools, code, and configuration scripts to manage the collection, transformation, testing, and delivery of data. It replaces manual database processes with automated workflows, minimizing human error and ensuring fast, predictable data delivery.
2. Why do enterprises automate data pipelines?
Enterprises automate their data pipelines to eliminate operational bottlenecks, reduce manual processing errors, scale their infrastructure efficiently, and speed up analytics delivery. This ensures business leaders base their daily strategic decisions on fresh, trustworthy, and accurate data.
3. What tools are used in DataOps automation?
DataOps environments combine several specialized tools across different layers. Teams use orchestration engines like Apache Airflow or Prefect, transformation frameworks like dbt, ingestion tools like Airbyte or Fivetran, cloud platforms like Snowflake, and observability tools like Great Expectations.
4. Is coding required for DataOps?
Yes, a solid understanding of coding is necessary for professional DataOps engineering. Because modern data pipelines are treated as software systems, you need to be comfortable writing SQL queries to manipulate data, Python scripts to automate tasks, and configuration files to manage infrastructure.
5. What is workflow orchestration?
Workflow orchestration is the centralized scheduling, sequencing, and coordination of the various tasks that make up a data pipeline. Orchestration tools manage the complex dependencies between tasks, handle job retries automatically when errors occur, and log pipeline metrics.
6. Can beginners learn DataOps automation?
Yes, beginners can absolutely learn data automation if they follow a structured learning path. Start by mastering core foundational skills like SQL and Python before moving on to advanced tools like orchestration engines, cloud platforms, and CI/CD pipelines.
7. Which cloud platform is best for analytics?
All major cloud platforms—including Amazon Web Services (AWS), Google Cloud Platform (GCP), and Microsoft Azure—offer excellent, enterprise-grade tools for data analytics. The best choice depends on your organization’s current infrastructure, budget, and specific tool integration needs.
8. How long does it take to learn DataOps?
The time it takes depends on your technical background. If you already understand basic programming and SQL concepts, you can learn modern data automation principles in a few months of dedicated study. For complete beginners, it typically takes six months to a year of steady practice to build professional competence.
9. What is the difference between ETL and ELT?
Traditional ETL (Extract, Transform, Load) extracts data, cleans it on a separate processing server, and then loads it into a database. Modern cloud-native ELT (Extract, Load, Transform) loads raw data directly into scalable cloud data warehouses first, leveraging their massive computing power to handle transformations efficiently.
10. What is data observability?
Data observability is the continuous monitoring of data health and pipeline performance. It tracks metrics like data freshness, volume changes, schema variations, and execution logs, helping engineering teams catch and fix data anomalies before they impact business reports.
11. How does CI/CD apply to data engineering?
CI/CD brings software engineering discipline to data workflows. Continuous Integration (CI) automatically tests data scripts for syntax errors and logic bugs whenever code is changed. Continuous Deployment (CD) pushes approved updates to production environments smoothly without manual intervention.
12. What is data lineage?
Data lineage is the comprehensive visual mapping of data’s complete journey across an organization. It tracks exactly where data originates, what transformations it undergoes, and which downstream business intelligence dashboards and reports consume it.
13. How do you secure automated data pipelines?
Data pipelines are secured by using dedicated secret management tools to encrypt access credentials, implementing strict identity and access management (IAM) rules, using automated data masking to protect sensitive information, and maintaining comprehensive audit logs.
14. What is a directed acyclic graph (DAG)?
A DAG is a conceptual collection of all the tasks that make up a data pipeline, organized to show the explicit dependencies and structural relationships between them. It defines the exact sequence in which tasks must run and guarantees that processes move forward without infinite loops.
15. Why is data validation important?
Automated data validation prevents bad, corrupted, or incomplete information from entering your production systems. By checking data quality at the ingestion gate, you ensure downstream business intelligence dashboards stay accurate and reliable.
Final Thoughts
The rapid growth of automated analytics workflows is reshaping how organizations operate, moving businesses away from slow, manual processes toward fast, data-driven execution. As data volumes continue to increase, companies must automate their pipelines to keep their analytics reliable, scalable, and secure. babysitting data workflows manually is no longer a sustainable option for modern enterprises.
For aspiring data professionals, this shift highlights the importance of gaining hands-on experience with cloud infrastructure and pipeline orchestration. The long-term career opportunities in data engineering remain strong, and the industry demand for skilled DataOps professionals who understand how to build resilient, automated systems will continue to grow. Focus on mastering foundational engineering principles, build real projects, and approach automation with a structured, practical mindset to build a successful career in this evolving landscape.